标签:get 开发效率 运行 git 框架 div 安装 常用 手动
Celery 是一个由 Python 编写的简单、灵活、可靠的用来处理大量信息的分布式系统,它同时提供操作和维护分布式系统所需的工具。
Celery 专注于实时任务处理,支持任务调度。
说白了,它是一个分布式队列的管理工具,我们可以用 Celery 提供的接口快速实现并管理一个分布式的任务队列。
首先,我们要理解 Celery 本身不是任务队列,它是管理分布式任务队列的工具,或者换一种说法,它封装好了操作常见任务队列的各种操作,我们用它可以快速进行任务队列的使用与管理,当然你也可以自己看 rabbitmq 等队列的文档然后自己实现相关操作都是没有问题的。
Celery 是语言无关的,虽然它是用 Python 实现的,但他提供了其他常见语言的接口支持。只是如果你恰好使用 Python 进行开发那么使用 Celery 就自然而然了。
想让 Celery 运行起来我们要明白几个概念:
brokers 中文意思为中间人,在这里就是指任务队列本身,Celery 扮演生产者和消费者的角色,brokers 就是生产者和消费者存放/拿取产品的地方(队列)
常见的 brokers 有 rabbitmq、redis、Zookeeper 等
顾名思义就是结果储存的地方,队列中的任务运行完后的结果或者状态需要被任务发送者知道,那么就需要一个地方储存这些结果,就是 Result Stores 了
常见的 backend 有 redis、Memcached 甚至常用的数据都可以。
就是 Celery 中的工作者,类似与生产/消费模型中的消费者,其从队列中取出任务并执行
就是我们想在队列中进行的任务,一般由用户、触发器或其他操作将任务入队,然后交由 workers 进行处理。
理解以上概念后我们就可以快速实现一个队列的操作:
这里我们用 redis 当做 celery 的 broker 和 backend。
(其他 brokers 与 backend 支持看这里)
安装 Celery 和 redis 以及 python 的 redis 支持:
apt-get install redis-server
pip install redis
pip install celery
这里需要注意如果你的 celery 是 4.0 及以上版本请确保 python 的 redis 库版本在 2.10.4 及以上,否则会出现 redis 连接 timeout 的错误,具体参考
然后,我们需要写一个task:
#tasks.py from celery import Celery app = Celery(‘tasks‘, backend=‘redis://localhost:6379/0‘, broker=‘redis://localhost:6379/0‘) #配置好celery的backend和broker @app.task #普通函数装饰为 celery task def add(x, y): return x + y
OK,到这里,broker 我们有了,backend 我们有了,task 我们也有了,现在就该运行 worker 进行工作了,在 tasks.py 所在目录下运行:
celery -A tasks worker --loglevel=info
意思就是运行 tasks 这个任务集合的 worker 进行工作(当然此时broker中还没有任务,worker此时相当于待命状态)
最后一步,就是触发任务啦,最简单方式就是再写一个脚本然后调用那个被装饰成 task 的函数:
#trigger.py from tasks import add result = add.delay(4, 4) #不要直接 add(4, 4),这里需要用 celery 提供的接口 delay 进行调用 while not result.ready(): time.sleep(1) print ‘task done: {0}‘.format(result.get())
运行此脚本
delay 返回的是一个 AsyncResult 对象,里面存的就是一个异步的结果,当任务完成时result.ready() 为 true,然后用 result.get() 取结果即可。
到此,一个简单的 celery 应用就完成啦。
经过快速入门的学习后,我们已经能够使用 Celery 管理普通任务,但对于实际使用场景来说这是远远不够的,所以我们需要更深入的去了解 Celery 更多的使用方式。
首先来看之前的task:
@app.task #普通函数装饰为 celery task def add(x, y): return x + y
这里的装饰器app.task实际上是将一个正常的函数修饰成了一个 celery task 对象,所以这里我们可以给修饰器加上参数来决定修饰后的 task 对象的一些属性。
首先,我们可以让被修饰的函数成为 task 对象的绑定方法,这样就相当于被修饰的函数 add 成了 task 的实例方法,可以调用 self 获取当前 task 实例的很多状态及属性。
其次,我们也可以自己复写 task 类然后让这个自定义 task 修饰函数 add ,来做一些自定义操作。
任务执行后,根据任务状态执行不同操作需要我们复写 task 的 on_failure、on_success 等方法:
