标签:des blog http java 文件 sp 2014 问题 c
一、计划
首先鉴于之前只学习过c程序和java程序的语法,对c++/c#一无所知,学习语法大约5小时。
虽然上学期写过一个类似的java程序,但感觉功能还是有些区别,而且java与c++的方法好多不同,所以并不能直接在其基础上修改。写各个小功能的函数3小时,写递归函数扫描文件夹3小时。
完成之后还需要对程序进行优化,大约预计这部分用大约3小时。
二、实际用时
实际的用时比自己的预想要差一些,学习c++语法比预想要快一些,用了3个小时左右,简单浏览了一次语法,觉得和之前掌握的c和java都有接近的地方,虽然到实战的时候还是需要查阅书籍或者百度用法。
这些小函数的编写用时较长,大约够6个小时。每个编写的小函数都需要进行一次测试,而且各种问题不断,修改这些bug用时较长。
主递归函数实在不知道如何访问目录,或者判断一个文件是文件还是目录,就只好百度,最后找到一个接近的,在其基础上进行了改动,最后成功了。但这部分在百度之前的各种查资料费时较多,之后的调试过程用时也不短。这个过程历时大约6小时。
在单个单词的程序完成后,对程序进行修改,使其支持双单词和三单词的统计。算法的构思用时2小时,实现用时3小时(这个过程走了弯路,开始对要求理解错误,设计成了同时统计单个单词、双单词、三单词,之后的改动用了也够半个小时)。
由于deadline快到了,时间不多了,所以优化部分做的有些不足,大约用时3个小时。
三、性能分析
1. 在优化的时候,将单个单词、双单词、三单词的输出函数合并为一个函数。
2.对最终输出文件的位置进行修改,使其不放在所搜索的文件夹,而放在初始文件夹中。
3.对三单词的统计不用连接三个单词,而调用连接双单词的中间结果。
4.由于在输出时,标准输出没有任何输出内容,所以可能不知道程序进行到何种程度,故增加了将扫描的文件的完整路径打印出来这一步,虽然可能对性能有些损失。
5.由于对链表的排序感觉有些难度,所以最开始用了冒泡排序,在优化时仿照插入排序改为了逐个插入的排序方法。
Ps:优化前的性能分析未截图,故只有最终的性能分析。
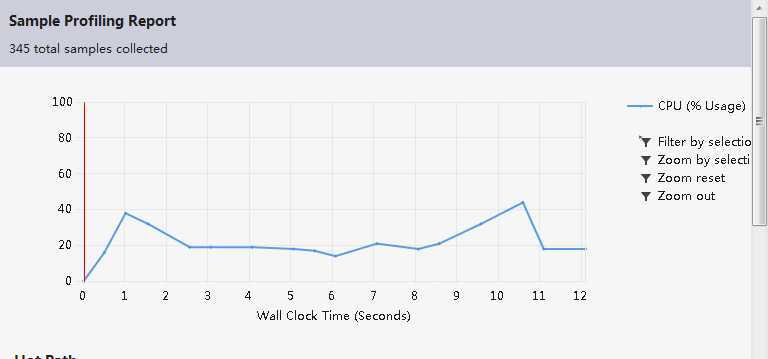
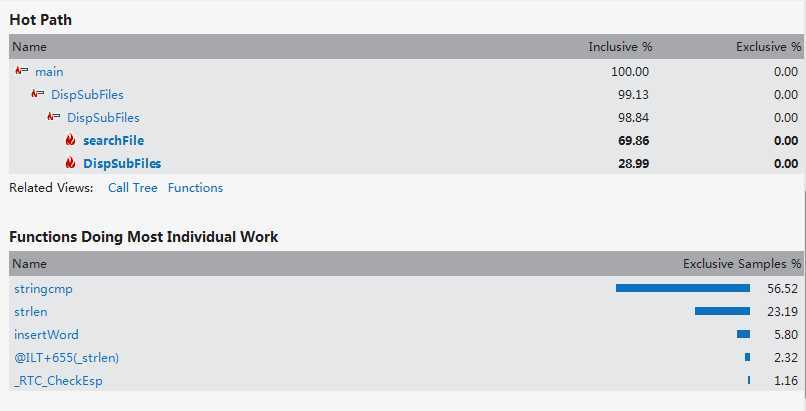
四、测试
PS:空文件夹测试过没有问题,这里没有当做测试点
1. 测试两个单词循环,但大小写不相同(仅三个单词)。输入“C:\Users\CSJ\Desktop\test”,源文件

