标签:默认 inf http 复数 指定 bubuko 分享 als taf
import pandas as pd # 生成重复数据 data1 = [‘a‘, 3] data2 = [‘b‘, 2] data3 = [‘a‘, 3] data4 = [‘c‘, 2] df = pd.DataFrame([data1, data2, data3, data4], columns = [‘col1‘, ‘col2‘]) print(df)

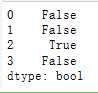
# 判断重复数据 isDuplicated = df.duplicated() # 判断重复数据记录 print(isDuplicated) # 打印输出
# 删除重复值 new_df1 = df.drop_duplicates() # 删除数据记录中所有列值相同的记录 new_df2 = df.drop_duplicates([‘col1‘]) # 删除数据记录中col1值相同的记录 new_df3 = df.drop_duplicates([‘col2‘]) # 删除数据记录中col2值相同的记录 new_df4 = df.drop_duplicates([‘col1‘, ‘col2‘]) # 删除数据记录中指定列(col1/col2)值相同的记录 print(new_df1) print(new_df2) print(new_df3) print(new_df4)

判断重复数据的判断方法:df.duplicated(),该方法中两个主要的参数是subset和keep:
删除重复数据的方法:df.drop_duplicates(),参数跟df.duplicated()一样。
Numpy重复值的判断
除了Pandas可用来做重复值判断和处理外,也可以使用Numpy中的unique()方法,该方法返回其参数数组中所有不同的值,并且按照从小到大的顺序排列。Python自带的内置函数set方法,也可以返回唯一元素的集合。
标签:默认 inf http 复数 指定 bubuko 分享 als taf
原文地址:https://www.cnblogs.com/keye/p/8893325.html