# tasks.py class MyTask(Task): def on_success(self, retval, task_id, args, kwargs): print ‘task done: {0}‘.format(retval) return super(MyTask, self).on_success(retval, task_id, args, kwargs) def on_failure(self, exc, task_id, args, kwargs, einfo): print ‘task fail, reason: {0}‘.format(exc) return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo) @app.task(base=MyTask) def add(x, y): return x + y
嗯, 然后继续运行 worker:
celery -A tasks worker --loglevel=info
运行脚本,得到:
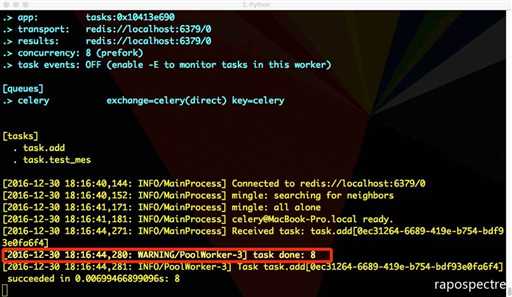
再修改下tasks:
@app.task #普通函数装饰为 celery task def add(x, y): raise KeyError return x + y
重新运行 worker,再运行 trigger.py:
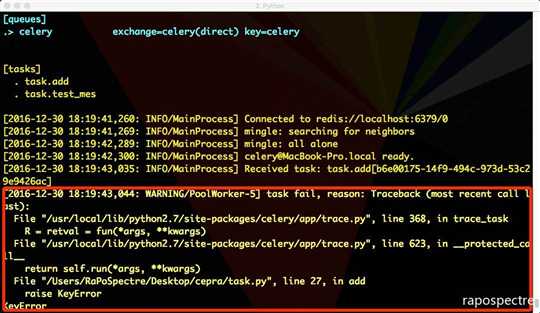
可以看到,任务执行成功或失败后分别执行了我们自定义的 on_failure、on_success
# tasks.py from celery.utils.log import get_task_logger logger = get_task_logger(__name__) @app.task(bind=True) def add(self, x, y): logger.info(self.request.__dict__) return x + y
然后重新运行:
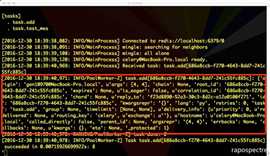
执行中的任务获取到了自己执行任务的各种信息,可以根据这些信息做很多其他操作,例如判断链式任务是否到结尾等等。
关于 celery.task.request 对象的详细数据可以看这里
实际场景中得知任务状态是很常见的需求,对于 Celery 其内建任务状态有如下几种:
| 参数 | 说明 |
|---|---|
| PENDING | 任务等待中 |
| STARTED | 任务已开始 |
| SUCCESS | 任务执行成功 |
| FAILURE | 任务执行失败 |
| RETRY | 任务将被重试 |
| REVOKED | 任务取消 |
当我们有个耗时时间较长的任务进行时一般我们想得知它的实时进度,这里就需要我们自定义一个任务状态用来说明进度并手动更新状态,从而告诉回调当前任务的进度,具体实现:
# tasks.py from celery import Celery import time @app.task(bind=True) def test_mes(self): for i in xrange(1, 11): time.sleep(0.1) self.update_state(state="PROGRESS", meta={‘p‘: i*10}) return ‘finish‘
然后在 trigger.py 中增加:
# trigger.py from task import add,test_mes import sys def pm(body): res = body.get(‘result‘) if body.get(‘status‘) == ‘PROGRESS‘: sys.stdout.write(‘\r任务进度: {0}%‘.format(res.get(‘p‘))) sys.stdout.flush() else: print ‘\r‘ print res r = test_mes.delay() print r.get(on_message=pm, propagate=False)
Celery 进行周期任务也很简单,只需要在配置中配置好周期任务,然后在运行一个周期任务触发器( beat )即可:
新建 Celery 配置文件 celery_config.py:
# celery_config.py from datetime import timedelta from celery.schedules import crontab CELERYBEAT_SCHEDULE = { ‘ptask‘: { ‘task‘: ‘tasks.period_task‘, ‘schedule‘: timedelta(seconds=5), }, } CELERY_RESULT_BACKEND = ‘redis://localhost:6379/0‘
配置中 schedule 就是间隔执行的时间,这里可以用 datetime.timedelta 或者 crontab 甚至太阳系经纬度坐标进行间隔时间配置,具体可以参考这里
如果定时任务涉及到 datetime 需要在配置中加入时区信息,否则默认是以 utc 为准。例如中国可以加上:
CELERY_TIMEZONE = ‘Asia/Shanghai‘
然后在 tasks.py 中增加要被周期执行的任务:
