标签:page 过多 设计 programs 链接 attrs ack turn white
1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
def writeNewsDetail(content): f = open(‘a9vg.txt‘,‘a‘,encoding=‘utf-8‘) f.write(content) f.close() def getNewsDetail(url): res2 = requests.get(url) res2.encoding = ‘utf-8‘ soup2 = BeautifulSoup(res2.text, ‘html.parser‘) news = {} news[‘content‘] = soup2.select(‘.art-ctn‘)[0].text # 爬取ps4专区新闻的正文 writeNewsDetail(news[‘content‘]) news[‘newsurl‘]=url return(news) def getListPage(pageUrl): res = requests.get(pageUrl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) newsList=[] for news in soup.select(‘.tab-ctn dl‘): if len(news.select(‘h3‘)) > 0: a = news.select(‘a‘)[0].attrs[‘href‘] print(a) newsList.append(getNewsDetail(a)) return(newsList)
3.对爬了的数据进行文本分析,生成词云。
def cutword(): text=‘‘ f = open(‘a9vg.txt‘, ‘r‘, encoding=‘utf8‘) lines = f.readlines() for line in lines: text += line for key in analyse.extract_tags(text, 50, withWeight=False): # 使用jieba.analyse.extract_tags()参数提取关键字,默认参数为50 print(key) jieba.add_word(‘奥丁‘) words_ls = jieba.cut(text) words_split = " ".join(words_ls) print(words_ls) return words_split def wordspic(): wordsp=cutword() Stopwords = [‘programs‘,‘view‘,‘tudou‘,‘www‘,‘http‘,‘com‘,‘https‘,‘qq‘,‘page‘,‘杀死‘,‘渡鸦‘] wc = WordCloud() # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框 wc.stopwords=Stopwords wc.max_words=200 wc.background_color=‘white‘ wc.font_path="simhei.ttf" # 黑体 my_wordcloud = wc.generate(wordsp) plt.imshow(my_wordcloud) plt.axis("off") plt.show() wc.to_file(‘ttt.png‘) # 保存图片文件
4.对文本分析结果进行解释说明。
通过使用第三方的jieba库进行中文分词,其中有过多新闻正文内容包含视频链接,所以通过设计了停用词,去掉一些词
关键词如下
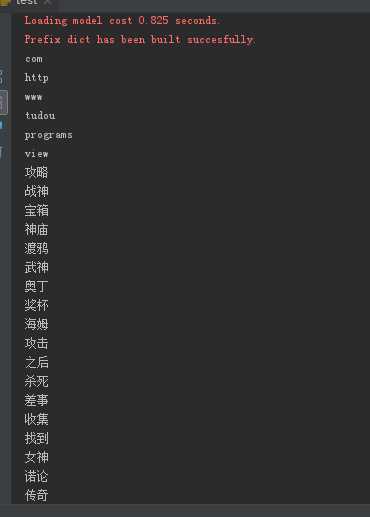
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
在进行下载安装第三方的库的时候,wordcloud下载失败,查了各种问题最后通过https://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站下载对应py版本对应系统位数的库进行安装。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
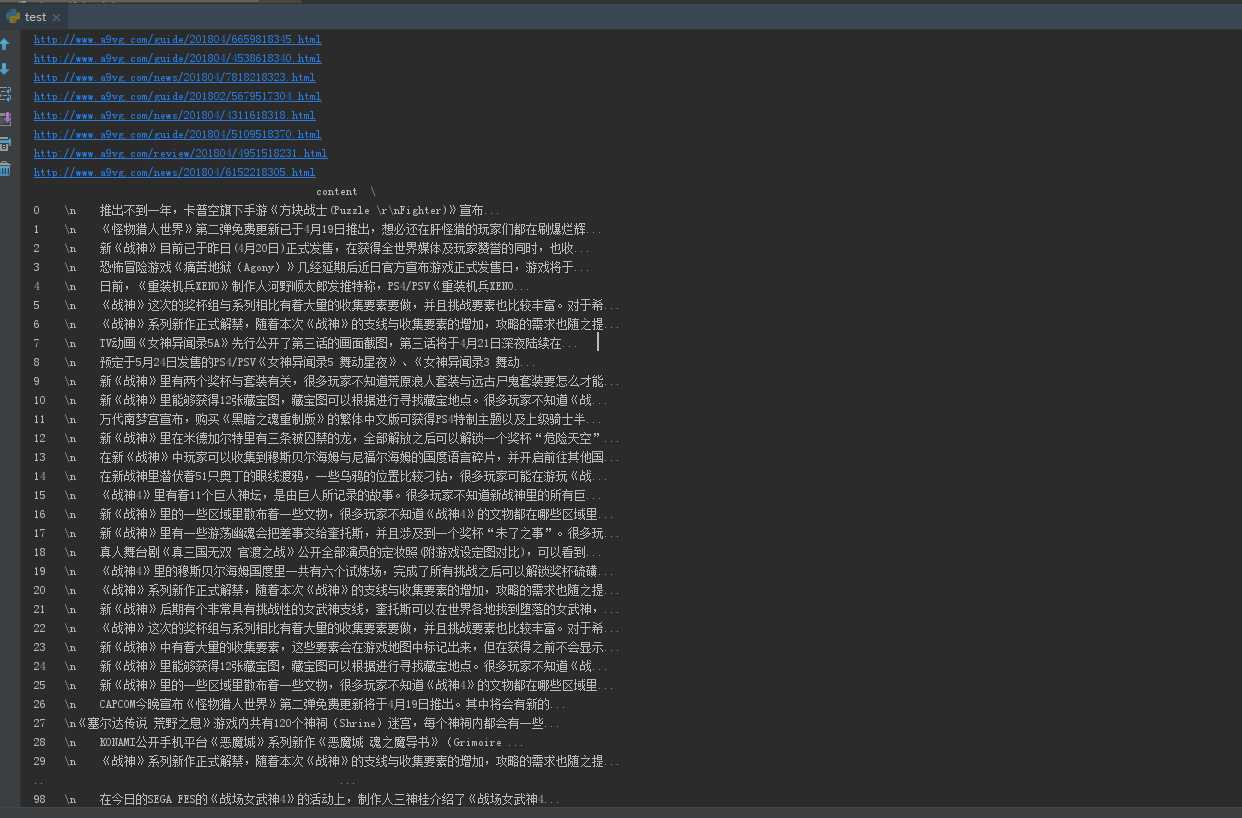
爬取的链接,内容如下(使用了pandas这个库进行输出到控制台)
词云如下:

标签:page 过多 设计 programs 链接 attrs ack turn white
原文地址:https://www.cnblogs.com/yxbdbolgs/p/8910322.html