标签:int() pen 原因 3.1.1 lib 逻辑 分割文件 inpu 第一个
os模块
os模块,没什么好解释的,就是与操作系统交互的一个接口,里面的功能能用就用

‘‘‘
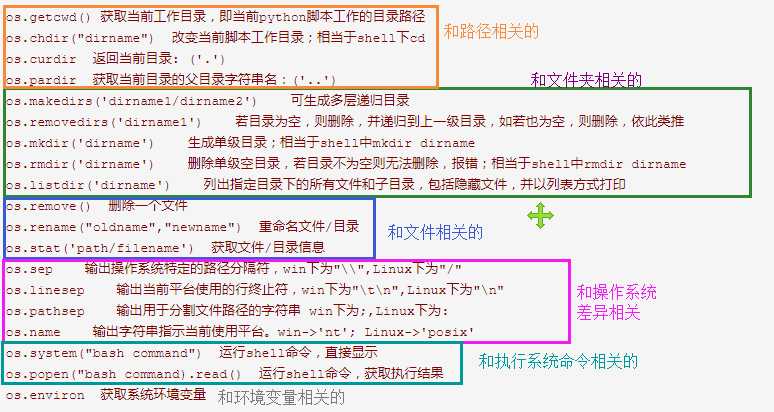
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.environ 获取系统环境变量
os.path
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
‘‘‘
注意:os.stat(‘path/filename‘) 获取文件/目录信息 的结构说明(这里打开合上就再打不开了???好像遇到个未知的bug)

stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
关于import我认为值得注意的有以下几点:
1、导包只会导一次
2、导包或者导包中的一个变量(函数)时,都会吧包中的程序先走一遍
3、导包时,包中的名字不会跟全局变量冲突,除非你用归一化设计
4、不要给包起名与你知道的内置函数相同(要是事先不知道的话肯定是用不到的)
5、PEP8规范:
(1):每一行应该导入一个模块
(2):导入的模块的顺序应为:内置模块、扩展模块、自己写的模块
(3):如果不是必须的要求,每个模块都应该在文件的开头进行导入
我认为老师讲的内容基本可以概括为这些。下面继续搬运
示例文件:自定义模块my_module.py,文件名my_module.py,模块名my_module

