标签:style blog http io os 使用 文件 数据 div
千辛万苦敲完了这个项目的代码,说实话真的没想到会花费这么多的时间,在现实的强烈对比下才发现自己真的是图样图森破。
1、预计用时
因为上个学期的OO课做过类似的程序,想一想觉得再做一遍so easy,于是感觉心理有谱,预计用4个小时搞定,再用最多1个小时做测试。
2、现实的残酷性
前3个小时是用来干杂务的(写宏函数,建树,写小函数,对命令行情况的分类讨论,设计整个项目的结构),
再有3个小时是找各种资料的(文件流,模板库,string类,还有忘得差不多了的二叉树遍历),
再一个3个小时是用来敲代码的,至此简单模式完成。
运行,崩了。
Bug年年有,今年特别多。4个小时的时间调试啊有木有!
调试完成花了两个小时的时间写扩展模式。
至此,任务完成。总计13个小时。
3、性能分析
大家都在扫描vs的目录,我也扫。
路径"C:\Program Files (x86)\Microsoft Visual Studio 11.0"
第一次运行崩了。
查原因,设了好多断点,终于发现是在遍历树的时候递归层数太多,发生了栈溢出。于是改成非递归形式。
再运行,可以了。附图。
结果:
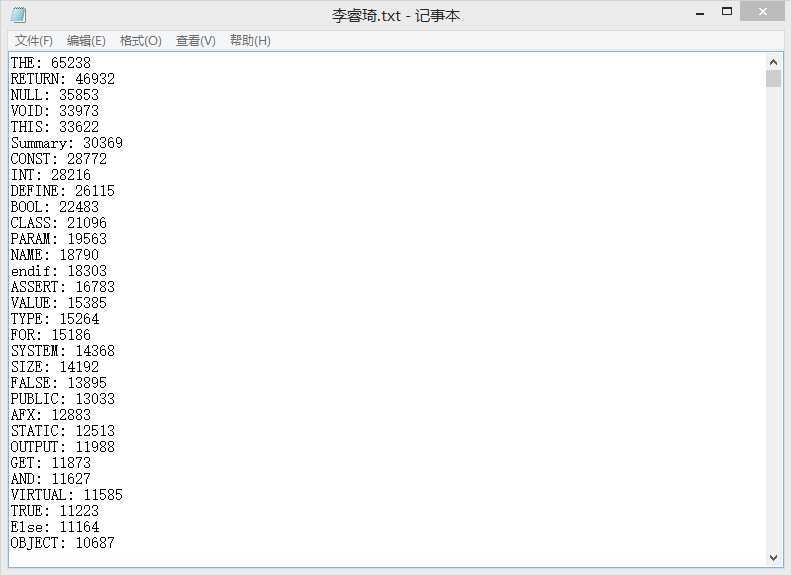
