标签:for sts return ror data new lcm loaddata 等等
1.理论基础——条件概率,词集模型、词袋模型
条件概率:朴素贝叶斯最核心的部分是贝叶斯法则,而贝叶斯法则的基石是条件概率。贝叶斯法则如下: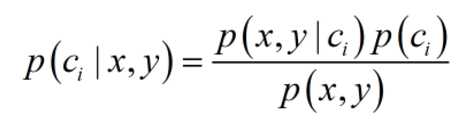
词集模型:对于给定文档,只统计某个侮辱性词汇(准确说是词条)是否在本文档出现
词袋模型:对于给定文档,统计某个侮辱性词汇在本文当中出现的频率,除此之外,往往还需要剔除重要性极低的高频词和停用词。因此,词袋模型更精炼,也更有效。
2.数据预处理——向量化
首先,我们需要一张词典,该词典囊括了训练文档集中的所有必要词汇(无用高频词和停用词除外),还需要把每个文档剔除高频词和停用词;
其次,根据词典向量化每个处理后的文档。具体的,每个文档都定义为词典大小,分别遍历某类(侮辱性和非侮辱性)文档中的每个词汇并统计出现次数;最后,得到一个个跟词典一样大小的向量,这些向量有一个个整数组成,每个整数代表了词典上一个对应位置的词在当下文档中的出现频率。
最后,统计每一类处理过的文档中词汇总个数,某一个文档的词频向量除以相应类别的词汇总个数,即得到相应的条件概率,如P(x,y|C0)。有了P(x,y|C0)和P(C0),P(C0|x,y)就得到了,用完全一样的方法可以获得P(C1|x,y)。比较它们的大小,即可知道某人是不是大坏蛋,某篇文档是不是侮辱性文档了。
3.总结
不同于其它分类器,朴素贝叶斯是一种基于概率理论的分类算法;
特征之间的条件独立性假设,显然这种假设显得“粗鲁”而不符合实际,这也是名称中“朴素”的由来。然而事实证明,朴素贝叶斯在有些领域很有用,比如垃圾邮件过滤;
在具体的算法实施中,要考虑很多实际问题。比如因为“下溢”问题,需要对概率乘积取对数;再比如词集模型和词袋模型,还有停用词和无意义的高频词的剔除,以及大量的数据预处理问题,等等;
总体上来说,朴素贝叶斯原理和实现都比较简单,学习和预测的效率都很高,是一种经典而常用的分类算法。
文本分类代码如下:
1 #coding=‘utf-8‘ 2 from numpy import * 3 import re 4 5 def loadDataSet(): 6 positionList = [[‘my‘, ‘dog‘, ‘has‘, ‘flea‘, ‘problems‘, ‘help‘, ‘please‘], 7 [‘maybe‘, ‘not‘, ‘take‘, ‘him‘, ‘to‘, ‘dog‘, ‘park‘, ‘stupid‘], 8 [‘my‘, ‘dalmation‘, ‘is‘, ‘so‘, ‘cute‘, ‘I‘, ‘love‘, ‘him‘], 9 [‘stop‘, ‘posting‘, ‘stupid‘, ‘worthless‘, ‘garbage‘], 10 [‘mr‘, ‘licks‘, ‘ate‘, ‘my‘, ‘steak‘, ‘how‘, ‘to‘, ‘stop‘, ‘him‘], 11 [‘quit‘, ‘buying‘, ‘worthless‘, ‘dog‘, ‘food‘, ‘stupid‘]] 12 classVec = [0,1,0,1,0,1]#1代表侮辱性文字,0表示正常言论 13 return positionList,classVec 14 15 #创建一个包含在所有文档中出现的不重复词的列表 16 def createVocabList(dataSet): 17 vocabSet = set([]) 18 for document in dataSet: 19 vocabSet = vocabSet | set(document)#两个集合的并集 20 return list(vocabSet) 21 22 #检查输入单词是否在单词表中,若是,则置为1 23 def setOfWords2Vec(vocalList,inputSet): 24 returnVec = [0]*len(vocalList)#创建一个全0向量 25 for word in inputSet: 26 if word in vocalList: 27 returnVec[vocalList.index(word)] = 1 28 else: 29 print("the word %s isn‘t in vocabulary",word) 30 return returnVec 31 32 #训练函数 33 def trainNB0(trainMatrix,trainCategory): 34 #初始化概率 35 numWords = len(trainMatrix[0]) 36 p1Num = ones(numWords) 37 p0Num = ones(numWords) 38 p1Denom = 2.0 39 p0Denom = 2.0 40 numTrainDocs = len(trainMatrix) 41 pAbusive = sum(trainCategory)/float(numTrainDocs)#文章为侮辱类的概率 42 for i in range(numTrainDocs): 43 if trainCategory[i] == 1: 44 p1Num += trainMatrix[i] 45 p1Denom += sum(trainMatrix[i]) 46 else: 47 p0Num += trainMatrix[i] 48 p0Denom += sum (trainMatrix[i]) 49 p1Vect = log(p1Num/p1Denom)#每一个词在类别为侮辱(1)的情况下出现的概率 50 p0Vect = log(p0Num/p0Denom) 51 return p0Vect,p1Vect,pAbusive 