标签:内容 format ... upd bsp def frame 过程 编辑
一、主题
2016年4月14日,在湖人巨星科比·布莱恩特退役战结束后,NBA豪门湖人队开启进入重建的脚步,
本人根据爬取虎扑湖人队NBA的新闻来进行数据分析,分析出湖人队重建的过程。
二、编写Python程序爬取相关数据
1.进入虎扑NBA湖人队的新闻首页后,首先选择一个新闻分析获取新闻的发布时间、来源、标题、
编辑、链接和内容并将这些数据放在字典news{}里面
def getNewDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = ‘utf-8‘
soupd = BeautifulSoup(resd.text, ‘html.parser‘)
news = {}
news[‘标题‘] = soupd.select(‘.headline‘)[0].text.strip()
info = soupd.select(‘.artical-info‘)[0].text
if info.find(‘来源:‘) > 0:
news[‘来源‘] = info[info.find(‘来源:‘):].split()[0].lstrip(‘来源:‘)
news[‘发布时间‘] = datetime.strptime(info.lstrip(‘ ‘)[-23:-1].strip(), ‘%Y-%m-%d %H:%M:%S‘)
news[‘编辑‘] = soupd.select(‘#editor_baidu‘)[0].text.strip(‘)‘).split(‘:‘)[1]
news[‘链接‘] = newsUrl
content = soupd.select(‘.artical-main-content‘)[0].text.strip()
writeNewsDetail(content)
return news
2.把每一页的所有新闻放在一个列表newslist里面
def getListPage(newsurl):
res = requests.get(newsurl)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
newslist = []
for new in soup.select(‘.list-content‘):
if len(new.select(‘.video‘)) > 0:
newsUrl = new.select(‘a‘)[0].attrs[‘href‘]
newslist.append(getNewDetail(newsUrl))
return newslist
3.以100页的新闻为例,将并获取的所有新闻列表存放在newsTotal里
for i in range(1,101):
listPageUrl = ‘https://voice.hupu.com/nba/tag/846-{}.html‘.format(i)
newsTotal.extend(getListPage(listPageUrl))
4.将获取到的新闻详情数据存放在Excel表里面
df = pandas.DataFrame(newsTotal) df[[‘发布时间‘,‘标题‘,‘来源‘,‘编辑‘,‘链接‘]] df.to_excel(‘gzcc.xlsx‘,encoding=‘utf-8‘)

5.将获取到新闻内容存放到content.txt中,并进行词频统计
def writeNewsDetail(content):
f = open(‘content.txt‘,‘a‘,encoding=‘utf-8‘)
f.write(content)
f.close()
f = open(‘content.txt‘, ‘r‘, encoding = ‘utf-8‘)
news = f.read()
f.close()
