标签:init __name__ python object day 出版社 ## sts ini
对豆瓣读书网进行书评书单推荐简介和推荐链接数据爬取:
from bs4 import BeautifulSoup
import requests
import jieba
import time
import datetime
r = requests.get(‘https://book.douban.com‘)
lyrics = ‘‘
html=r.text
soup = BeautifulSoup(html, ‘html.parser‘)
items = []
global_nav_items = soup.find(‘div‘, class_=‘global-nav-items‘)
for tag in global_nav_items.find_all(‘a‘):
items.append(tag.string)
print(items)
# /定义一个数据存储类
class Info(object):
def __init__(self, title, img, link, author, year, pulisher, abstract):
self.title = title
self.img = img
self.link = link
self.author = author
self.year = year
self.publisher = publisher
self.abstract = abstract
new_book_html = soup.find(‘ul‘, class_=‘list-col list-col5 list-express slide-item‘)
book_info_list = []
for tag in new_book_html.find_all(‘li‘):
info_html = tag.find(‘div‘, class_=‘info‘)
info_title = info_html.find(‘a‘)
title = info_title.string.strip()
cover = tag.find(‘div‘, class_=‘cover‘)
img = cover.find(‘img‘)[‘src‘].strip()
href = info_title[‘href‘].strip()
author = info_html.find(class_=‘author‘).string.strip()
year = info_html.find(class_=‘year‘).string.strip()
publisher = info_html.find(class_=‘publisher‘).string.strip()
abstract = info_html.find(class_=‘abstract‘).string.strip()
book = Info(title, img, href, author, year, publisher, abstract)
book_info_list.append(book)
print(‘推荐%s本新书‘ % len(book_info_list))
for book in book_info_list:
print(‘*‘*100)
print(book.title)
print(book.img)
print(book.link)
print(book.author)
print(book.year)
print(book.publisher)
print(book.abstract)
将所爬的数据存储在mark down文件中:
def save():
today = datetime.datetime.fromtimestamp(time.time()).strftime(‘%Y-%m-%d‘)
file_name = ‘豆瓣‘+today+‘推荐书单‘
with open(file_name+‘.md‘, ‘w‘) as file:
file.write(‘#‘+file_name)
file.write(‘\\n---‘)
with open(file_name+‘.md‘, ‘a‘) as file:
num = 1
for book in book_info_list:
file.write(‘\\n\\n‘)
file.write(‘## ‘ + str(num) +‘. ‘ + book.title)
file.write(‘\\n‘)
file.write(‘‘)
file.write(‘\\n\\n‘)
file.write(‘简介\\n‘)
file.write(‘---\\n‘)
file.write(book.abstract)
file.write(‘\\n\\n‘)
file.write(‘作者: ‘+book.author+‘\\n\\n‘)
file.write(‘出版时间: ‘+book.year+‘\\n\\n‘)
file.write(‘出版社: ‘+book.publisher+‘\\n\\n‘)
file.write(‘[更多...](‘+book.link+‘)‘)
num = num + 1
if __name__ == ‘__main__‘:
save()
截图:

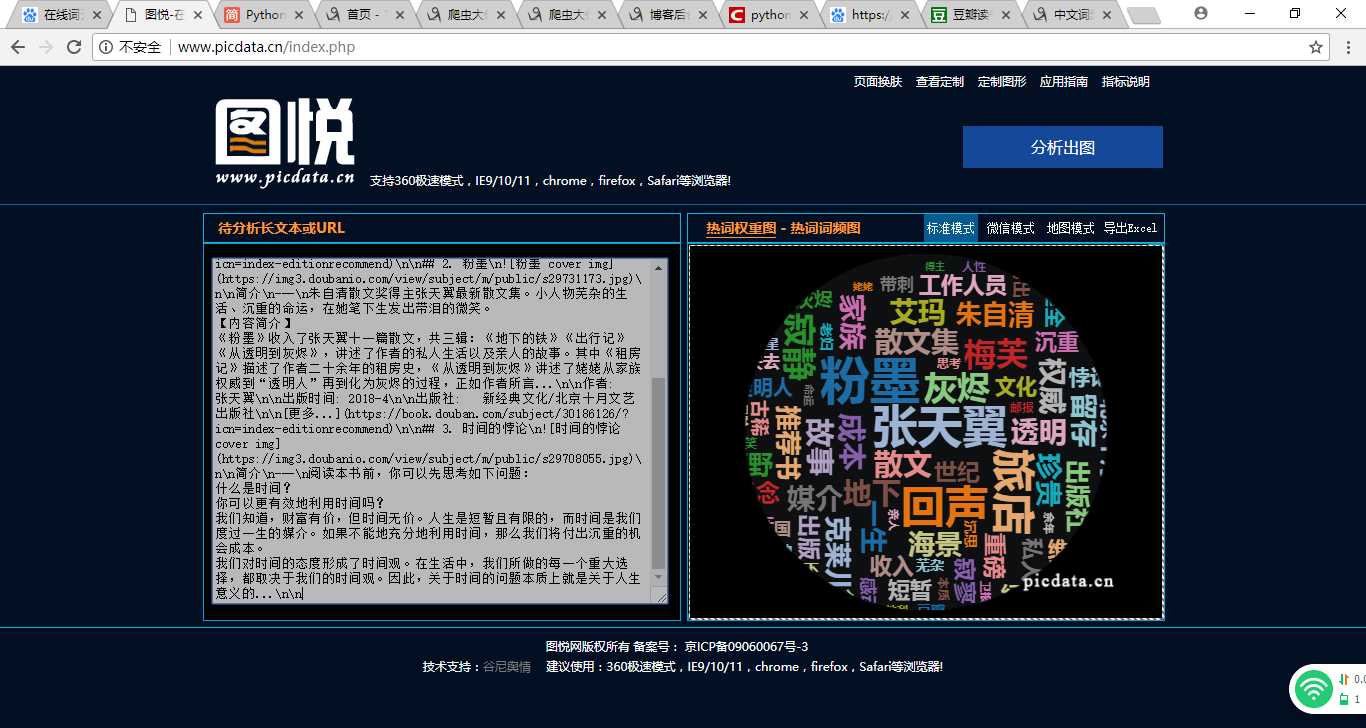
词云生成截图:
相关问题:
1.在电脑无法安装词云wordcloud,将代码复制在在线词云生成器进行词云生成;
2.数据无法直接保存至文本文件,改用mark down 文件存储;
标签:init __name__ python object day 出版社 ## sts ini
原文地址:https://www.cnblogs.com/whr7116365/p/8971346.html