标签:提交 作业 不能 director 关闭 http 列表 else open
1.爬取豆瓣电影top250。(所有同学不能雷同)
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
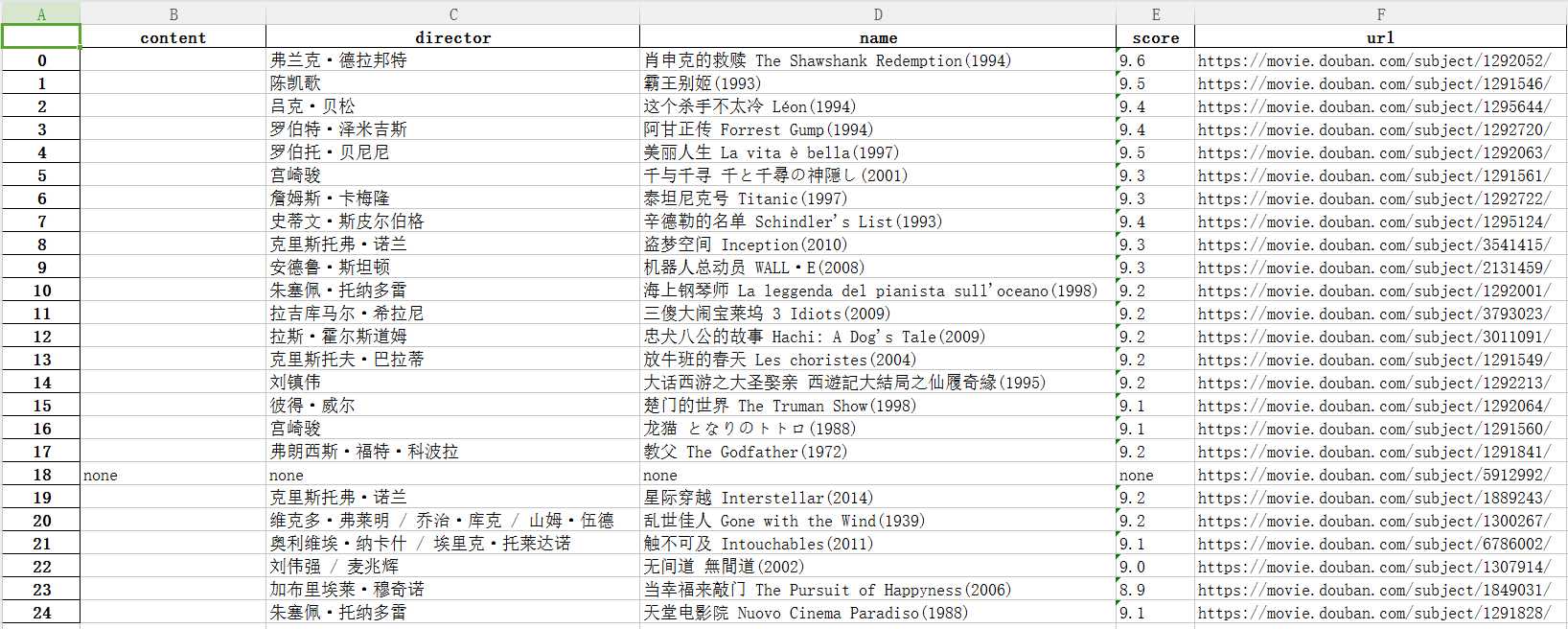
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas # 电影简介保存到txt。 def writeNewsDetail(content): f = open(‘wzh.txt‘, ‘a‘,encoding=‘utf-8‘)#文件名、打开方式 f.write(content)#写入 f.close()#关闭文件 #电影的简介 def getMovieDetail(url): resd = requests.get(url) resd.encoding = ‘utf-8‘ soupd = BeautifulSoup(resd.text, ‘html.parser‘) movies={} if (int(len(soupd.select(‘#link-report‘))) > 0): movies[‘content‘] = soupd.select(‘#link-report‘)[0].text else: movies[‘content‘] =‘none‘ if (int(len(soupd.select(‘.attrs‘))) > 0): movies[‘director‘] = soupd.select(‘.attrs‘)[0].text else: movies[‘director‘]=‘none‘ if (int(len(soupd.select(‘.actor a‘))) > 0): movies[‘actor‘] = soupd.select(‘.actor a‘)[0].text else: movies[‘actor‘] = ‘none‘ if(int(len(soupd.select(‘h1‘)))>0): movies[‘name‘]=soupd.select(‘h1‘)[0].text else: movies[‘name‘] = ‘none‘ if(int(len(soupd.select(‘strong‘))) > 0): movies[‘score‘] = soupd.select(‘strong‘)[0].text else: movies[‘score‘] =‘none‘ movies[‘url‘] = url return (movies) # 电影列表页的总页数 def getPageN(url): res = requests.get(url) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘html.parser‘) #num = soup.select(‘.paginator a‘)[-2].text print(‘列表页数:‘,num) #一个列表页全部电影 def getListPage(url): res = requests.get(url) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘html.parser‘) moviesList = [] urls = soup.select(‘.hd a‘) # for i in range(10): # if(i==0) # urls=‘htthttps://movie.douban.com/top250?start=25&filter=‘ for j in range(int(len(urls))): url = soup.select(‘.hd a‘)[j].attrs[‘href‘] moviesList.append(getMovieDetail(url))#在列表末尾添加新的对象 return (moviesList) moviesTotal = [] Url = ‘https://movie.douban.com/top250?start=0&filter=‘ moviesTotal.extend(getListPage(Url)) # 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) getPageN(Url) dt =pandas.DataFrame(moviesTotal) dt.to_excel("wzh.xlsx") print(dt)
3.对爬了的数据进行文本分析,生成词云。
import jieba.analyse from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator lyric= ‘‘ f=open(‘wzh.txt‘,‘r‘,encoding=‘utf-8‘) for i in f: lyric+=f.read() result=jieba.analyse.textrank(lyric,topK=50,withWeight=True) keywords = dict() for i in result: keywords[i[0]]=i[1] print(keywords) image= Image.open(‘tim.png‘) graph = np.array(image) wc = WordCloud(font_path=‘./fonts/simhei.ttf‘,background_color=‘Green‘,max_words=50,mask=graph) wc.generate_from_frequencies(keywords) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.imshow(wc.recolor(color_func=image_color)) plt.axis("off") plt.show() wc.to_file(‘dream.png‘)
4.对文本分析结果进行解释说明。
对于爬虫结果,我们可以看出评分高的电影有哪些类型,哪些导演的电影作品比较好看,哪些演员演得电影比较出名,哪些年代的电影比较受欢迎
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
问题:没有爬出完整的top250de 电影,使用for循环,10个列表页逐个提取
PyCharm中导入wordcloud是出错,没生成词云统计图

6.最后提交爬取的全部数据、爬虫及数据分析源代码。



标签:提交 作业 不能 director 关闭 http 列表 else open
原文地址:https://www.cnblogs.com/BOBOWZH/p/8928993.html