# tasks.py app = Celery(‘tasks‘, backend=‘redis://localhost:6379/0‘, broker=‘redis://localhost:6379/0‘) app.config_from_object(‘celery_config‘) @app.task(bind=True) def period_task(self): print ‘period task done: {0}‘.format(self.request.id)
然后重新运行 worker,接着再运行 beat:
celery -A task beat
有些任务可能需由几个子任务组成,此时调用各个子任务的方式就变的很重要,尽量不要以同步阻塞的方式调用子任务,而是用异步回调的方式进行链式任务的调用:
@app.task def update_page_info(url): page = fetch_page.delay(url).get() info = parse_page.delay(url, page).get() store_page_info.delay(url, info) @app.task def fetch_page(url): return myhttplib.get(url) @app.task def parse_page(url, page): return myparser.parse_document(page) @app.task def store_page_info(url, info): return PageInfo.objects.create(url, info)
def update_page_info(url): # fetch_page -> parse_page -> store_page chain = fetch_page.s(url) | parse_page.s() | store_page_info.s(url) chain() @app.task() def fetch_page(url): return myhttplib.get(url) @app.task() def parse_page(page): return myparser.parse_document(page) @app.task(ignore_result=True) def store_page_info(info, url): PageInfo.objects.create(url=url, info=info)
fetch_page.apply_async((url), link=[parse_page.s(), store_page_info.s(url)])
链式任务中前一个任务的返回值默认是下一个任务的输入值之一 ( 不想让返回值做默认参数可以用 si() 或者 s(immutable=True) 的方式调用 )。
这里的 s() 是方法 celery.signature() 的快捷调用方式,signature 具体作用就是生成一个包含调用任务及其调用参数与其他信息的对象,个人感觉有点类似偏函数的概念:先不执行任务,而是把任务与任务参数存起来以供其他地方调用。
前面讲了调用任务不能直接使用普通的调用方式,而是要用类似 add.delay(2, 2) 的方式调用,而链式任务中又用到了 apply_async 方法进行调用,实际上 delay 只是 apply_async 的快捷方式,二者作用相同,只是 apply_async 可以进行更多的任务属性设置,比如 callbacks/errbacks 正常回调与错误回调、执行超时、重试、重试时间等等,具体参数可以参考这里
AsyncResult 主要用来储存任务执行信息与执行结果,有点类似 tornado 中的 Future 对象,都有储存异步结果与任务执行状态的功能,对于写 js 的朋友,它有点类似 Promise 对象,当然在 Celery 4.0 中已经支持了 promise 协议,只需要配合 gevent 一起使用就可以像写 js promise 一样写回调:
import gevent.monkey monkey.patch_all() import time from celery import Celery app = Celery(broker=‘amqp://‘, backend=‘rpc‘) @app.task def add(x, y): return x + y def on_result_ready(result): print(‘Received result for id %r: %r‘ % (result.id, result.result,)) add.delay(2, 2).then(on_result_ready)
要注意的是这种 promise 写法现在只能用在 backend 是 RPC (amqp) 或 Redis 时。 并且独立使用时需要引入 gevent 的猴子补丁,可能会影响其他代码。 官方文档给的建议是这个特性结合异步框架使用更合适,例如 tornado、 twisted 等。
delay 与 apply_async 生成的都是 AsyncResult 对象,此外我们还可以根据 task id 直接获取相关 task 的 AsyncResult: AsyncResult(task_id=xxx)
关于 AsyncResult 更详细的内容,可以参考这里
利用 Celery 进行分布式队列管理、开发将会大幅提升开发效率,关于 Celery 更详细的使用大家可以去参考详细的官方文档
标签:get 开发效率 运行 git 框架 div 安装 常用 手动
原文地址:https://www.cnblogs.com/ctztake/p/8964939.html