标签:elk filebeat kibana elasticsearch
我们遇到的问题是日志太多,如果使用关键字报警,日志里的error,trace, warning等关键字那更是说不过来。所以我们一天的日志报警量是2千多条,于是就想解决这个问题,发现elk可以很好的处理日志,还能分析日志,对收集的日志,后面进一步处理也是很好的。所以就选择试用elk
知道用什么了,那接下来就是部署,试用了。
使用的版本, 下载地址:https://www.elastic.co/downloads| 项目 | version | 形式 |
|---|---|---|
| elasticsearch | 6.2.4 | rpm |
| kibana | 6.2.4 | rpm |
| filebeat | 6.2.4 | rpm |
系统准备
| 主机名 | 系统 | 安装服务 |
|---|---|---|
| host1 | centos7 | elasticsearch+kibana |
| host2 | centos7 | elasticsearch |
| host3 | centos7 | filebeat |
1.下载elasticsearch rpm包,安装(host1+host2)
yum install elasticsearch
2.配置elasticsearch(host1+host2)
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:es
node.name:host1#或者host2
network.host:0.0.0.0
http.port:9200
discovery.zen.ping.unicast.hosts:[‘host1‘,‘host2‘]2.安装x-pack,做安全认证,权限管理(host1+host2)
/usr/share/elasticsearch/bin/elasticsearch-plugininstallx-pack#安装x-pack
systemctl start elasticsearch#检查running
/usr/share/elasticsearch/bin/x-pack/setup-passwordsinteractive#使用默认回车,输入认证密码比如:elk3.检查集群状态
curl http://host1:9200/_cluster/health#提示需要账户密码,输入上一步设置的账户密码返回结果:
{"cluster_name":"es","status":"green","timed_out":false,"number_of_nodes":2,"number_of_data_nodes":2,"active_primary_shards":17,"active_shards":34
,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":0,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0
,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":100.0}1.下载kibana rpm包, 安装(host1)
yum install kibana2.安装x-pack
/usr/share/kibana/bin/kibana-plugininstallx-pack3.配置kibana (host1)
vim /etc/kibana/kibana.yml
elasticsearch.username:"elk"#输入在安装elasticsearch的时候设置的账户密码
elasticsearch.password:"elk"
elasticsearch.url:"http://localhost:9200"#设置elasticsearch的地址4.启动kibana
systemctl start kibana5.设置代理
因为kibana默认启动的监听端口是127.0.0.1. 我们可以使用nginx做代理, 安装nginx就不用说了,说一下nginx的配置
新建文件 /etc/nginx/conf.d/es.conf
server{
listen*:1234;
server_namehost1;
access_log/var/log/nginx/es_access.log;
error_log/var/log/nginx/es_error.log;
location/{
proxy_passhttp://127.0.0.1:5601;
}
}6.验证服务正常
在浏览器输入:curl http://host1:1234 #提示输入账户密码,输入在 安装elasticsearch的时候设置的kibana账户密码, 返回正常洁面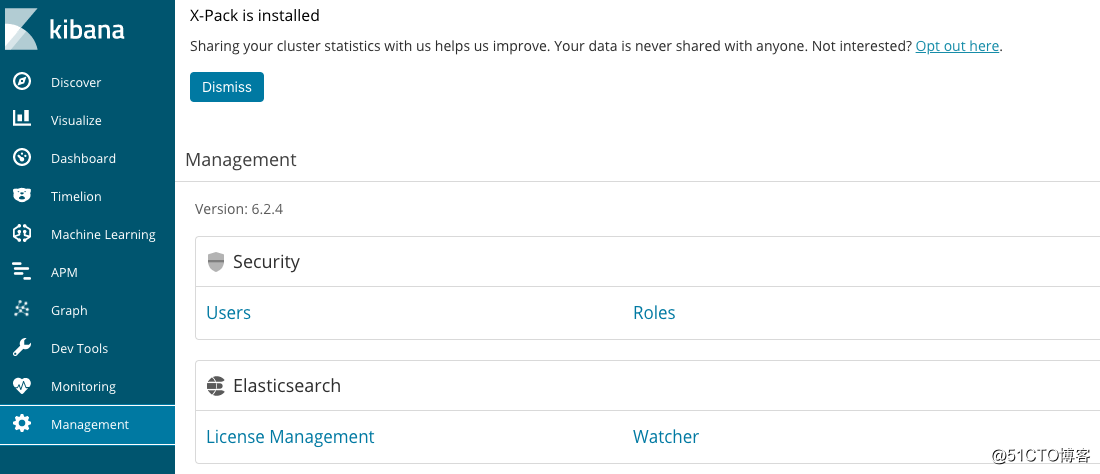
1.下载fileat rpm包,安装 host3
yum install filebeat2.配置filebeat
vim /etc/filebeat/filebeat.yml
filebeat.prospectors:#设置日志收集
-type:log
enabled:true
paths:
-/var/log/nova/*.log
tags:["nova"]
output.elasticsearch:#设置数据吐到elasticsearch
hosts:["host1:9200"]
protocol:"http"
username:"elk"
password:"elk"3.启动服务
systemctl start filebeat4.验证服务
打开kibana界面,management > index Patterns > create index Patterns > 显示有fileat-version-time的文件,说明数据已经收集到es cluster里了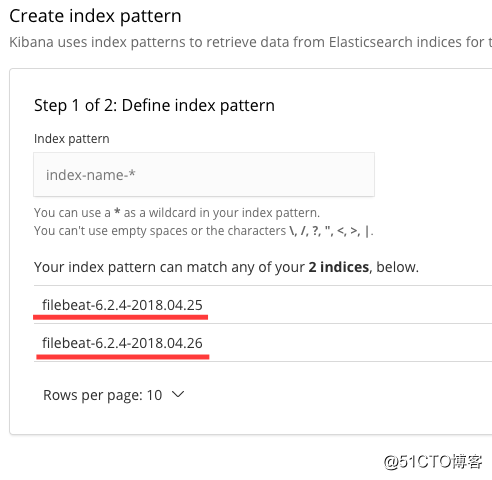
下一篇继续说kibana的简单使用
标签:elk filebeat kibana elasticsearch
原文地址:http://blog.51cto.com/evawalle/2108038