标签:状态 .sh memset cpp 能力 print uid mil 最大数
可以限定容器中的虚拟系统对于各种资源的使用,包括cpu,内存,磁盘和网络资源,这需要使用cgroup相关技术来实现。
为了使用cgroup相关的功能,我们首先需要将cgroup提供的特殊文件系统cgroup安装到我们的容器中。
在容器的/etc/fstab中加入以下内容,可以通过在宿主系统上通过mount |grep cgroup命令查看需要mount的文件系统。
1 tmpfs /sys/fs/cgroup tmpfs defaults 0 0 2 3 cgroup /sys/fs/cgroup/pids cgroup rw,nosuid,nodev,noexec,relatime,pids 0 0 4 cgroup /sys/fs/cgroup/perf_event cgroup rw,nosuid,nodev,noexec,relatime,perf_event 0 0 5 cgroup /sys/fs/cgroup/cpu,cpuacct cgroup rw,nosuid,nodev,noexec,relatime,cpuacct,cpu 0 0 6 cgroup /sys/fs/cgroup/devices cgroup rw,nosuid,nodev,noexec,relatime,devices 0 0 7 cgroup /sys/fs/cgroup/net_cls,net_prio cgroup rw,nosuid,nodev,noexec,relatime,net_prio,net_cls 0 0 8 cgroup /sys/fs/cgroup/blkio cgroup rw,nosuid,nodev,noexec,relatime,blkio 0 0 9 cgroup /sys/fs/cgroup/hugetlb cgroup rw,nosuid,nodev,noexec,relatime,hugetlb 0 0 10 cgroup /sys/fs/cgroup/memory cgroup rw,nosuid,nodev,noexec,relatime,memory 0 0 11 cgroup /sys/fs/cgroup/freezer cgroup rw,nosuid,nodev,noexec,relatime,freezer 0 0 12 cgroup /sys/fs/cgroup/cpuset cgroup rw,nosuid,nodev,noexec,relatime,cpuset 0 0 13 cgroup /sys/fs/cgroup/systemd cgroup rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd
然后在容器中执行:
1 03:06:36 root@abc /#cat /etc/cgroup.mount 2 3 mount /sys/fs/cgroup 4 5 mkdir /sys/fs/cgroup/systemd 6 mkdir /sys/fs/cgroup/pids 7 mkdir /sys/fs/cgroup/perf_event 8 mkdir /sys/fs/cgroup/cpu,cpuacct 9 mkdir /sys/fs/cgroup/devices 10 mkdir /sys/fs/cgroup/net_cls,net_prio 11 mkdir /sys/fs/cgroup/blkio 12 mkdir /sys/fs/cgroup/hugetlb 13 mkdir /sys/fs/cgroup/memory 14 mkdir /sys/fs/cgroup/freezer 15 mkdir /sys/fs/cgroup/cpuset 16 17 mount /sys/fs/cgroup/systemd 18 mount /sys/fs/cgroup/pids 19 mount /sys/fs/cgroup/perf_event 20 mount /sys/fs/cgroup/cpu,cpuacct 21 mount /sys/fs/cgroup/devices 22 mount /sys/fs/cgroup/net_cls,net_prio 23 mount /sys/fs/cgroup/blkio 24 mount /sys/fs/cgroup/hugetlb 25 mount /sys/fs/cgroup/memory 26 mount /sys/fs/cgroup/freezer 27 mount /sys/fs/cgroup/cpuset
这样在我们的容器中就可以提供对cgroup的支持了。下面开始介绍cgroup相关的概念以及具体如何操作从而能够实现对资源的使用限制。
(1) cgroup的全称: Control Group。
(2) cgroup是Linux中提供的一种应用程序资源限制的机制。
具体可以限制的资源可以通过lssubsys查询。在cgroup的概念体系中,这些资源被称为subsys,即子系统。
(1) 限制CPU资源。
(2) 限制内存资源。
