标签:des mat 函数返回 修改 desc 保留 判断 flush ef6
name=input(‘姓名>>: ‘) res=‘SB‘ if name == ‘alex‘ else ‘NB‘ print(res)

#老男孩由于峰哥的强势加盟很快走上了上市之路,alex思来想去决定下几个鸡蛋来报答峰哥 egg_list=[‘鸡蛋%s‘ %i for i in range(10)] #列表解析 #峰哥瞅着alex下的一筐鸡蛋,捂住了鼻子,说了句:哥,你还是给我只母鸡吧,我自己回家下 laomuji=(‘鸡蛋%s‘ %i for i in range(10))#生成器表达式 print(laomuji) print(next(laomuji)) #next本质就是调用__next__ print(laomuji.__next__()) print(next(laomuji))
总结:
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum(x ** 2 for x in range(4))
而不用多此一举使用如下方式
sum([x ** 2 for x in range(4)])
1. 递归调用的定义
递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用
2. 递归的最大深度-997
一个简单的故事:从前有个山,山里有座庙,庙里老和尚讲故事, 讲的什么呢?这个故事我们可以一直讲下去
def story(): s = """ 从前有个山,山里有座庙,庙里老和尚讲故事, 讲的什么呢? """ print(s) story() story()
可以看出如果递归函数没有遇到外力的阻止,会一直进行下去,而函数的执行,会不断的在内存中开辟名称空间,而处于一个无限调用开辟的过程中,而造成内存不足,python为了杜绝此类事情的发生,强制将递归的层数限制在997,如下可以测试得知
def foo(n): print(n) n += 1 foo(n) foo(1)
由此可见未报错之前是997,为了实现我们程序的优化而设置为997,当然此值是可以更改的
import sys print(sys.setrecursionlimit(100000))
此处说明一点,如果递归深度为997都没有得到你的程序想要的结果,则说明你的程序写的确实比较烂。。。
看到此处我们或许觉得递归没有while True好用,江湖人称:人理解循环,神理解递归,所以不容小看递归,之后的很多算法都和递归有关,所以必须掌握递归。
3. 理解递归的思想
现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。
你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。
你又问武sir,武sir也不告诉你,他说他比金鑫大两岁。
那你问金鑫,金鑫告诉你,他40了。。。
这个时候你是不是就知道了?alex多大?
我们用等式来说明这个问题
age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 40
对于这样的情况我们用函数如何表现呢?
def foo(n): if n==1: return 40 else: return foo(n-1)+2 print(foo(4))
4. 总结递归调用
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
#注意:内置函数id()可以返回一个对象的身份,返回值为整数。这个整数通常对应与该对象在内存中的位置,但这与python 的具体实现有关,不应该作为对身份的定义,即不够精准,最精准的还是以内存地址为准。is运算符用于比较两个对象的身份, 等号比较两个对象的值,内置函数type()则返回一个对象的类型 #更多内置函数:https://docs.python.org/3/library/functions.html?highlight=built#ascii

上面就是内置函数的表,68个函数都在这儿了。这个表的顺序是按照首字母的排列顺序来的,你会发现都混乱的堆在一起。比如,oct和bin和hex都是做进制换算的,但是却被写在了三个地方。。。这样非常不利于大家归纳和学习。那我把这些函数分成了6大类。你看下面这张图,你猜咱们今天会学哪几大类呀?