sep=‘‘‘,。‘’“”:;()!?、《》 ‘‘‘
exclude={‘ ‘,‘的‘,‘1‘,‘\n‘,‘2‘,‘在‘,‘我‘,‘了‘,‘他‘,‘-‘,‘3‘,‘到‘,‘一‘,‘是‘,‘0‘,‘们‘,‘个‘,‘上‘,‘中‘,‘4‘,‘5‘,
‘6‘,‘7‘,‘8‘,‘9‘,‘时‘,‘说‘,‘月‘,‘日‘,‘道‘,‘不‘,‘有‘,‘为‘,‘会‘,‘虎‘,‘(‘,‘\xa0‘,‘我们‘,‘)‘,‘编辑‘,‘扑‘,‘日讯‘
,‘特‘,‘季‘,‘对‘,‘以‘,‘前‘,‘后‘,‘员‘,‘马‘,‘拉‘,‘能‘,‘和‘,‘鲍‘,‘布‘,‘天‘,‘很‘,‘自‘,‘来‘,‘本‘,‘你‘,‘均‘,‘就‘,
‘德‘,‘发‘,‘要‘,‘11‘,‘年‘,‘他们‘,‘自己‘,‘现‘,‘那‘,‘12‘,‘好‘,‘兹‘,‘今日‘,‘说道‘,‘都‘,‘库兹‘,‘姆‘,‘今天‘,‘里‘,
‘顿‘,‘多‘,‘大‘,‘于‘,‘力‘,‘最‘,‘将‘,‘A‘,‘生‘,‘20‘,‘也‘,‘过‘,‘谈‘,‘受‘,‘B‘,‘接‘,‘常‘,‘进‘,‘下‘,‘格‘,‘小‘,
‘练‘,‘t‘,‘s‘,‘可‘,‘方‘,‘间‘,‘但‘,‘秀‘,‘当‘,‘么‘,‘者‘,‘做‘,‘看‘,‘更‘,‘名‘,‘想‘,‘此‘,‘朗‘,‘名‘,‘事‘,
‘之‘,‘成‘,‘第‘,‘经‘,‘没‘,‘胜‘,‘抢‘,‘人‘,‘10‘,‘场‘,‘赛‘,‘20‘,‘分‘,‘球‘,‘.‘,‘湖‘,‘比‘,‘尔‘,‘得‘,‘篮‘,
‘这‘,‘斯‘,‘出‘,‘板‘,‘得到‘,‘队‘,‘打‘,‘战‘,‘投‘,‘新‘,‘次‘,‘些‘,‘英‘,‘与‘,‘谈到‘,‘一个‘,‘并‘,‘格拉‘,‘至‘,
‘13‘,‘三‘,‘位‘,‘本赛季‘,‘接受‘,‘所‘,‘洛‘,‘人球‘,‘让‘,‘感恩‘,‘湖人球‘,‘还‘,‘如‘,‘利‘,‘采访‘,‘就是‘,‘记‘,
‘据‘,‘凯‘,‘因‘,‘开‘,‘手‘,‘去‘,‘行‘,‘写‘,‘防‘,‘加‘,‘m‘,‘16‘,‘时间‘,‘森‘,‘德尔‘,‘托‘,‘可以‘,‘同‘,‘写道‘,
‘哈‘,‘着‘,‘问‘,‘推‘,‘没有‘,‘训‘,‘守‘,‘记者‘,‘本场‘,‘被‘,‘首‘,‘总‘,‘起‘,‘交‘,‘图‘,‘作‘,‘报‘,‘时候‘,‘布莱恩‘,
‘19‘,‘15‘,‘而‘,‘已‘,‘约‘,‘心‘,‘及‘,‘明‘,‘威‘,‘非‘,‘回‘,‘01‘,‘够‘,‘14‘,‘尼‘,‘什么‘,‘杨‘,‘教‘,‘至今‘,
‘给‘,‘17‘,‘官‘,‘选‘,‘期‘,‘两‘,‘认为‘,‘非常‘,‘感‘,‘恩‘,‘莱‘,‘佐‘,‘表示‘,‘学‘,‘南‘,‘见‘,‘高‘,‘已经‘,‘合‘,
‘部‘,‘事情‘,‘全‘,‘卫‘,‘能够‘,‘努‘,‘快‘,‘点‘,‘身‘,‘面‘,‘杨旭航‘,‘节‘,‘知道‘,‘从‘,‘每‘,‘30‘,‘一些‘,‘其‘,
‘发布‘,‘子‘,‘家‘,‘西‘,‘张‘,‘配‘,‘正‘,‘只‘,‘片‘,‘变‘,‘M‘,‘这是‘,‘很多‘,‘重‘,‘卡‘,‘现在‘,‘地‘,‘共‘,‘定‘,
‘25‘,‘个助‘,‘号‘,‘因为‘,‘如果‘,‘骑‘,‘27‘,‘一场‘,‘色‘,‘In‘,‘支‘,‘波‘,‘师‘,‘无‘,‘Instagram‘,‘一直‘,‘奥‘,
‘赢‘,‘像‘,‘影‘,‘太‘,‘需‘,‘火‘,‘但是‘,‘配图‘,‘湖人官‘,‘此前‘,‘21‘,‘23‘,‘00‘,‘话‘,‘对于‘,‘轻‘,‘连‘,‘糖‘,
‘应‘,‘提‘,‘希‘,‘一张‘,‘持‘,‘棒‘,‘真‘,‘22‘,‘这个‘,‘目前‘,‘式‘,‘感觉‘,‘进行‘,‘星‘,‘所以‘,‘数‘,‘论‘,‘达‘,
‘罗‘,‘长‘,‘近‘,‘不会‘,‘视‘,‘29‘,‘一名‘,‘亚‘,‘安‘,‘信‘,‘随‘,‘#‘,‘34‘,‘T‘,‘曾‘,‘金‘,‘奇‘,‘31‘,‘史‘,‘内‘,
‘36‘,‘帮‘,‘这些‘,‘以及‘,‘用‘,‘晚‘,‘不是‘,‘二‘,‘丹‘,‘北京‘,‘外‘,‘夏‘,‘敌‘,‘可能‘,‘朱‘,‘33‘,‘失‘,‘28‘,‘老‘,