(3) 限制IO资源。包括磁盘IO和网络IO。
|
子系统 |
说明 |
|
cpuset |
为应用程序分配一个或多个CPU。 |
|
cpu,cpuacct |
为应用程序提供CPU的访问和CPU资源报告 |
|
memory |
为应用程序提供内存资源限制 |
|
devices |
为应用程序提供设备访问限制,允许或不允许。 |
|
freezer |
暂停和恢复应用程序。 |
|
net_cls,net_prio |
标记网络包 |
|
blkio |
块设备IO控制,比如硬盘,光盘和U盘等。 |
|
perf_event |
监测某个cgroup中的线程和某个CPU的线程。 |
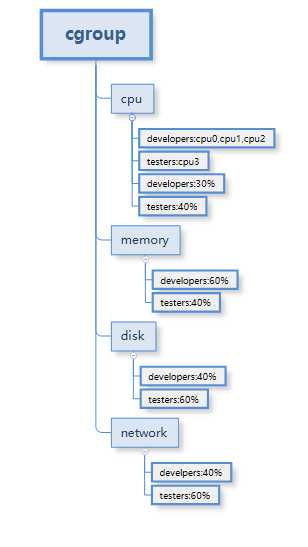
cgroup的资源限定能力如下图所示:
cgroup提供了一个类型为cgroup的特殊文件系统,通过mount命令将这个文件系统安装到系统中某个目录中,就可以在该目录中看到一系列文件。通过向这些文件中写入数据,就可以将应用程序加入到cgroup的控制体系中。
通常会安装到/sys/fs/cgroup目录的子目录中,其中每个子目录都是一个cgroup类型的文件系统,在安装时都通过-o选项指定了特定用途的参数,用以指明cgroup的类型。
1 [u@11 cpu]$ tree -L 1 /sys/fs/cgroup
2 /sys/fs/cgroup
3 ├── blkio
4 ├── cpu -> cpu,cpuacct
5 ├── cpuacct -> cpu,cpuacct
6 ├── cpu,cpuacct
7 ├── cpuset
8 ├── devices
9 ├── freezer
10 ├── hugetlb
11 ├── memory
12 ├── net_cls -> net_cls,net_prio
13 ├── net_cls,net_prio
14 ├── net_prio -> net_cls,net_prio
15 ├── perf_event
16 ├── pids
17 └── systemd
注意事项:
(1) 按照树状结构组织体系中的各种子系统(资源)和具体的cgroup。下图展示了使用cgroup来控制developers和tester两类人员对cpu、内存以及磁盘和网络四种资源的访问。
查看当前进程在哪些cgroup中:
1 root@11 cgroup]# cat /proc/self/cgroup 2 11:perf_event:/ 3 10:cpuset:/ 4 9:devices:/ 5 8:cpuacct,cpu:/ 6 7:net_prio,net_cls:/ 7 6:pids:/ 8 5:memory:/ 9 4:blkio:/ 10 3:hugetlb:/ 11 2:freezer:/ 12 1:name=systemd:/user.slice/user-1000.slice/session-1.scope
提前建立好所需要的目录结构:
1 21:00:44 root@abc /sys/fs#tree -L 1 /sys/fs/cgroup 2 /sys/fs/cgroup 3 ├── blkio 4 ├── cpu,cpuacct 5 ├── cpuset 6 ├── devices 7 ├── freezer 8 ├── hugetlb 9 ├── memory 10 ├── net_cls,net_prio 11 ├── perf_event 12 ├── pids 13 └── systemd
亲和性是指设定进程只能在哪个cpu上运行。通过其它命令也可以实现这个目标,使用cgroup的方式也比较简单易行。
1 mount -t cgroup -o rw,nosuid,nodev,noexec,relatime,cpuset /sys/fs/cgroup/cpuset
这样在/sys/fs/cgroup/cpuset目录下会自动产生一些文件。这个cpuset目录可以认为是cpuset子系统的顶层结构,在旗下可以建立若干个子层,即子目录。比如按照如下方式建立2个控制cpuset资源的cgroup。
1 mkdir /sys/fs/cgroup/cpuset/developers 2 echo 0-2 > /sys/fs/cgroup/cpuset/developers/cpuset.cpus 3 4 mkdir /sys/fs/cgroup/cpuset/testers 5 echo 3 > /sys/fs/cgroup/cpuset/developers/cpuset.cpus
这样就建立了两个cgroup,其中developers组分配的cpu为cpu0,cpu1,cpu2三个cpu(或核心),testers组分配的cpu为cpu3。此时查看到的developers和testers两个目录的目录结构和cpuset目录的基本结构相似,仅仅是developers和testers下没有子目录而已;根据需要,也可以在其下面再次建立子目录,每个新建立的子目都具有相似的基本结构,并自动产生cgroup相关的文件,比如cpuset.cpus、procs、tasks等文件。