52 #向量相加 53 #对每个元素做除法 54 55 #朴素贝叶斯分类函数 56 def classifyNB(vec2Classify,p0V,p1V,pAb): 57 p1 = sum(vec2Classify*p1V) + log(pAb) 58 p0 = sum(vec2Classify * p0V) + log(1.0 - pAb) 59 if p1>p0: 60 return 1 61 else: 62 return 0 63 64 #测试 65 def testingNB(): 66 positionList, classVec = loadDataSet () 67 myvocalList = createVocabList (positionList) 68 trainMat = [] 69 for positionDoc in positionList: 70 trainMat.append(setOfWords2Vec(myvocalList, positionDoc)) 71 p0V, p1V, pAb = trainNB0 (trainMat, classVec) 72 testEntry =[‘me‘,‘hehe‘,‘hate‘] 73 thisDoc = array(setOfWords2Vec(myvocalList,testEntry)) 74 print("类别为",classifyNB(thisDoc,p0V,p1V,pAb)) 75 76 #词袋模型 77 def bagOfWords2VecMN(vocabList, inputSet): 78 returnVec = [0] * len (vocabList) # 创建一个全0向量 79 for word in inputSet: 80 if word in vocabList: 81 returnVec[vocabList.index (word)] += 1 82 return returnVec 83 84 #切分长字符串,比如url,去掉长度大于2的 85 def textParse(bigString): 86 # regEx = re.compile(‘\\W*‘)#\w匹配字母或数字或下划线或汉字 87 # listOfTokens = regEx.split(bigString) 88 89 listOfTokens = re.split(r‘\W*‘,bigString) 90 result = [tok.lower() for tok in listOfTokens if len (tok) > 2] 91 return result 92 93 #对贝叶斯垃圾邮件分类器进行自动化处理 94 def spamTest(): 95 docList = [] 96 fullText = [] 97 classList = [] 98 #导入并解析文本文件 99 for i in range(1,26): 100 f1 = open(‘email/spam/%d.txt‘%i).read()#read,readline返回字符串,readlines返回list 101 wordList = textParse(f1) 102 docList.append(wordList) 103 fullText.extend(wordList) 104 classList.append(1) 105 106 f2 = open(‘email/ham/%d.txt‘%i).read() 107 wordList = textParse(f2) 108 docList.append(wordList) 109 fullText.extend(wordList) 110 classList.append(0) 111 vocabList = createVocabList(docList) 112 113 #随机构建训练集 114 testSet = [] 115 trainingSet = list(range(50)) 116 for i in range(10):#随机产生10个在0:49之间的数,还不能重复 117 randIndex = int(random.uniform(0,len(trainingSet)))#random.uniform(x,y)随机生成在[x,y)范围内的实数 118 testSet.append(trainingSet[randIndex]) 119 del(trainingSet[randIndex]) 120 print(testSet)#[14, 46, 32, 28, 43, 5, 7, 11, 16, 47] 121 trainMat = [] 122 trainClasses = [] 123 for docIndex in trainingSet: 124 trainMat.append(setOfWords2Vec(vocabList,docList[docIndex])) 125 trainClasses.append(classList[docIndex]) 126 p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses)) 127 128 errorCount = 0 129 130 #对测试集分类 131 for docIndex in testSet: 132 wordVector = setOfWords2Vec(vocabList,docList[docIndex]) 133 if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]: 134 print ("docIndex", docIndex) 135 errorCount += 1 136 print("错误率",float(errorCount)/len(testSet)) 137 138 if __name__ == ‘__main__‘: 139 spamTest()