1. 作用域关系
基于字典的形式获取局部变量和全局变量
globals()——获取全局变量的字典
locals()——获取执行本方法所在命名空间内的局部变量的字典
2. 其他
#1、语法 # eval(str,[,globasl[,locals]]) # exec(str,[,globasl[,locals]]) #2、区别 #示例一: s=‘1+2+3‘ print(eval(s)) #eval用来执行表达式,并返回表达式执行的结果 print(exec(s)) #exec用来执行语句,不会返回任何值 ‘‘‘ 6 None ‘‘‘ #示例二: print(eval(‘1+2+x‘,{‘x‘:3},{‘x‘:30})) #返回33 print(exec(‘1+2+x‘,{‘x‘:3},{‘x‘:30})) #返回None # print(eval(‘for i in range(10):print(i)‘)) #语法错误,eval不能执行表达式 print(exec(‘for i in range(10):print(i)‘))
compile(str,filename,kind) filename:用于追踪str来自于哪个文件,如果不想追踪就可以不定义 kind可以是:single代表一条语句,exec代表一组语句,eval代表一个表达式 s=‘for i in range(10):print(i)‘ code=compile(s,‘‘,‘exec‘) exec(code) s=‘1+2+3‘ code=compile(s,‘‘,‘eval‘) eval(code)
输入输出相关:
input() 输入
s = input("请输入内容 : ") #输入的内容赋值给s变量 print(s) #输入什么打印什么。数据类型是str
print() 输出
def print(self, *args, sep=‘ ‘, end=‘\n‘, file=None): # known special case of print """ print(value, ..., sep=‘ ‘, end=‘\n‘, file=sys.stdout, flush=False) file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件 sep: 打印多个值之间的分隔符,默认为空格 end: 每一次打印的结尾,默认为换行符 flush: 立即把内容输出到流文件,不作缓存 """
f = open(‘tmp_file‘,‘w‘) print(123,456,sep=‘,‘,file = f,flush=True)
import time for i in range(0,101,2): time.sleep(0.1) char_num = i//2 #打印多少个‘*‘ per_str = ‘\r%s%% : %s\n‘ % (i, ‘*‘ * char_num) if i == 100 else ‘\r%s%% : %s‘%(i,‘*‘*char_num) print(per_str,end=‘‘, flush=True) #小越越 : \r 可以把光标移动到行首但不换行
数据类型相关:
type(o) 返回变量o的数据类型
内存相关:
id(o) o是参数,返回一个变量的内存地址
hash(o) o是参数,返回一个可hash变量的哈希值,不可hash的变量被hash之后会报错。
t = (1,2,3) l = [1,2,3] print(hash(t)) #可hash print(hash(l)) #会报错 ‘‘‘ 结果: TypeError: unhashable type: ‘list‘
hash函数会根据一个内部的算法对当前可hash变量进行处理,返回一个int数字。
*每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
文件操作相关
open() 打开一个文件,返回一个文件操作符(文件句柄)
操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
可以用encoding指定编码.
模块操作相关
__import__导入一个模块
import time
os = __import__(‘os‘) print(os.path.abspath(‘.‘))
帮助方法
在控制台执行help()进入帮助模式。可以随意输入变量或者变量的类型。输入q退出
或者直接执行help(o),o是参数,查看和变量o有关的操作。。。
和调用相关
callable(o),o是参数,看这个变量是不是可调用。
如果o是一个函数名,就会返回True
def func():pass print(callable(func)) #参数是函数名,可调用,返回True print(callable(123)) #参数是数字,不可调用,返回False
查看参数所属类型的所有内置方法
dir() 默认查看全局空间内的属性,也接受一个参数,查看这个参数内的方法或变量
print(dir(list)) #查看列表的内置方法 print(dir(int)) #查看整数的内置方法
3. 和数字相关
数字——数据类型相关:bool,int,float,complex
数字——进制转换相关:bin,oct,hex
数字——数学运算:abs,divmod,min,max,sum,round,pow
4. 和数据结构相关
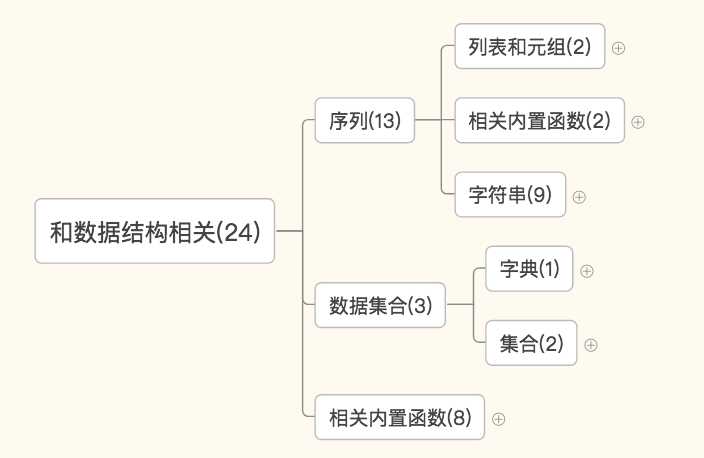
序列——列表和元组相关的:list和tuple
序列——字符串相关的:str,format,bytes,bytearry,memoryview,ord,chr,ascii,repr
ret = bytearray(‘alex‘,encoding=‘utf-8‘) print(id(ret)) print(ret[0]) ret[0] = 65 print(ret) print(id(ret))
ret = memoryview(bytes(‘你好‘,encoding=‘utf-8‘)) print(len(ret)) print(bytes(ret[:3]).decode(‘utf-8‘)) print(bytes(ret[3:]).decode(‘utf-8‘))
序列:reversed,slice
l = (1,2,23,213,5612,342,43) print(l) print(list(reversed(l)))
l = (1,2,23,213,5612,342,43) sli = slice(1,5,2) print(l[sli])
数据集合——字典和集合:dict,set,frozenset
数据集合:len,sorted,enumerate,all,any,zip,filter,map
fileter 和 map
filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x): return x % 2 == 1
然后,利用filter()过滤掉偶数:
>>>filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
结果:
[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s): return s and len(s.strip()) > 0
>>>filter(is_not_empty, [‘test‘, None, ‘‘, ‘str‘, ‘ ‘, ‘END‘])
结果:
[‘test‘, ‘str‘, ‘END‘]
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括‘\n‘, ‘\r‘, ‘\t‘, ‘ ‘),如下:
>>> a = ‘ 123‘ >>> a.strip() ‘123‘ >>> a = ‘\t\t123\r\n‘ >>> a.strip() ‘123‘
练习:
请利用filter()过滤出1~100中平方根是整数的数,即结果应该是:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
方法:
import math def is_sqr(x): return math.sqrt(x) % 1 == 0 print filter(is_sqr, range(1, 101))
结果:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
map
Python中的map函数应用于每一个可迭代的项,返回的是一个结果list。如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
有一个list, L = [1,2,3,4,5,6,7,8],我们要将f(x)=x^2作用于这个list上,那么我们可以使用map函数处理。
>>> L = [1,2,3,4,] >>> def pow2(x): ... return x*x ... >>> map(pow2,L) [1, 4, 9, 16]
sorted
sorted(iterable, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customise the sort order, and the
reverse flag can be set to request the result in descending order.