下面将指定的进程加入到这两个cgroup中,将该进程的PID写入到相应的tasks文件中即可
1 21:28:00 root@abc /sys/fs/cgroup/cpuset/testers#cat cpuset.cpus 2 3
目前配置testers组的cpu为cpu3。
新启动一个bash,将此进程加入testers组。
1 21:28:17 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 2 PID COMMAND PSR 3 1 myshell --login 3 4 151 ps -eo pid,args,psr 2 5 21:28:30 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 6 PID COMMAND PSR 7 1 myshell --login 3 8 152 ps -eo pid,args,psr 3 9 21:28:34 root@abc /sys/fs/cgroup/cpuset/testers#bash 10 21:28:39 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 11 PID COMMAND PSR 12 1 myshell --login 1 13 153 bash 3 14 162 ps -eo pid,args,psr 2
可以看到,在加入testers组之前,在此新bash中的PID=162的进程使用的cpu(PSR的值可以为cpu2,并不是testers限定的cpu3。
1 21:28:46 root@abc /sys/fs/cgroup/cpuset/testers#echo $$ > tasks 2 bash: echo: write error: No space left on device
出现这个错误是因为没有为此cgroup组指定一个内存资源,将上级结点中的cpuset.mems的值抄写过来就可以。如果只指定了mems,而没有指定cpus,也会出现同样的错误。
1 21:28:54 root@abc /sys/fs/cgroup/cpuset/testers#cat ../cpuset.mems 2 0 3 21:29:07 root@abc /sys/fs/cgroup/cpuset/testers#echo 0 > cpuset.mems 4 21:29:13 root@abc /sys/fs/cgroup/cpuset/testers#echo $$ > tasks 5 21:29:16 root@abc /sys/fs/cgroup/cpuset/testers#cat tasks 6 153 7 164
此时查看在此bash(PID=153)以及其下的子进程,PSR(CPU)全部是cpu3。
1 21:29:19 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 2 PID COMMAND PSR 3 1 myshell --login 1 4 153 bash 3 5 165 ps -eo pid,args,psr 3 6 21:29:30 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 7 PID COMMAND PSR 8 1 myshell --login 1 9 153 bash 3 10 166 ps -eo pid,args,psr 3 11 21:36:25 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 12 PID COMMAND PSR 13 1 myshell --login 1 14 153 bash 3 15 167 ps -eo pid,args,psr 3 16 21:36:26 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 17 PID COMMAND PSR 18 1 myshell --login 1 19 153 bash 3 20 168 ps -eo pid,args,psr 3 21 21:36:27 root@abc /sys/fs/cgroup/cpuset/testers#ps -eo pid,args,psr 22 PID COMMAND PSR 23 1 myshell --login 1 24 153 bash 3 25 169 ps -eo pid,args,psr 3
至此,对于进程的cpu亲和性的限定已经初步完成了,这就相当于可以为该bash进程以及其子进程指定了可以运行的cpu(或核心)。
使用率指进程可以占用指定cpu的运行时间的百分比。
在cpu相关目录下建立一个子目录developers,限定developers的cpu使用率。