从个人广告中获取区域倾向代码如下:
1 #coding=‘utf-8‘ 2 from numpy import * 3 import re 4 import operator 5 import feedparser 6 7 #创建一个包含在所有文档中出现的不重复词的列表 8 def createVocabList(dataSet): 9 vocabSet = set([]) 10 for document in dataSet: 11 vocabSet = vocabSet | set(document)#两个集合的并集 12 return list(vocabSet) 13 14 #检查输入单词是否在单词表中,若是,则置为1 15 def setOfWords2Vec(vocalList,inputSet): 16 returnVec = [0]*len(vocalList)#创建一个全0向量 17 for word in inputSet: 18 if word in vocalList: 19 returnVec[vocalList.index(word)] = 1 20 else: 21 print("the word %s isn‘t in vocabulary",word) 22 return returnVec 23 24 #训练函数 25 def trainNB0(trainMatrix,trainCategory): 26 #初始化概率 27 numWords = len(trainMatrix[0]) 28 p1Num = ones(numWords) 29 p0Num = ones(numWords) 30 p1Denom = 2.0 31 p0Denom = 2.0 32 numTrainDocs = len(trainMatrix) 33 pAbusive = sum(trainCategory)/float(numTrainDocs)#文章为侮辱类的概率 34 for i in range(numTrainDocs): 35 if trainCategory[i] == 1: 36 p1Num += trainMatrix[i] 37 p1Denom += sum(trainMatrix[i]) 38 else: 39 p0Num += trainMatrix[i] 40 p0Denom += sum (trainMatrix[i]) 41 p1Vect = log(p1Num/p1Denom)#每一个词在类别为侮辱(1)的情况下出现的概率 42 p0Vect = log(p0Num/p0Denom) 43 return p0Vect,p1Vect,pAbusive 44 45 #朴素贝叶斯分类函数 46 def classifyNB(vec2Classify,p0V,p1V,pAb): 47 p1 = sum(vec2Classify*p1V) + log(pAb) 48 p0 = sum(vec2Classify * p0V) + log(1.0 - pAb) 49 if p1>p0: 50 return 1 51 else: 52 return 0 53 54 #词袋模型 55 def bagOfWords2VecMN(vocabList, inputSet): 56 returnVec = [0] * len (vocabList) # 创建一个全0向量 57 for word in inputSet: 58 if word in vocabList: 59 returnVec[vocabList.index (word)] += 1 60 return returnVec 61 62 #切分长字符串,比如url,去掉长度大于2的 63 def textParse(bigString): 64 listOfTokens = re.split(r‘\W*‘,bigString) 65 result = [tok.lower() for tok in listOfTokens if len (tok) > 2] 66 return result 67 68 #计算出现频率 69 def calcMostFreq(vocabList,fullText): 70 freqDict = {} 71 for token in vocabList: 72 freqDict[token] = fullText.count(token) 73 sortedFreq = sorted(freqDict.items(),key=operator.itemgetter(1),reverse=True)#sorted对于任何可迭代的对象,sort只能对list排序;默认升序 74 return sortedFreq[:250] #返回重新排序的列表 75 76 #RSS源分类器 77 def localWords(feed1,feed0): 78 docList = [] 79 fullText = [] 80 classList = [] 81 lfeed1 = len(feed1[‘entries‘]) 82 lfeed0 = len(feed0[‘entries‘]) 83 minLen = min( lfeed1, lfeed0 ) 84 85 # 每次访问一条RSS源 86 for i in range (minLen): 87 f1 = feed1[‘entries‘][i][‘summary‘] # read,readline返回字符串,readlines返回list 