‘排‘,‘热‘,‘难‘,‘度‘,‘称‘,‘李‘,‘继‘,‘26‘,‘雷‘,‘18‘,‘周‘,‘这样‘,‘照‘,‘巴‘,‘美‘,‘理‘,‘北‘,‘步‘,‘双‘,‘杰‘,‘别‘,
‘才‘,‘性‘,‘岁‘,‘单‘,‘@‘,‘缺‘,‘由‘,‘亲‘,‘...‘,‘完‘,‘且‘,‘向‘,‘活‘,‘平‘,‘席‘,‘这一‘,‘根据‘,‘a‘,‘周晓翔‘}
jieba.add_word(‘英格拉姆‘)
jieba.add_word(‘约翰逊‘)
jieba.add_word(‘难度‘)
jieba.add_word(‘夏季联赛‘)
jieba.add_word(‘上篮‘)
jieba.add_word(‘赛场‘)
jieba.add_word(‘佩林卡‘)
jieba.add_word(‘比尔‘)
jieba.add_word(‘尼克扬‘)
jieba.add_word(‘南斯‘)
jieba.add_word(‘小南斯‘)
jieba.add_word(‘拉塞尔‘)
jieba.add_word(‘克拉克‘)
jieba.add_word(‘克拉克森‘)
jieba.add_word(‘波普‘)
jieba.add_word(‘布鲁尔‘)
jieba.add_word(‘莱佐‘)
jieba.add_word(‘波波维奇‘)
jieba.add_word(‘湖人官宣‘)
for c in sep:
news = news.replace(c,‘ ‘)
wordList=list(jieba.cut(news))
wordDict={}
words=list(set(wordList)-exclude)
for w in range(0,len(words)):
wordDict[words[w]]=news.count(str(words[w]))
dictList = list(wordDict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
cy={}
f = open(‘number.txt‘, ‘a‘,encoding="utf-8")
for i in range(1000):
print(dictList[i])
f.write(dictList[i][0] + ‘:‘ + str(dictList[i][1]) + ‘\n‘)
cy[dictList[i][0]]=dictList[i][1]
f.close()
font=r‘C:\Windows\Fonts\simhei.TTF‘
image = Image.open(‘./ball1.png‘)
graph = np.array(image)
wc = WordCloud(font_path=font,background_color=‘White‘,max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
三、对数据进行文本分析,生成词云
1.通过词频统计,删除一些没有参考价值的词语和标点符号之后,生成字典,利用生成该字典生成词云
font=r‘C:\Windows\Fonts\simhei.TTF‘
image = Image.open(‘./ball1.png‘)
graph = np.array(image)
wc = WordCloud(font_path=font,background_color=‘White‘,max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()


四、遇到的问题及解决办法
1.在对爬取到的新闻详情到处到Excel表时,运行程序的时候,出现了以下错误:
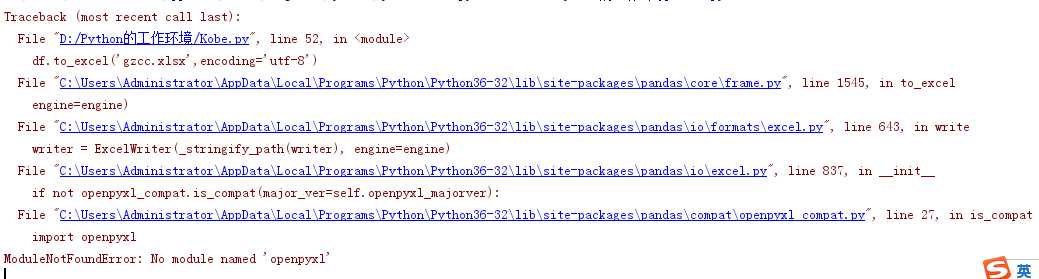
解决方法:导入modul ‘openpyxl’就可以解决以上问题
