标签:lenovo set pos ttf 单行 cte 分词 src com
导入包:
import pynlpir import pandas as pd import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties import multiprocessing,threading,time
读入初始文本、停用词文件,创建保存初始分词数据的Dataframe
f_1 = open(r"C:\Users\lenovo\Desktop\肖老师爬虫项目\停用词.txt", "r") stopwords = f_1.read().splitlines() f_1.close() f = open(r"C:\Users\lenovo\Desktop\肖老师爬虫项目\data_3.txt", "r") pd_root = pd.DataFrame(columns=[‘词汇‘, ‘词性‘])
一些参数:
time_start = time.time() #用于既是计时 pynlpir.open() font = FontProperties(fname=r‘c:\windows\fonts\simhei.ttf‘, size=13) #设置画图时的字体
过滤停用词函数:
def stopword_delete(df):
global stopwords
for i in range(df.shape[0]):
if (df.词汇[i] in stopwords):
df.drop(i,inplace=True)
else:
pass
return df
由于文件里文本内容比较多,直接读取、分词、过滤会比较慢,采用多线程按行读取并处理
单行处理函数:
def line_deal(line):
global pd_root
line = line.replace(" ", "")
segment = pynlpir.segment(line, pos_names=‘parent‘, pos_english=False) #对单行分词
pd_line = pd.DataFrame(segment,columns=[‘词汇‘,‘词性‘]) #单行datafrrame
pd_line = stopword_delete(pd_line) #过滤停用词
pd_root = pd_root.append(pd_line,ignore_index=True)
使用多线程读取:
threads_list = [] #线程列表
thread_max = 30 #最大线程
n=0
for line in f:
p = threading.Thread(target=line_deal,args=(line,))
threads_list.append(p)
p.start()
n=n+1
print(len(threads_list),n) #打印当前线程数和读取到的行数
for pro in threads_list:
if pro.is_alive() == True:
continue
else:
threads_list.remove(pro)
if len(threads_list) >= thread_max:
time.sleep(0.1)
else:
continue
f.close() #读取完后关闭文件
打印最初分词后的数据:
print(pd_root.head(10))

创建词汇-频数库:
pd_word_num = pd.DataFrame(pd_root[‘词汇‘].value_counts())
pd_word_num.rename(columns={‘词汇‘: ‘频数‘})
pd_word_num.rename(columns={‘词汇‘:‘频数‘},inplace=True)
pd_word_num[‘百分比‘] = pd_word_num[‘频数‘] / pd_word_num[‘频数‘].sum()
print(pd_word_num.head(10))
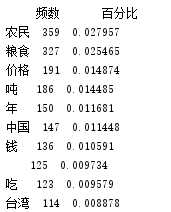
创建词性-频数库:
pd_qua_num = pd.DataFrame(pd_root[‘词性‘].value_counts())