1 22:59:25 root@abc /#mkdir /sys/fs/cgroup/cpu,cpuacct/developers3 22:59:41 root@abc /#cat /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_quota_us 4 -1 5 23:00:03 root@abc /#cat /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_period_us 6 100000
两个参数的单位均为微秒。
cpu.cfs_period_us表示一个时间周期,范围为1微秒到1秒。
cpu.cfs_quota_us表示限额,大于等于1微秒即可。当为-1时表示不做限制。
在默认不限定的情况下执行以下脚本:
1 23:10:21 root@abc /#cat busy.sh 2 #!/bin/bash 3 4 let x=0 5 while :; do 6 let x++; 7 done
使用top来查看cpu占用率,busy.sh的cpu使用率为100%。

现在来限定developers组的cpu使用率最多占用1个cpu(核心)的40%。
1 23:13:51 root@abc /#/bin/echo 40000 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_quota_us 2 23:14:13 root@abc /#cat /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_quota_us 3 40000 4 23:14:32 root@abc /#cat /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_period_us 5 100000
新建一个bash并将该bash进程加入developers组。
1 23:16:10 root@abc /#echo $$ > /sys/fs/cgroup/cpu,cpuacct/developers/tasks 2 23:16:50 root@abc /#cat /sys/fs/cgroup/cpu,cpuacct/developers/tasks 3 80 4 93
然后重新运行busy.sh:
1 23:16:58 root@abc /#busy.sh& 2 [1] 94
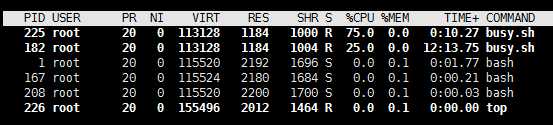
再次使用top查看busy.sh的cpu使用率。此时busy.sh最多只会占用%40的cpu,即一个cpu核心的40%。

如果希望developers组能够使用2个cpu核心,可以进行如下配置:
1 23:30:53 root@abc /#echo 50000 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_period_us 2 23:31:45 root@abc /#echo 100000 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_quota_us
即quota的值为period的值的2倍。在此情况下,top命令显示的%CPU的值仍然为100%,即使2个核心都处于100%使用率的状态。
cpu.cfs_period_us和cpu.cfs_quota_us限定cpu使用率的绝对值,cpu.shares参数则限定cpu使用率的相对值,即在各个cgroup组之间的cpu使用率的绝对值之和超过了系统的有效的cpu能提供的计算能力时,解决cpu资源如何在各个cgroup组之间分配的问题。
下面建立一个场景来测试在tester组和developers组都仅能使用cpu0,而且二者的shares都是1024的情况:
建立cpuset子系统的testers组,限定使用cpu0,并将当前bash加入testers组。
1 23:56:52 root@abc /#mkdir /sys/fs/cgroup/cpuset/testers 2 23:57:19 root@abc /#echo 0 > /sys/fs/cgroup/cpuset/testers/cpuset.mems 3 23:57:35 root@abc /#echo 0 > /sys/fs/cgroup/cpuset/testers/cpuset.cpus 4 23:57:57 root@abc /#echo $$ > /sys/fs/cgroup/cpuset/testers/tasks
建立cpu子系统的tester组,限定cpu使用率的相对值share为1024(默认值),并将当前bash加入testers组。
1 00:04:03 root@abc /#echo 1024 > /sys/fs/cgroup/cpu,cpuacct/testers/cpu.shares 2 00:04:32 root@abc /#echo $$ > /sys/fs/cgroup/cpu,cpuacct/testers/tasks 3 00:05:21 root@abc /#./busy.sh& 4 [1] 182
按照同样的办法,建立cpuset和cpu两个子系统下的developers组。同样建立一个新的bash进程加入developers组。