输出结果

2. 测试其他符号对单词的识别能力(对单词的判定,如数字开头不是单词),输入“C:\Users\CSJ\Desktop\test”,源文件

输出

3. 测试其他符号对单词的分隔作用,输入“C:\Users\CSJ\Desktop\test”,源文件
输出(PS:输出过多,部分截取)
4.测试单词中含有数字,输入“C:\Users\CSJ\Desktop\test”,
源文件

输出

5. 测试多个文件,输入“C:\Users\CSJ\Desktop\test”,
源文件
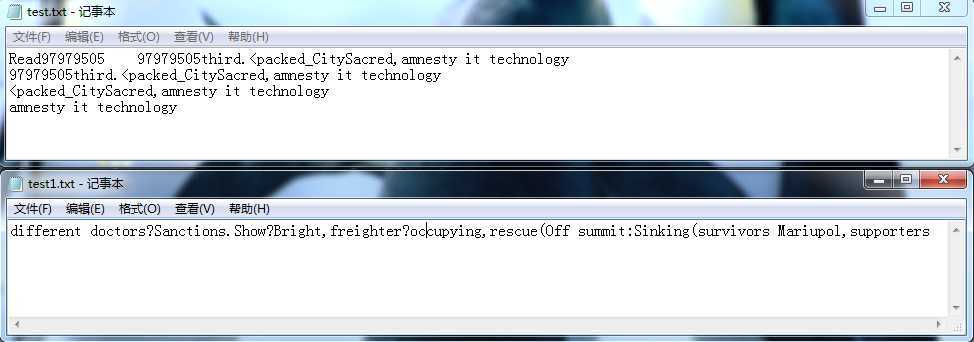
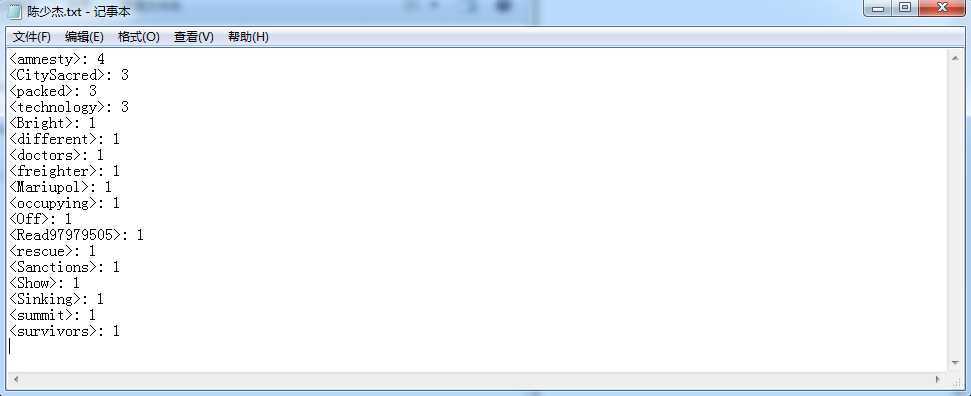
输出
6. 测试多种格式的文件的识别能力,输入“C:\Users\CSJ\Desktop\test”,
源文件
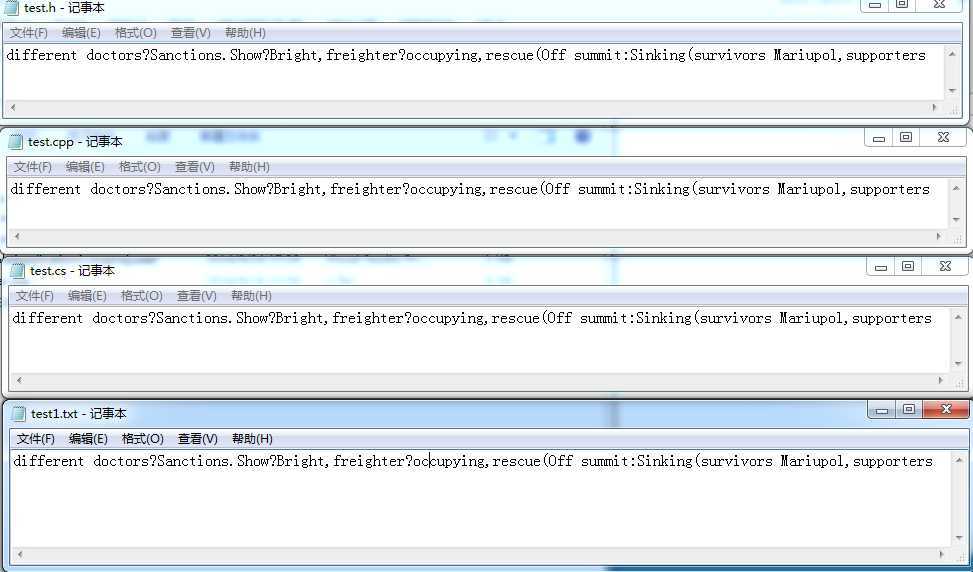
输出
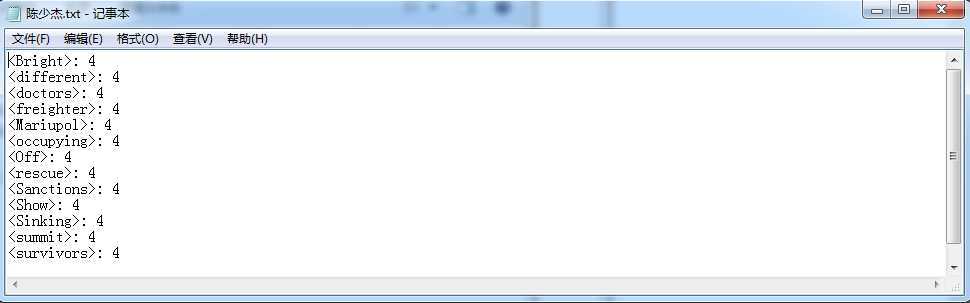
PS:每个单词在每个文件中出现均为一次,所以出现四次,证明四个文件都扫描过。
7. 测试双单词之间的分隔符号识别能力,输入“-e2 C:\Users\CSJ\Desktop\test”,
源文件

