标签:发送 rap span 项目 验证 加载 val 增加 nis
手头的项目使用TCP协议传输实时非压缩视频流,需要很大的带宽,但我们的程序只能达到400Mb,使用iperf工具测试却可以达到700Mb以上。
由于项目采用QT作为底层库,初步怀疑QT封装socket操作导致效率降低,写了一个简单的测试程序用于验证。
#ifndef TCPSERVER_H #define TCPSERVER_H #include <QObject> #include <QThread> class QTcpServer; class QTcpSocket; class tcpserver : public QObject { Q_OBJECT public: explicit tcpserver(QObject *parent = 0); signals: void transmit(); public slots: void handleNewConnection(); void onSocketRead(); void onSocketWritten(qint64 bytes); void onSocketConnected(); void onSocketDisconnected(); void doTransmit(); private: //socket QTcpSocket *mSocket; QTcpServer *mTcpServer; QThread *mThread; QByteArray *mData; qintptr mSD; }; #endif // TCPSERVER_H
#include "tcpserver.h" #include <QTcpSocket> #include <QTcpServer> #include <unistd.h> #include <QThreadPool> class TransmitThread : public QRunnable { public: TransmitThread(QTcpSocket *sock) {mSocket = sock;} void run(){ QByteArray dataBuff(900*1024,‘H‘); qintptr sd = mSocket->socketDescriptor(); while (true) { int sent = ::write(sd,dataBuff.data(),dataBuff.size()); // if(sent != dataBuff.size()){ // qInfo() << "sent" << sent << "/" <<dataBuff.size(); // } if(sent < 0){ QThread::msleep(5); } } // while (true) { // if (mSocket->bytesToWrite() > 1000000) continue; // int sent = mSocket->write(dataBuff); // qInfo() << "sent" << sent << "/" <<dataBuff.size(); // QThread::sleep(1); // mSocket->waitForBytesWritten(); // } } private: QTcpSocket *mSocket; }; tcpserver::tcpserver(QObject *parent) : QObject(parent) { mData = new QByteArray(900*1024,‘H‘); mTcpServer = new QTcpServer(); mSocket = nullptr; connect(mTcpServer, &QTcpServer::newConnection, this, &tcpserver::handleNewConnection); // connect(this, SIGNAL(transmit()), this, SLOT(doTransmit())); mTcpServer->listen(QHostAddress::Any, 5001); mThread = new QThread; moveToThread(mThread); mTcpServer->moveToThread(mThread); mThread->start(); } void tcpserver::handleNewConnection() { QTcpSocket *newSocket = mTcpServer->nextPendingConnection(); if (nullptr != mSocket && (mSocket->state() == QAbstractSocket::ConnectedState || mSocket->state() == QAbstractSocket::ConnectingState )) { //reject new connection. qInfo() << "reject new connection"; newSocket->disconnectFromHost(); delete