1 00:08:17 root@abc /#mkdir /sys/fs/cgroup/cpuset/developers 2 00:08:33 root@abc /#echo 0 > /sys/fs/cgroup/cpuset/developers/cpuset.mems 3 00:08:48 root@abc /#echo 0 > /sys/fs/cgroup/cpuset/developers/cpuset.cpus 4 00:08:54 root@abc /#echo $$ > /sys/fs/cgroup/cpuset/developers/tasks 5 6 00:09:51 root@abc /#mkdir /sys/fs/cgroup/cpu,cpuacct/developers 7 00:11:01 root@abc /#echo 1024 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.shares 8 00:11:18 root@abc /#echo $$ > /sys/fs/cgroup/cpu,cpuacct/developers/tasks
在此新bash下执行busy.sh。
此时使用top查看,尽管cpu子系统下的两个cgroup组testers,developers都未做cpus使用率的绝对值的限定,在cpuset子系统限定二者都只能使用cpu0的情况下,cpu子系统下的shares参数值又是相同的(1024),也就是二者机会均等,因此两个组中的进程的cpu占用之和不会超过1个cpu核心的全部计算能力,即100%。

如果希望developers组的cpu占用率是testers组的3倍,则可以修改developers组的cpus.shares参数的值为testers组的3倍。
1 00:19:31 root@abc /#echo 3072 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.shares 2 00:20:42 root@abc /#echo $$ > /sys/fs/cgroup/cpu,cpuacct/developers/tasks
cpu.shares参数只有在指定的cpu核心处于满负荷运行(100%)仍然不能满足cpu.cfs_quota_us参数的要求的情况下有效,在cpu核心未处于满负荷运行时,cpu使用率由cpu.cfs_quota_us控制。
比如讲cpu.cfs_quota_us设置为40%和30%,由于总共都没超过100%,因此cpu.shares参数将不会起作用。
1 00:24:43 root@abc /#echo 40000 > /sys/fs/cgroup/cpu,cpuacct/developers/cpu.cfs_quota_us 2 00:25:14 root@abc /#echo 30000 > /sys/fs/cgroup/cpu,cpuacct/testers/cpu.cfs_quota_us

通过对memory子系统的控制,可以限制进程对内存资源的占用。通过设置memory.limit_in_bytes参数控制进程使用的最大内存数量,memory.swmem.limit_in_bytes控制进程使用的内存和交换区的最大数量。
以下两个命令设置进程能使用的最大内存为100MB。
1 00:53:11 root@abc /#echo 100M > /sys/fs/cgroup/memory/developers/memory.memsw.limit_in_bytes 2 00:53:23 root@abc /#echo 100M > /sys/fs/cgroup/memory/developers/memory.limit_in_bytes
将当前bash进程加入developers组
1 echo $$ > /sys/fs/cgroup/memory/developers/tasks
使用下面的代码来创建一个测试程序:
1 cat memory.cpp 2 #include <stdio.h> 3 #include <memory.h> 4 #include <stdlib.h> 5 6 int main(int argc, char ** argv) 7 { 8 int size = atoi( argv[1]); 9 char *p = new char[size]; 10 printf("size:{%d} p:{%p}\r\n", size, p); 11 if(NULL!= p) 12 { 13 memset(p, 0, size); 14 printf("memset ok.\r\n"); 15 } 16 delete p; 17 return 0; 18 }
分别测试分配100000000字节(未超过100MB)和150000000字节(超过100MB)的执行情况
1 00:54:54 root@abc /#./memory 100000000 2 size:{100000000} p:{0x7efeebcb5010} 3 memset ok.