输出

8. 测试三单词的识别能力,输入“-e2 C:\Users\CSJ\Desktop\test”
源文件

输出

9. 测试多层目录的文件查找能力(同一个文件放入不同深度的五个文件),输入“C:\Users\CSJ\Desktop\test”
源文件

输出

PS:每个单词在每个文件中出现均为一次或者6次,所以出现5次或者30次,证明5个文件都扫描过。
10. 测试两个连续单词统计中,同义单词反复出现的识别能力,
输入“-e2 C:\Users\CSJ\Desktop\test”
源文件

输出

PS:file的16个不同的大小写形式出现,视为同一个单词,所以任意两个相邻的file可以认为是相同的,故统计为15次。
五、感想
这次的编程作业是我做过的要求极为细致的程序之中,规模最大的一次,所以对输出格式的修改也耗了不少的时间,这给了我一个警示,以后编写代码,要看清楚要求,否则会有很多的后续麻烦。这次的程序在调试过程中,也是各种问题接连出现。比如在刚刚用逐个插入的算法排序之后,最终的输出结果顺序总有问题。找了好长时间,终于发现是判断某个节点是否插入到链表的头节点位置时,作比较的节点选择错误,本来应该是T,结果我写成了T->nextWord。这让我明白,如果要作为程序员,对函数的算法要做到心中有数,一点小小的bug都有可能导致结果的彻底错误。当然这次最大的收获,应当说是我大致上学会了C++的语法,又多了一份技能。
看过张艺的blog之后,心中突然产生共鸣。要不是上个学期在吴际老师的强压之下编程,突然碰到这样的一个程序,可能真的无从下手,所以在此对这个曾经十分反感的老师说声谢谢!
标签:des blog http java 文件 sp 2014 问题 c
原文地址:http://www.cnblogs.com/baitrsou/p/3991917.html