#my_module.py
print(‘from the my_module.py‘)
money=1000
def read1():
print(‘my_module->read1->money‘,money)
def read2():
print(‘my_module->read2 calling read1‘)
read1()
def change():
global money
money=0
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句),如下
#demo.py import my_module #只在第一次导入时才执行my_module.py内代码,此处的显式效果是只打印一次‘from the my_module.py‘,当然其他的顶级代码也都被执行了,只不过没有显示效果. import my_module import my_module import my_module ‘‘‘ 执行结果: from the my_module.py ‘‘‘
我们可以从sys.modules中找到当前已经加载的模块,sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
#测试一:money与my_module.money不冲突 #demo.py import my_module money=10 print(my_module.money) ‘‘‘ 执行结果: from the my_module.py 1000 ‘‘‘
#测试二:read1与my_module.read1不冲突
#demo.py
import my_module
def read1():
print(‘========‘)
my_module.read1()
‘‘‘
执行结果:
from the my_module.py
my_module->read1->money 1000
‘‘‘
#测试三:执行my_module.change()操作的全局变量money仍然是my_module中的 #demo.py import my_module money=1 my_module.change() print(money) ‘‘‘ 执行结果: from the my_module.py 1 ‘‘‘
总结:首次导入模块my_module时会做三件事:
1.为源文件(my_module模块)创建新的名称空间,在my_module中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2.在新创建的命名空间中执行模块中包含的代码,见初始导入import my_module
1 提示:导入模块时到底执行了什么? 2 3 In fact function definitions are also ‘statements’ that are ‘executed’; the execution of a module-level function definition enters the function name in the module’s global symbol table. 4 事实上函数定义也是“被执行”的语句,模块级别函数定义的执行将函数名放入模块全局名称空间表,用globals()可以查看
3.创建名字my_module来引用该命名空间
1 这个名字和变量名没什么区别,都是‘第一类的’,且使用my_module.名字的方式可以访问my_module.py文件中定义的名字,my_module.名字与test.py中的名字来自两个完全不同的地方。
为模块名起别名,相当于m1=1;m2=m1
1 import my_module as sm 2 print(sm.money)
示范用法一:
有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
#mysql.py
def sqlparse():
print(‘from mysql sqlparse‘)
#oracle.py
def sqlparse():
print(‘from oracle sqlparse‘)
#test.py
db_type=input(‘>>: ‘)
if db_type == ‘mysql‘:
import mysql as db
elif db_type == ‘oracle‘:
import oracle as db
db.sqlparse()
复制代码
示范用法二:
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如
if file_format == ‘xml‘:
import xmlreader as reader
elif file_format == ‘csv‘:
import csvreader as reader
data=reader.read_date(filename)
在一行导入多个模块
1 import sys,os,re
对比import my_module,会将源文件的名称空间‘my_module‘带到当前名称空间中,使用时必须是my_module.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了、
1 from my_module import read1,read2
这样在当前位置直接使用read1和read2就好了,执行时,仍然以my_module.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到my_module.py中寻找全局变量money
#demo.py
from my_module import read1
money=1000
read1()
‘‘‘
执行结果:
from the my_module.py
spam->read1->money 1000
‘‘‘
#测试二:导入的函数read2,执行时需要调用read1(),仍然回到my_module.py中找read1()
#demo.py
from my_module import read2
def read1():
print(‘==========‘)
read2()
‘‘‘
执行结果:
from the my_module.py
my_module->read2 calling read1
my_module->read1->money 1000
‘‘‘
如果当前有重名read1或者read2,那么会有覆盖效果。
#测试三:导入的函数read1,被当前位置定义的read1覆盖掉了
#demo.py
from my_module import read1
def read1():
print(‘==========‘)
read1()
‘‘‘
执行结果:
from the my_module.py
==========
‘‘‘
需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系,如下:
from my_module import money,read1 money=100 #将当前位置的名字money绑定到了100 print(money) #打印当前的名字 read1() #读取my_module.py中的名字money,仍然为1000 ‘‘‘ from the my_module.py 100 my_module->read1->money 1000 ‘‘‘
也支持as
1 from my_module import read1 as read
也支持导入多行
1 from my_module import (read1, 2 read2, 3 money)
from my_module import * 把my_module中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
from my_module import * #将模块my_module中所有的名字都导入到当前名称空间 print(money) print(read1) print(read2) print(change) ‘‘‘ 执行结果: from the my_module.py 1000 <function read1 at 0x1012e8158> <function read2 at 0x1012e81e0> <function change at 0x1012e8268> ‘‘‘
在my_module.py中新增一行
__all__=[‘money‘,‘read1‘] #这样在另外一个文件中用from my_module import *就这能导入列表中规定的两个名字
*如果my_module.py中的名字前加_,即_money,则from my_module import *,则_money不能被导入
思考:假如有两个模块a,b。我可不可以在a模块中import b ,再在b模块中import a?
考虑到性能的原因,每个模块只被导入一次,放入字典sys.modules中,如果你改变了模块的内容,你必须重启程序,python不支持重新加载或卸载之前导入的模块,
有的同学可能会想到直接从sys.modules中删除一个模块不就可以卸载了吗,注意了,你删了sys.modules中的模块对象仍然可能被其他程序的组件所引用,因而不会被清除。
特别的对于我们引用了这个模块中的一个类,用这个类产生了很多对象,因而这些对象都有关于这个模块的引用。
如果只是你想交互测试的一个模块,使用 importlib.reload(), e.g. import importlib; importlib.reload(modulename),这只能用于测试环境。
def func1():
print(‘func1‘)
import time,importlib import aa time.sleep(20) # importlib.reload(aa) aa.func1()
在20秒的等待时间里,修改aa.py中func1的内容,等待test.py的结果。
打开importlib注释,重新测试
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于‘__main__‘
当做模块导入:
__name__= 模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == ‘__main__‘:
def fib(n):
a, b = 0, 1
while b < n:
print(b, end=‘ ‘)
a, b = b, a+b
print()
if __name__ == "__main__":
print(__name__)
num = input(‘num :‘)
fib(int(num))
标签:int() pen 原因 3.1.1 lib 逻辑 分割文件 inpu 第一个
原文地址:https://www.cnblogs.com/ylx900/p/8946012.html