88 wordList = textParse (f1) 89 docList.append (wordList) 90 fullText.extend (wordList) 91 classList.append(1) 92 93 f0 = feed0[‘entries‘][i][‘summary‘] 94 wordList = textParse (f0) 95 docList.append (wordList) 96 fullText.extend (wordList) 97 classList.append(0) 98 vocabList = createVocabList (docList) 99 top30Words = calcMostFreq(vocabList,fullText)#[(‘not‘,5),...] 100 101 #去掉出现次数最高的那些词 102 for pairW in top30Words: 103 if pairW[0] in vocabList: 104 vocabList.remove(pairW[0]) 105 106 trainingSet = list(range(2*minLen)) 107 testSet = [] 108 # 随机构建训练集 109 for i in range (20): # 随机产生20个在0:49之间的数,还不能重复 110 randIndex = int (random.uniform (0, len (trainingSet))) # random.uniform(x,y)随机生成在[x,y)范围内的实数 111 testSet.append (trainingSet[randIndex]) 112 del(trainingSet[randIndex]) 113 trainMat = [] 114 trainClasses = [] 115 for docIndex in trainingSet: 116 trainMat.append (bagOfWords2VecMN (vocabList, docList[docIndex])) 117 trainClasses.append (classList[docIndex]) 118 p0V, p1V, pSpam = trainNB0 (array (trainMat), array (trainClasses)) 119 errorCount = 0 120 121 # 对测试集分类 122 for docIndex in testSet: 123 wordVector = bagOfWords2VecMN (vocabList, docList[docIndex]) 124 if classifyNB (array (wordVector), p0V, p1V, pSpam) != classList[docIndex]: 125 errorCount += 1 126 print("错误率",float(errorCount)/len(testSet)) 127 print("p0V",p0V) 128 print("p1V",p1V) 129 return vocabList,p0V,p1V 130 131 #显示地域相关的用词 132 def getTopWords(ny,sf): 133 vocabList, psF, pNY = localWords (ny, sf) 134 topNY =[] 135 topSF =[] 136 for i in range(len(psF)): 137 if psF[i] > -2.0: 138 topSF.append((vocabList[i],psF[i])) 139 if pNY[i] > -2.0: 140 topNY.append((vocabList[i],pNY[i])) 141 sortedSF = list(sorted(topSF,key=lambda pair: pair[1],reverse=True)) 142 print("----------------------SF-------------------------") 143 for i in sortedSF: 144 print(i[0]) 145 sortedNY = sorted(topNY,key=lambda pair: pair[1],reverse=True) 146 print ("---------------------NY-------------------------") 147 for i in sortedNY: 148 print(i[0]) 149 150 151 if __name__ == ‘__main__‘: 152 # ny = feedparser.parse(‘http://newyork.craigslist.org/stp/index.rss‘) 153 # sf = feedparser.parse(‘http://sfbay.craigslist.org/stp/index.rss‘) 154 ny = feedparser.parse(‘http://news.qq.com/newscomments/rss_comment.xml‘) 155 sf = feedparser.parse(‘http://news.qq.com/newscomments/rss_comment.xml‘) 156 getTopWords (ny, sf)
标签:for sts return ror data new lcm loaddata 等等
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/8948369.html