标签:style blog http io 使用 java ar 文件 数据
一、针对《写在前面》的补充
随着对需求的深入了解,最后抛弃了使用trie树,一是这个数据结构不利于处理大小写敏感的问题,二是最后的排序首先是由出现的次数排的,需要对此树进行遍历也不方便编码,遂弃之。
二、时间
完成文件读取:20分钟
正则匹配:1个小时
频率分析:4个小时
模式二三:2个小时
调试与优化:1个小时
三、代码部分解析
1.文件读取
在网上搜到了c#语法中的一个方法,能够将某个目录下所有的文件建立一个字符串数组,如果在加上linq的使用,可以免去写递归算法,只需要用一个语句就能把目录中满足要求的文件全部找到,由于是第一次写c#的程序,对linq相关的用法还需要多学习,这里就不卖弄了。
2.正则匹配
这个我是参考班上同学的匹配写的,也是我第一次在字符串处理中使用正则表达式,记得上学期面向对象写Java的时候,对命令要求都是嵌套很多if去写的,过去的天真亦不敢想= =
3.频率分析
决定不用trie树以后,自然想用到c#的hashtable或者dictionary,http://blog.163.com/jeson_lwj/blog/static/13576108320101187546107/ 参考此文后选择了dictionary(也就是说,并没有实现多线程),还有一个sorted dictionary,我留在优化的时候来说这个问题。
dictionary由<key,value>这个二元组完成每一项的构建,从本次作业的需求来讲,对于每一个单词需要存储的不仅仅是它出现的次数,还有其已经出现过的ascii码最靠前的形式,刚开始的时候我是用两个dictionary实现的,完成创建以后首先对存有次数的dictionary进行排序,之后在对应的第二个dictionary中找到正确的形式,后来发现定义中的value是个object,想到能否用一个class的对象作为value,就只需要一个dictionary了。代码便是如此实现的。排序仍然是用的c#的新语法,这都是本次项目完后我需要重点详细学习的部分。
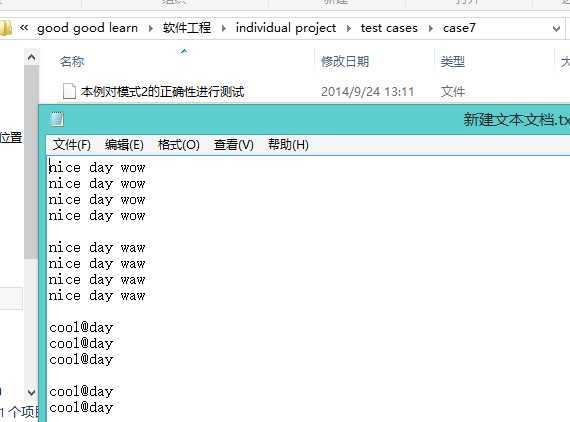
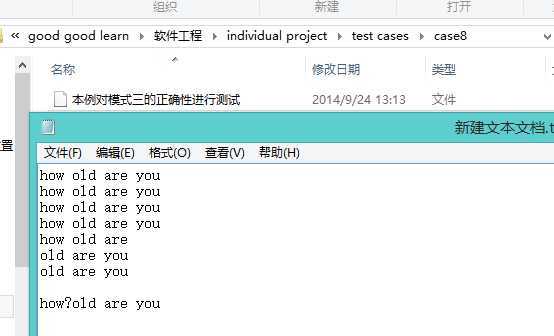
4.模式二三
主要思路就是将词组当成一个匹配模式进行匹配,下一次匹配在当前匹配的index基础上加上空格出现的地方,以两个单词的为例:对于how are you这三个词,首先得到how are这个正确的匹配,将其加入dictionary,使匹配的起始位置从a开始继续匹配,这时可以找到are you这个匹配,这应该就是模式二三比模式一需要多做的事情了。这一段代码需要对正则regex的方法很熟捻,感谢高哥的帮助。
5.调试与优化
a.刚才提到了sorted dictionary,开始想到有一个按字典序输出的要求,就用了对key自然有序的sorted dictionary,但是程序跑得非常慢,还是用了简单的dictionary,排序就在后面用代码实现了,其实也就是一行代码。
b.讲一个细节,在一个if循环里面,会交替用到一个单词的原型和它的小写形式,我在最开始写的时候每次用小写就会调用一次ToLower()方法,优化的时候用一个新的String先把小写存起来,不再频繁调用方法,直观来看,在模式一下,程序快了3秒(针对一个36MB大小的测试用例)
四、test cases
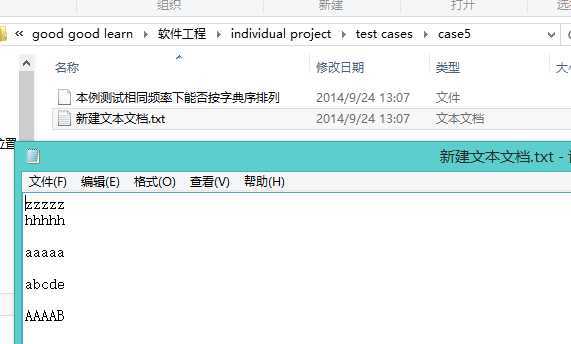
分别对空文件、空目录,各边界值进行了测试,测试用例都很简单,因此不再详细地贴出测试用例了,值得说明的是在测试时发现了下划线的问题,这还是应归到正则表达式的学习上,也不再赘述了。
五、性能分析:
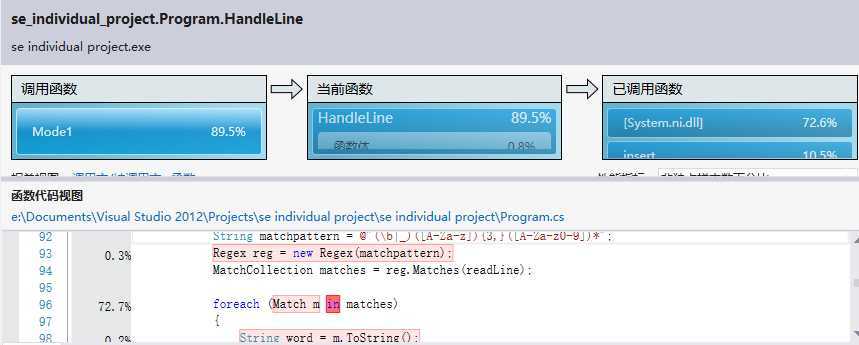
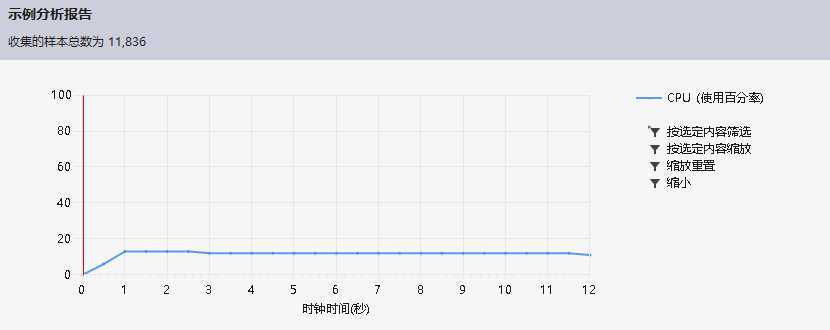
测试用例大小是一个36MB的txt文件夹(多个txt文件)
标签:style blog http io 使用 java ar 文件 数据
原文地址:http://www.cnblogs.com/code-dog-liou/p/3991718.html