l1 = [1,3,5,-2,-4,-6] l2 = sorted(l1,key=abs) print(l1) print(l2)
l = [[1,2],[3,4,5,6],(7,),‘123‘] print(sorted(l,key=len))
#字符串可以提供的参数 ‘s‘ None >>> format(‘some string‘,‘s‘) ‘some string‘ >>> format(‘some string‘) ‘some string‘ #整形数值可以提供的参数有 ‘b‘ ‘c‘ ‘d‘ ‘o‘ ‘x‘ ‘X‘ ‘n‘ None >>> format(3,‘b‘) #转换成二进制 ‘11‘ >>> format(97,‘c‘) #转换unicode成字符 ‘a‘ >>> format(11,‘d‘) #转换成10进制 ‘11‘ >>> format(11,‘o‘) #转换成8进制 ‘13‘ >>> format(11,‘x‘) #转换成16进制 小写字母表示 ‘b‘ >>> format(11,‘X‘) #转换成16进制 大写字母表示 ‘B‘ >>> format(11,‘n‘) #和d一样 ‘11‘ >>> format(11) #默认和d一样 ‘11‘ #浮点数可以提供的参数有 ‘e‘ ‘E‘ ‘f‘ ‘F‘ ‘g‘ ‘G‘ ‘n‘ ‘%‘ None >>> format(314159267,‘e‘) #科学计数法,默认保留6位小数 ‘3.141593e+08‘ >>> format(314159267,‘0.2e‘) #科学计数法,指定保留2位小数 ‘3.14e+08‘ >>> format(314159267,‘0.2E‘) #科学计数法,指定保留2位小数,采用大写E表示 ‘3.14E+08‘ >>> format(314159267,‘f‘) #小数点计数法,默认保留6位小数 ‘314159267.000000‘ >>> format(3.14159267000,‘f‘) #小数点计数法,默认保留6位小数 ‘3.141593‘ >>> format(3.14159267000,‘0.8f‘) #小数点计数法,指定保留8位小数 ‘3.14159267‘ >>> format(3.14159267000,‘0.10f‘) #小数点计数法,指定保留10位小数 ‘3.1415926700‘ >>> format(3.14e+1000000,‘F‘) #小数点计数法,无穷大转换成大小字母 ‘INF‘ #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数 >>> format(0.00003141566,‘.1g‘) #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点 ‘3e-05‘ >>> format(0.00003141566,‘.2g‘) #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点 ‘3.1e-05‘ >>> format(0.00003141566,‘.3g‘) #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点 ‘3.14e-05‘ >>> format(0.00003141566,‘.3G‘) #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写 ‘3.14E-05‘ >>> format(3.1415926777,‘.1g‘) #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点 ‘3‘ >>> format(3.1415926777,‘.2g‘) #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点 ‘3.1‘ >>> format(3.1415926777,‘.3g‘) #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点 ‘3.14‘ >>> format(0.00003141566,‘.1n‘) #和g相同 ‘3e-05‘ >>> format(0.00003141566,‘.3n‘) #和g相同 ‘3.14e-05‘ >>> format(0.00003141566) #和g相同 ‘3.141566e-05‘ format(了解即可)