当分配少于100MB的内存时,执行成功,分配成功,对内存的访问成功。
1 00:54:56 root@abc /#./memory 150000000 2 size:{150000000} p:{0x7fde74727010} 3 Killed
当分配多于100MB的内存时,执行失败:分配成功,但是对内存的访问失败。触发了Linux的OOM Killer机制。
下面的测试结果说明memory.memsw.limit_in_bytes起到决定性限制作用
1 00:57:30 root@abc /#echo 200M > /sys/fs/cgroup/memory/developers/memory.memsw.limit_in_bytes 2 01:06:43 root@abc /#echo 100M > /sys/fs/cgroup/memory/developers/memory.limit_in_bytes 3 01:06:56 root@abc /#./memory 150000000 4 size:{150000000} p:{0x7fcf21d5d010} 5 memset ok. 6 01:07:08 root@abc /#./memory 250000000 7 size:{250000000} p:{0x7fdaa0e94010} 8 Killed
cgroup对于内存的使用限制,是对一个cgroup组的所有进程的内存使用总量进行限制,而不是对单个进程进行限制。将前面的代码稍微改造之后,结果更为明显:
1 cat memory.cpp 2 #include <unistd.h> 3 #include <sys/types.h> 4 #include <stdio.h> 5 #include <memory.h> 6 #include <stdlib.h> 7 8 int main(int argc, char ** argv) 9 { 10 int size = atoi( argv[1]); 11 char *p = new char[size]; 12 printf("{%d} size:{%d} p:{%p}\r\n", (int)getpid(),size, p); 13 if(NULL!= p) 14 { 15 memset(p, 0, size); 16 printf("{%d} memset ok.\r\n" , (int)getpid()); 17 fflush(stdout); 18 } 19 printf("{%d} sleeping 10s...\r\n", (int)getpid()); 20 sleep(10); 21 printf("{%d} done.\r\n",(int)getpid()); 22 delete p; 23 return 0; 24 }
在10秒之内在同一个cgroup组内启动两个进程,各自分配200MB内存,各自独立看均不违反cgroup的内存限制(200MB),但是总量(400MB)超出限制了。
1 01:26:22 root@abc /#./memory 200000000& 2 [1] 1048 3 01:26:25 root@abc /#{1048} size:{200000000} p:{0x7f3b14600010} 4 ./memory 200000000&{1048} memset ok. 5 {1048} sleeping 10s... 6 7 [2] 1049 8 01:26:26 root@abc /#{1049} size:{200000000} p:{0x7fea573b4010} 9 {1049} memset ok. 10 {1049} sleeping 10s... 11 12 [1]- Killed ./memory 200000000 13 01:26:28 root@abc /#{1049} done. 14 15 [2]+ Done ./memory 200000000
在第2次运行中,输出了memset ok之后才被kill掉,说明OOM Killer似乎并不是实时进行控制的,而是有一定延迟。
cgroup的memory子系统是否使用OOM killer机制,取决于下面这个文件的配置
1 01:30:36 root@abc /#cat /sys/fs/cgroup/memory/developers/memory.oom_control 2 oom_kill_disable 0 3 under_oom 0
当oom_kill_diable设置为0时,表示启用OOM,否则禁用OOM。
(a)限制对磁盘的读取速度。
在不限制的情况下,读取磁盘/dev/sda的速度达到了90MB/S
1 02:15:10 root@abc /#dd if=/dev/sda of=/dev/null bs=1000000& 2 [1] 4706 3 02:15:31 root@abc /#iostat -d -m sda 1 4 Linux 3.10.0-693.21.1.el7.x86_64 (abc) 05/01/2018 _x86_64_ (4 CPU) 5 6 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 7 sda 9.72 2.78 0.72 59669 15351 8 9 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 10 sda 80.00 39.00 0.02 39 0 11 12 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 13 sda 94.00 47.00 0.00 47 0 14 15 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 16 sda 89.00 44.50 0.00 44 0 17 18 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 19 sda 98.00 49.00 0.00 49 0 20 21 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 22 sda 106.00 53.00 0.00 53 0 23 24 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 25 sda 86.00 43.00 0.00 43 0 26 27 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 28 sda 72.00 36.00 0.00 36 0
现在使用cgroup的blkio子系统限制一下读取磁盘的速度。
1 02:16:40 root@abc /#echo ‘8:0 1000000‘ > /sys/fs/cgroup/blkio/developers/blkio.throttle.read_bps_device 2 02:17:00 root@abc /#echo $$ > /sys/fs/cgroup/blkio/developers/tasks