性能:
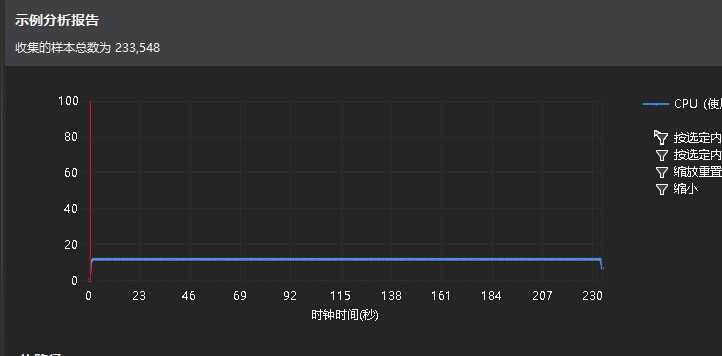
因为采用了树结构,相对于除了哈希表之外的其他一些数据结构而言速度快了不少。
4、测试用例
测试用例使用的是同学那里考来的追风筝的人,结果如图。
简单模式:
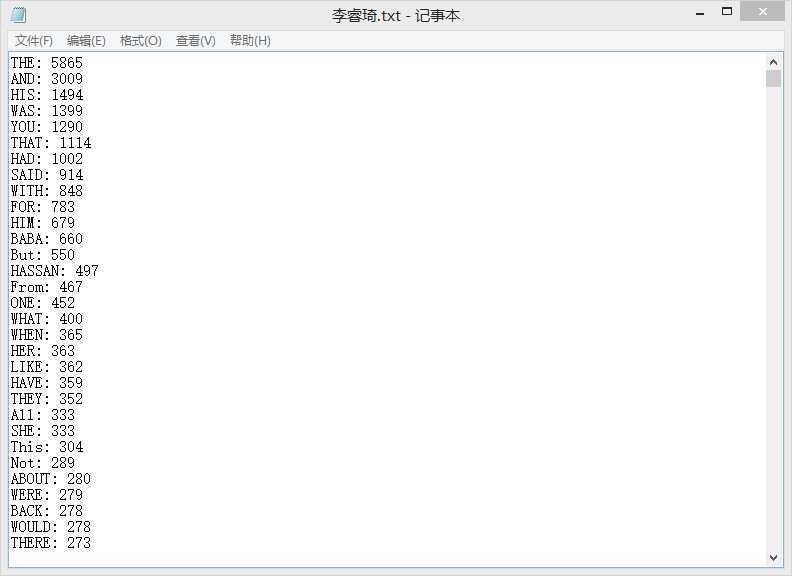
拓展模式1:
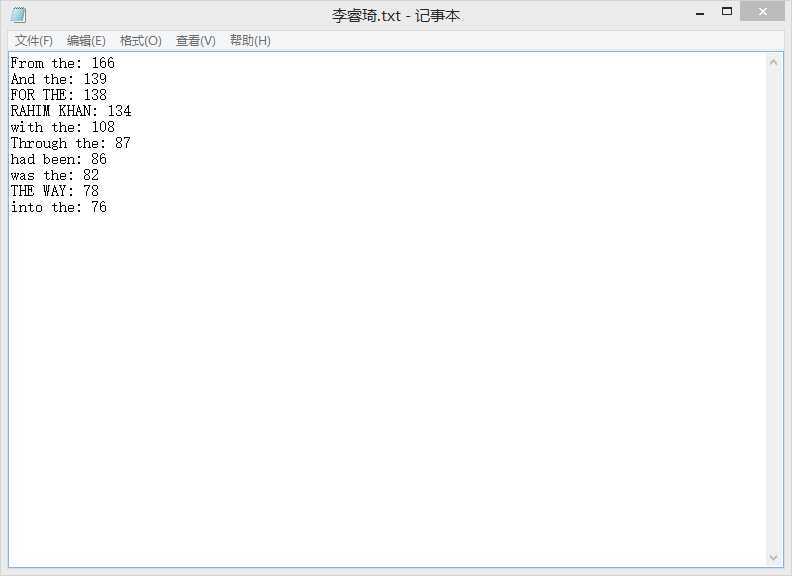
拓展模式2:
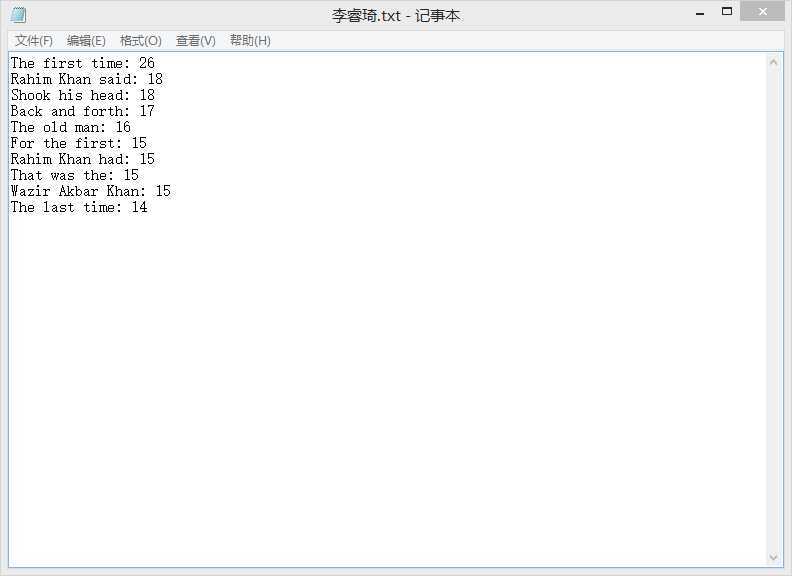
三种模式所用函数类似,通过人工查找的办法检测了出现次数比较少的单词的个数,与结果相符。
再测试了一些错误输入,程序直接退出,没有崩溃。
5、收获
从这次项目中复习了树的构造和遍历,熟悉了模板库和文件流的使用,知道了栈溢出这一特殊情况。另外还狂敲了四百多行代码,锻炼了coding的手感。
软件工程:Individual Project - Word frequency program
标签:style blog http io os 使用 文件 数据 div
原文地址:http://www.cnblogs.com/1206ricky/p/3991969.html