非常基本的说明,下面一张图就能够有基本的理解:
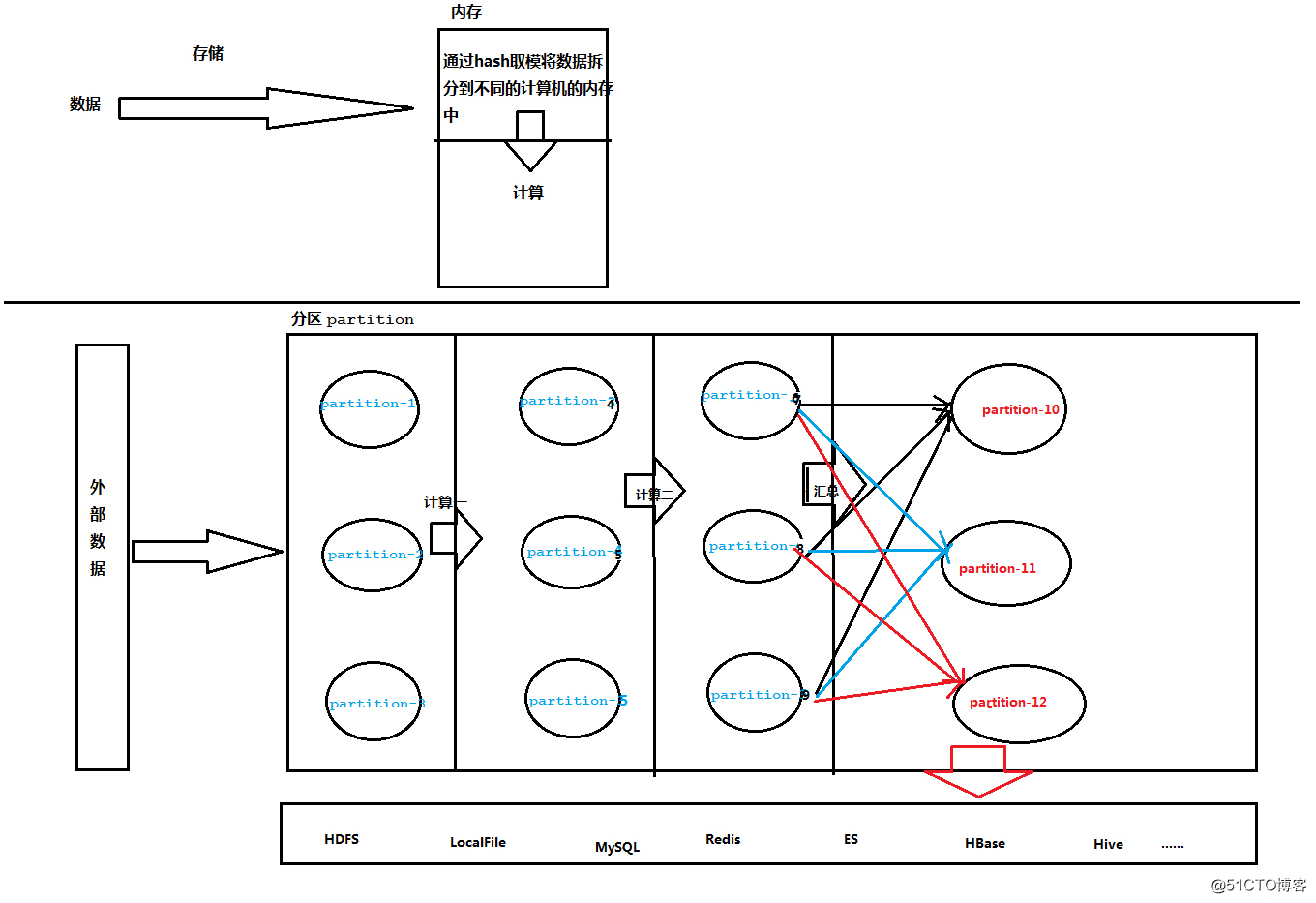
1、Spark的核心概念是RDD (resilient distributed dataset,弹性分布式数据集),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
2、RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同Worker节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
3、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过RDD的本地创建转换而来。
4、传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作(每跑完一个Job,拿到其中间结果后,再跑下一个Job,联想使用MR做数据清洗的案例)。RDD正是解决这一缺点的抽象方法。RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。RDD的lineage特性(类似于族谱,像上面的图,假如某个partition的数据丢失了,找到其父partition重新计算即可,我称之为溯源)。
5、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
(1)为什么会有Spark?因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2)Spark如何解决迭代计算?其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。(一行搞定wc:sc.textFile("./hello").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println),这就是典型的迭代计算了)
(3)Spark如何实现交互式计算?因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4)Spark和RDD的关系?可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现。
1、核心模块开发:离线批处理 Spark Core
2、实时计算:底层也是基于RDD Spark Streaming
3、Spark SQL/Hive:交互式分析
4、Spark Graphx:图计算
5、Spark Mlib: 数据挖掘和机器学习 大多数应该都要实地写过spark程序和提交任务到spark集群后才有更好的理解。
原文地址:http://blog.51cto.com/xpleaf/2107774