2.在导入wordcloud的时候,会出现以下错误:

解决办法:经过分析,发现本人电脑的Python版本是3.6.4,32位的,而刚开始装的是64位的,在网上下载32位
并重新安装之后级可以解决以上问题
五、数据分析及结论
通过分析,我们可以清楚的看到,现在湖人队在重建过程中,主要是以沃顿教练为主体,并对库兹马、英格拉姆、
鲍尔、兰德尔等一众年轻的球员进行大力培养,因为这些都还是一些新秀球员,通过这些数据可以看出这些球员是很
有天赋并且愿意付出努力的,并且在数据方面也是很不错的,所以湖人队在科比退役之后,通过选秀球员来进行重建
得到很不错的效果,相信在未来几年之内,昔日的NBA霸主湖人将会再次叱咤联盟。
六、源代码
from datetime import datetime
import requests
from bs4 import BeautifulSoup
import pandas
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
def writeNewsDetail(content):
f = open(‘content.txt‘,‘a‘,encoding=‘utf-8‘)
f.write(content)
f.close()
def getNewDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = ‘utf-8‘
soupd = BeautifulSoup(resd.text, ‘html.parser‘)
news = {}
news[‘标题‘] = soupd.select(‘.headline‘)[0].text.strip()
info = soupd.select(‘.artical-info‘)[0].text
if info.find(‘来源:‘) > 0:
news[‘来源‘] = info[info.find(‘来源:‘):].split()[0].lstrip(‘来源:‘)
news[‘发布时间‘] = datetime.strptime(info.lstrip(‘ ‘)[-23:-1].strip(), ‘%Y-%m-%d %H:%M:%S‘)
news[‘编辑‘] = soupd.select(‘#editor_baidu‘)[0].text.strip(‘)‘).split(‘:‘)[1]
news[‘链接‘] = newsUrl
content = soupd.select(‘.artical-main-content‘)[0].text.strip()
writeNewsDetail(content)
return news
newsurl = ‘https://voice.hupu.com/nba/tag/846‘
def getListPage(newsurl):
res = requests.get(newsurl)
res.encoding = ‘utf-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
newslist = []
for new in soup.select(‘.list-content‘):
if len(new.select(‘.video‘)) > 0:
newsUrl = new.select(‘a‘)[0].attrs[‘href‘]
newslist.append(getNewDetail(newsUrl))
return newslist
newsTotal = []
for i in range(1,101):
listPageUrl = ‘https://voice.hupu.com/nba/tag/846-{}.html‘.format(i)
newsTotal.extend(getListPage(listPageUrl))