newSocket; return; } qInfo() << newSocket->peerAddress().toString().split(":").last() << " connected!"; if (nullptr != mSocket) { delete mSocket; mSocket = nullptr; } mSocket = newSocket; mSD = mSocket->socketDescriptor(); connect(mSocket, &QTcpSocket::connected, this, &tcpserver::onSocketConnected); connect(mSocket, &QTcpSocket::disconnected, this, &tcpserver::onSocketDisconnected); connect(mSocket, &QTcpSocket::readyRead, this, &tcpserver::onSocketRead); connect(mSocket, &QTcpSocket::bytesWritten, this, &tcpserver::onSocketWritten); emit transmit(); TransmitThread * th = new TransmitThread(mSocket); QThreadPool::globalInstance()->start(th); } void tcpserver::onSocketRead() { QByteArray buffer = mSocket->readAll(); qInfo() << "received:" << buffer; } void tcpserver::onSocketWritten(qint64 bytes) { Q_UNUSED(bytes); emit transmit(); } void tcpserver::onSocketConnected() { qInfo() << "tcp onSocketConnected!"; emit transmit(); } void tcpserver::onSocketDisconnected() { qInfo() << "tcp onSocketDisconnected!"; } void tcpserver::doTransmit() { // int sent = mSocket->write(*mData); // while (true) { // int sent = ::write(mSD,mData->data(),mData->size()); // if(sent != mData->size()){ // qInfo() << "sent" << sent << "/" <<mData->size(); // } // } while (true) { if (mSocket->bytesToWrite() > 1000000) continue; int sent = mSocket->write(*mData); qInfo() << "sent" << sent << "/" <<mData->size(); mSocket->waitForBytesWritten(); } }
使用测试程序分别测试了异步发送、轮询发送等方式,最终确定使用native socket、采用轮询方式发送数据,可以达到和iperf工具相近的速率。
将上述方法应用于项目代码后,依然无法达到理想的数据速率,且CPU占用率高达95%以上。
怀疑CPU性能限制了数据发送速度,尝试用性能优化工具找到问题点,降低CPU负载。
1、编译选项增加-pg,重新编译工程,重新编译QT库。在此情况下gprof只能跟踪主线程,且无法提供c库函数执行情况。
2、使用预加载库gprof-helper.so增加对其他线程的监控,由于QT对线程进行了封装,结果并不理想。
1、使用valgrind --tool=callgrind --separate-threads program命令在设备上运行目标程序。
2、程序退出后会产生callgrind.out.pid文件,注意一定要程序正常退出才能产生正确的输出文件。
3、使用gprof2dot和graphivz生成调用关系图:gprof2dot -f callgrind ./callgrind.out.pid | dot -Tpng -o call_graph.png
4、通过分析调用关系及CPU使用率来找到性能瓶颈。下图是优化前后的对比:
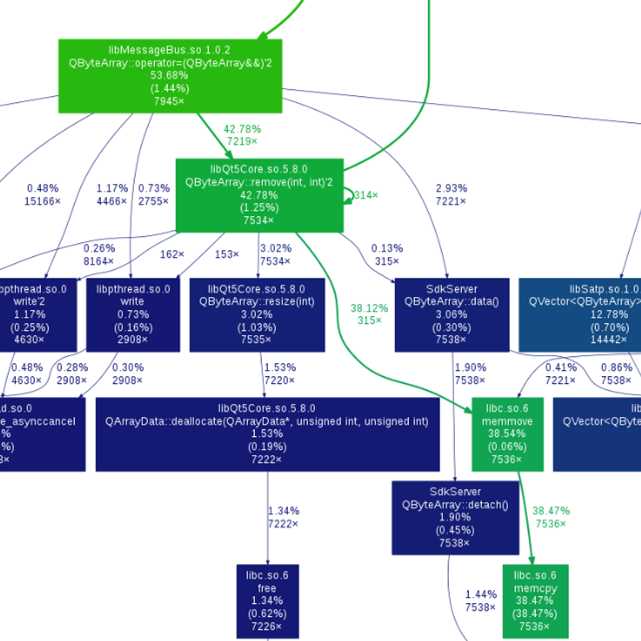
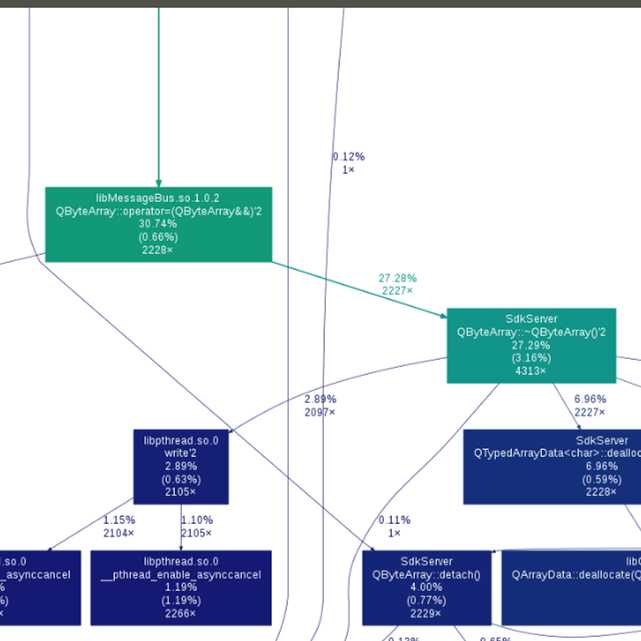
可以看到原来会产生memmove操作导致数据拷贝,优化后省掉了这些数据拷贝操作,从而提高系统性能。
valgrind真是太强大了,以前用它来找内存泄漏问题,系统优化功能依然强大,有时间再试试Cachegrind,期待更大的惊喜。
标签:发送 rap span 项目 验证 加载 val 增加 nis
原文地址:https://www.cnblogs.com/JeffreyLi75/p/8846602.html