字典的运算:最小值,最大值,排序 salaries={ ‘egon‘:3000, ‘alex‘:100000000, ‘wupeiqi‘:10000, ‘yuanhao‘:2000 } 迭代字典,取得是key,因而比较的是key的最大和最小值 >>> max(salaries) ‘yuanhao‘ >>> min(salaries) ‘alex‘ 可以取values,来比较 >>> max(salaries.values()) >>> min(salaries.values()) 但通常我们都是想取出,工资最高的那个人名,即比较的是salaries的值,得到的是键 >>> max(salaries,key=lambda k:salary[k]) ‘alex‘ >>> min(salaries,key=lambda k:salary[k]) ‘yuanhao‘ 也可以通过zip的方式实现 salaries_and_names=zip(salaries.values(),salaries.keys()) 先比较值,值相同则比较键 >>> max(salaries_and_names) (100000000, ‘alex‘) salaries_and_names是迭代器,因而只能访问一次 >>> min(salaries_and_names) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: min() arg is an empty sequence sorted(iterable,key=None,reverse=False)
匿名函数:为了解决那些功能简单而设置的一句话函数
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
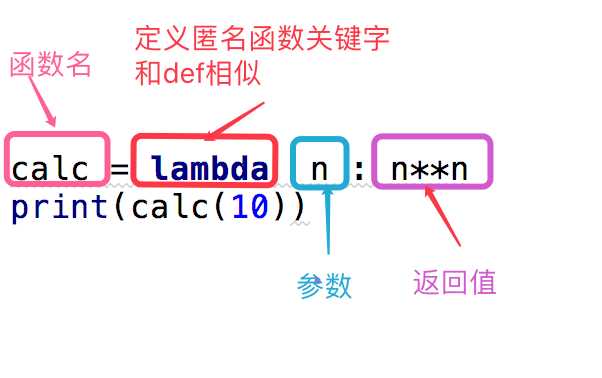
上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型
我们可以看出匿名函数并非真的没有函数名,他的调用和函数的调用也就没有区别,也是只需要 函数名(参数) 即可
上边是匿名函数的函数用法,除此之外还可以匿名真的可以匿名,并和其他函数合作使用
l=[3,2,100,999,213,1111,31121,333] print(max(l)) dic={‘k1‘:10,‘k2‘:100,‘k3‘:30} print(max(dic)) print(dic[max(dic,key=lambda k:dic[k])])
有名函数与匿名函数的对比
#有名函数与匿名函数的对比 有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能 匿名函数:一次性使用,随时随时定义 应用:max,min,sorted,map,reduce,filter
1 文件内容如下,标题为:姓名,性别,年纪,薪资
egon male 18 3000
alex male 38 30000
wupeiqi female 28 20000
yuanhao female 28 10000
要求:
从文件中取出每一条记录放入列表中,
列表的每个元素都是{‘name‘:‘egon‘,‘sex‘:‘male‘,‘age‘:18,‘salary‘:3000}的形式
2 根据1得到的列表,取出薪资最高的人的信息。
3 根据1得到的列表,取出最年轻的人的信息。
4 根据1得到的列表,将每个人的信息中的名字映射成首字母大写的形式。
5 根据1得到的列表,过滤掉名字以a开头的人的信息。
6 使用递归打印斐波那契数列(前两个数的和得到第三个数,如:0 1 1 2 3 4 7...)。
7 一个嵌套很多层的列表,如l=[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]],用递归取出所有的值
#1 with open(‘db.txt‘) as f: items=(line.split() for line in f) info=[{‘name‘:name,‘sex‘:sex,‘age‘:age,‘salary‘:salary} for name,sex,age,salary in items] print(info) #2 print(max(info,key=lambda dic:dic[‘salary‘])) #3 print(min(info,key=lambda dic:dic[‘age‘])) # 4 info_new=map(lambda item:{‘name‘:item[‘name‘].capitalize(), ‘sex‘:item[‘sex‘], ‘age‘:item[‘age‘], ‘salary‘:item[‘salary‘]},info) print(list(info_new)) #5 g=filter(lambda item:item[‘name‘].startswith(‘a‘),info) print(list(g)) #6 #非递归 def fib(n): a,b=0,1 while a < n: print(a,end=‘ ‘) a,b=b,a+b print() fib(10) #递归 def fib(a,b,stop): if a > stop: return print(a,end=‘ ‘) fib(b,a+b,stop) fib(0,1,10) #7 l=[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]] def get(seq): for item in seq: if type(item) is list: get(item) else: print(item) get(l)
三元表达式、列表推导式、生成器表达式、递归、内置函数、匿名函数
标签:des mat 函数返回 修改 desc 保留 判断 flush ef6
原文地址:https://www.cnblogs.com/xiao-xiong/p/8969955.html