#更改列名
pd_qua_num.rename(columns={‘词性‘:‘频数‘},inplace=True)
#添加百分比列:词性-频数-百分比
pd_qua_num[‘百分比‘] = pd_qua_num[‘频数‘] / pd_qua_num[‘频数‘].sum()
print(pd_qua_num.head(10))
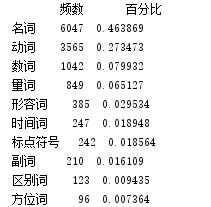
统计几种重要词性的词汇分布:
# 定义6类词性统计数据框
columns_selected=[‘动词‘,‘动词计数‘,‘名词‘,‘名词计数‘,‘代词‘,‘代词计数‘,
‘时间词‘,‘时间词计数‘,‘副词‘,‘副词计数‘,‘形容词‘,‘形容词计数‘]
pd_Top6 = pd.DataFrame(columns=columns_selected)
for i in range(0,12,2):
pd_Top6[columns_selected[i]] = pd_root.loc[pd_root[‘词性‘]==columns_selected[i]][‘词汇‘].value_counts().reset_index()[‘index‘]
pd_Top6[columns_selected[i+1]] = pd_root.loc[pd_root[‘词性‘]==columns_selected[i]][‘词汇‘].value_counts().reset_index()[‘词汇‘]
print(pd_Top6.head(10))
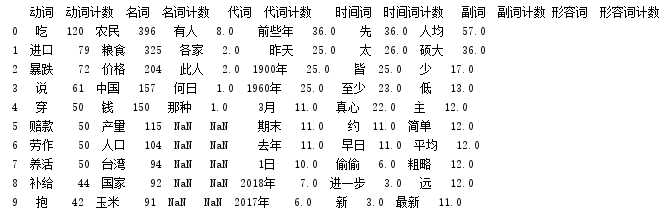
提取文本中关键词:
key_words = pynlpir.get_key_words(str, weighted=True) print(key_words)
绘图:
def paint(df,x,y,title):
plt.subplots(figsize=(7,5))
plt.yticks(fontproperties=font,size=10)
plt.xlabel(x,fontproperties=font,size=10)
plt.ylabel(y,fontproperties=font,size=10)
plt.title(title,fontproperties=font)
df.iloc[:10][‘频数‘].plot(kind=‘barh‘)
plt.show()
paint(pd_word_num,"频数","词汇","词汇分布")
paint(pd_qua_num,"频数","词性","词性分布")
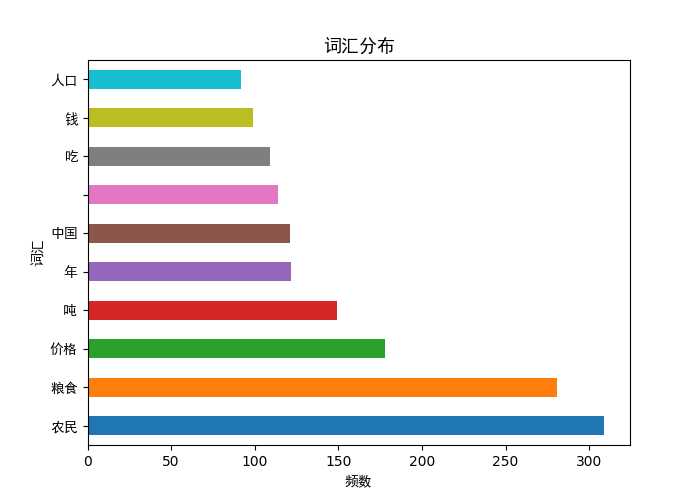
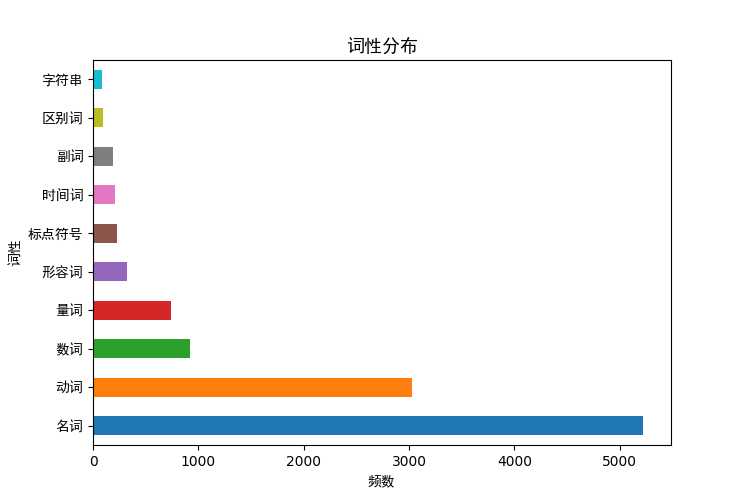
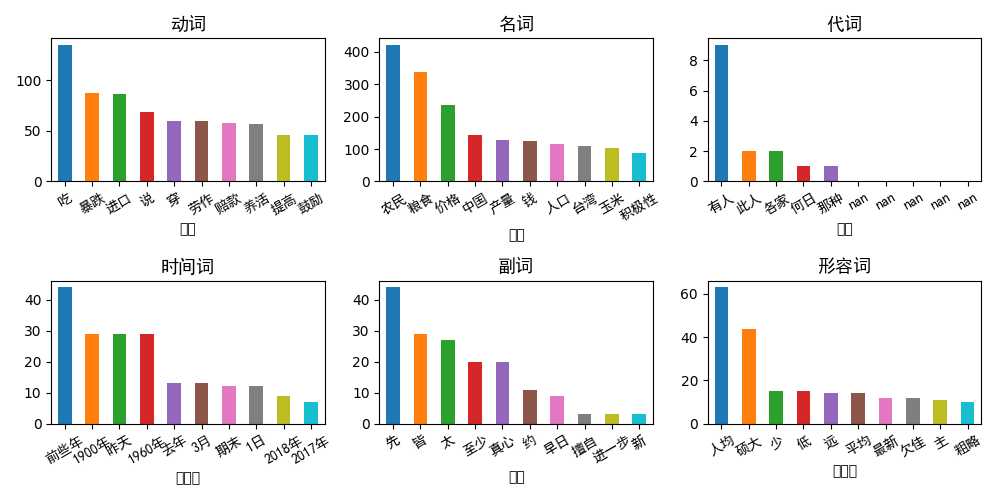
fig = plt.figure(figsize=(10,5))
fig.subplots_adjust(hspace=0.3,wspace=0.2)
for i in range(1,7):
pd_qua = pd_Top6.iloc[:,[(2*i-2),2*i-1]]
pd_qua.columns = [pd_qua.columns[0],‘频数‘]
pd_qua = pd_qua.set_index(pd_qua.columns[0])
print(pd_qua)
ax = fig.add_subplot(2,3,i)
pd_qua.head(10)[‘频数‘].plot(kind=‘bar‘)
ax.set_xticklabels(pd_qua.head(10).index,fontproperties=font,size=10,rotation=30)
ax.set_title(pd_qua.index.name,fontproperties=font)
fig.tight_layout()
fig.show()
标签:lenovo set pos ttf 单行 cte 分词 src com
原文地址:https://www.cnblogs.com/panda-blog/p/8967284.html