for news in newsTotal:
print(news)
df = pandas.DataFrame(newsTotal)
df[[‘发布时间‘,‘标题‘,‘来源‘,‘编辑‘,‘链接‘]]
df.to_excel(‘gzcc.xlsx‘,encoding=‘utf-8‘)
f = open(‘content.txt‘, ‘r‘, encoding = ‘utf-8‘)
news = f.read()
f.close()
sep=‘‘‘,。‘’“”:;()!?、《》 ‘‘‘
exclude={‘ ‘,‘的‘,‘1‘,‘\n‘,‘2‘,‘在‘,‘我‘,‘了‘,‘他‘,‘-‘,‘3‘,‘到‘,‘一‘,‘是‘,‘0‘,‘们‘,‘个‘,‘上‘,‘中‘,‘4‘,‘5‘,
‘6‘,‘7‘,‘8‘,‘9‘,‘时‘,‘说‘,‘月‘,‘日‘,‘道‘,‘不‘,‘有‘,‘为‘,‘会‘,‘虎‘,‘(‘,‘\xa0‘,‘我们‘,‘)‘,‘编辑‘,‘扑‘,‘日讯‘
,‘特‘,‘季‘,‘对‘,‘以‘,‘前‘,‘后‘,‘员‘,‘马‘,‘拉‘,‘能‘,‘和‘,‘鲍‘,‘布‘,‘天‘,‘很‘,‘自‘,‘来‘,‘本‘,‘你‘,‘均‘,‘就‘,
‘德‘,‘发‘,‘要‘,‘11‘,‘年‘,‘他们‘,‘自己‘,‘现‘,‘那‘,‘12‘,‘好‘,‘兹‘,‘今日‘,‘说道‘,‘都‘,‘库兹‘,‘姆‘,‘今天‘,‘里‘,
‘顿‘,‘多‘,‘大‘,‘于‘,‘力‘,‘最‘,‘将‘,‘A‘,‘生‘,‘20‘,‘也‘,‘过‘,‘谈‘,‘受‘,‘B‘,‘接‘,‘常‘,‘进‘,‘下‘,‘格‘,‘小‘,
‘练‘,‘t‘,‘s‘,‘可‘,‘方‘,‘间‘,‘但‘,‘秀‘,‘当‘,‘么‘,‘者‘,‘做‘,‘看‘,‘更‘,‘名‘,‘想‘,‘此‘,‘朗‘,‘名‘,‘事‘,
‘之‘,‘成‘,‘第‘,‘经‘,‘没‘,‘胜‘,‘抢‘,‘人‘,‘10‘,‘场‘,‘赛‘,‘20‘,‘分‘,‘球‘,‘.‘,‘湖‘,‘比‘,‘尔‘,‘得‘,‘篮‘,
‘这‘,‘斯‘,‘出‘,‘板‘,‘得到‘,‘队‘,‘打‘,‘战‘,‘投‘,‘新‘,‘次‘,‘些‘,‘英‘,‘与‘,‘谈到‘,‘一个‘,‘并‘,‘格拉‘,‘至‘,
‘13‘,‘三‘,‘位‘,‘本赛季‘,‘接受‘,‘所‘,‘洛‘,‘人球‘,‘让‘,‘感恩‘,‘湖人球‘,‘还‘,‘如‘,‘利‘,‘采访‘,‘就是‘,‘记‘,
‘据‘,‘凯‘,‘因‘,‘开‘,‘手‘,‘去‘,‘行‘,‘写‘,‘防‘,‘加‘,‘m‘,‘16‘,‘时间‘,‘森‘,‘德尔‘,‘托‘,‘可以‘,‘同‘,‘写道‘,
‘哈‘,‘着‘,‘问‘,‘推‘,‘没有‘,‘训‘,‘守‘,‘记者‘,‘本场‘,‘被‘,‘首‘,‘总‘,‘起‘,‘交‘,‘图‘,‘作‘,‘报‘,‘时候‘,‘布莱恩‘,
‘19‘,‘15‘,‘而‘,‘已‘,‘约‘,‘心‘,‘及‘,‘明‘,‘威‘,‘非‘,‘回‘,‘01‘,‘够‘,‘14‘,‘尼‘,‘什么‘,‘杨‘,‘教‘,‘至今‘,
‘给‘,‘17‘,‘官‘,‘选‘,‘期‘,‘两‘,‘认为‘,‘非常‘,‘感‘,‘恩‘,‘莱‘,‘佐‘,‘表示‘,‘学‘,‘南‘,‘见‘,‘高‘,‘已经‘,‘合‘,
‘部‘,‘事情‘,‘全‘,‘卫‘,‘能够‘,‘努‘,‘快‘,‘点‘,‘身‘,‘面‘,‘杨旭航‘,‘节‘,‘知道‘,‘从‘,‘每‘,‘30‘,‘一些‘,‘其‘,
‘发布‘,‘子‘,‘家‘,‘西‘,‘张‘,‘配‘,‘正‘,‘只‘,‘片‘,‘变‘,‘M‘,‘这是‘,‘很多‘,‘重‘,‘卡‘,‘现在‘,‘地‘,‘共‘,‘定‘,
‘25‘,‘个助‘,‘号‘,‘因为‘,‘如果‘,‘骑‘,‘27‘,‘一场‘,‘色‘,‘In‘,‘支‘,‘波‘,‘师‘,‘无‘,‘Instagram‘,‘一直‘,‘奥‘,
‘赢‘,‘像‘,‘影‘,‘太‘,‘需‘,‘火‘,‘但是‘,‘配图‘,‘湖人官‘,‘此前‘,‘21‘,‘23‘,‘00‘,‘话‘,‘对于‘,‘轻‘,‘连‘,‘糖‘,
‘应‘,‘提‘,‘希‘,‘一张‘,‘持‘,‘棒‘,‘真‘,‘22‘,‘这个‘,‘目前‘,‘式‘,‘感觉‘,‘进行‘,‘星‘,‘所以‘,‘数‘,‘论‘,‘达‘,
‘罗‘,‘长‘,‘近‘,‘不会‘,‘视‘,‘29‘,‘一名‘,‘亚‘,‘安‘,‘信‘,‘随‘,‘#‘,‘34‘,‘T‘,‘曾‘,‘金‘,‘奇‘,‘31‘,‘史‘,‘内‘,
‘36‘,‘帮‘,‘这些‘,‘以及‘,‘用‘,‘晚‘,‘不是‘,‘二‘,‘丹‘,‘北京‘,‘外‘,‘夏‘,‘敌‘,‘可能‘,‘朱‘,‘33‘,‘失‘,‘28‘,‘老‘,
‘排‘,‘热‘,‘难‘,‘度‘,‘称‘,‘李‘,‘继‘,‘26‘,‘雷‘,‘18‘,‘周‘,‘这样‘,‘照‘,‘巴‘,‘美‘,‘理‘,‘北‘,‘步‘,‘双‘,‘杰‘,‘别‘,
‘才‘,‘性‘,‘岁‘,‘单‘,‘@‘,‘缺‘,‘由‘,‘亲‘,‘...‘,‘完‘,‘且‘,‘向‘,‘活‘,‘平‘,‘席‘,‘这一‘,‘根据‘,‘a‘,‘周晓翔‘}
jieba.add_word(‘英格拉姆‘)
jieba.add_word(‘约翰逊‘)
jieba.add_word(‘难度‘)
jieba.add_word(‘夏季联赛‘)
jieba.add_word(‘上篮‘)
jieba.add_word(‘赛场‘)
jieba.add_word(‘佩林卡‘)
jieba.add_word(‘比尔‘)
jieba.add_word(‘尼克扬‘)
jieba.add_word(‘南斯‘)
jieba.add_word(‘小南斯‘)
jieba.add_word(‘拉塞尔‘)
jieba.add_word(‘克拉克‘)
jieba.add_word(‘克拉克森‘)
jieba.add_word(‘波普‘)
jieba.add_word(‘布鲁尔‘)
jieba.add_word(‘莱佐‘)
jieba.add_word(‘波波维奇‘)
jieba.add_word(‘湖人官宣‘)
for c in sep:
news = news.replace(c,‘ ‘)
wordList=list(jieba.cut(news))
wordDict={}
words=list(set(wordList)-exclude)
for w in range(0,len(words)):
wordDict[words[w]]=news.count(str(words[w]))
dictList = list(wordDict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
cy={}
f = open(‘number.txt‘, ‘a‘,encoding="utf-8")
for i in range(1000):
print(dictList[i])
f.write(dictList[i][0] + ‘:‘ + str(dictList[i][1]) + ‘\n‘)
cy[dictList[i][0]]=dictList[i][1]
f.close()
font=r‘C:\Windows\Fonts\simhei.TTF‘
image = Image.open(‘./ball1.png‘)
graph = np.array(image)
wc = WordCloud(font_path=font,background_color=‘White‘,max_words=50, mask=graph)
wc.generate_from_frequencies(cy)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
标签:内容 format ... upd bsp def frame 过程 编辑
原文地址:https://www.cnblogs.com/cgq520/p/8922465.html