再次执行同样的操作,来测试现在的磁盘读取速度
1 02:17:19 root@abc /#dd if=/dev/sda of=/dev/null bs=1000000& 2 [1] 4711 3 02:17:28 root@abc /#iostat -d -m sda 1 4 Linux 3.10.0-693.21.1.el7.x86_64 (abc) 05/01/2018 _x86_64_ (4 CPU) 5 6 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 7 sda 9.71 2.79 0.71 60161 15351 8 9 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 10 sda 2.00 1.00 0.00 1 0 11 12 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 13 sda 2.00 1.00 0.00 1 0 14 15 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 16 sda 2.00 1.00 0.00 1 0 17 18 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 19 sda 2.00 1.00 0.00 1 0 20 21 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 22 sda 2.00 1.00 0.00 1 0 23 24 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 25 sda 2.00 1.00 0.00 1 0 26 27 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 28 sda 2.00 1.00 0.00 1 0
在使用blkio.throttle.read_bps_device参数限定读取速度最大为1MB之后,iostat的输出显示基本上在1MB/S。
(b)cgroup的blkio子系统可以从以下几个方面来限制对磁盘的访问。
blkio.throttle.read_bps_device 限制磁盘读取速度:单位:字节/秒。
blkio.throttle.read_iops_device 限制磁盘读取速度:单位:IO/秒。
blkio.throttle.write_bps_device 限制磁盘写速度:单位:字节/秒。
blkio.throttle.write_iops_device 限制磁盘写速度:单位:IO/秒。
blkio.weight:设置该组的总权重,不区分设备。相对值,类似于cpus.shares参数。
blkio.weight_device:设置该组对指定磁盘设备的权重。
(c)测试cgroup对磁盘写操作的限制功能。
先取消对磁盘的读取限制。
1 02:17:42 root@abc /#echo ‘8:0 0‘ > /sys/fs/cgroup/blkio/developers/blkio.throttle.read_bps_device
在没有读和写限制的情况下,测试写操作。在测试写操作时必须加上oflag=sync参数来消除缓存的影响。
1 02:53:09 root@abc /#dd if=/dev/zero of=/test.data oflag=sync& 2 [1] 4749 3 02:53:16 root@abc /#iostat -d -m sda 1 4 Linux 3.10.0-693.21.1.el7.x86_64 (abc) 05/01/2018 _x86_64_ (4 CPU) 5 6 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 7 sda 11.83 2.54 1.55 60217 36759 8 9 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 10 sda 2612.00 0.00 7.03 0 7 11 12 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 13 sda 2720.00 0.00 7.30 0 7 14 15 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 16 sda 2525.00 0.00 6.78 0 6 17 18 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 19 sda 2504.00 0.00 6.72 0 6 20 21 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 22 sda 2797.00 0.00 7.54 0 7 23 24 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 25 sda 2646.00 0.00 7.10 0 7 26 27 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 28 sda 2598.00 0.00 6.98 0 6
添加对写操作的速度限制:
1 02:53:34 root@abc /#echo ‘8:0 1000000‘ > /sys/fs/cgroup/blkio/developers/blkio.throttle.write_bps_device
再次执行写操作的测试。
1 02:54:39 root@abc /#dd if=/dev/zero of=/test.data oflag=sync& 2 [1] 4753 3 02:54:43 root@abc /#iostat -d -m sda 1 4 Linux 3.10.0-693.21.1.el7.x86_64 (abc) 05/01/2018 _x86_64_ (4 CPU) 5 6 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 7 sda 12.94 2.53 1.55 60217 36832 8 9 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 10 sda 390.00 0.00 0.95 0 0 11 12 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 13 sda 379.00 0.00 0.96 0 0 14 15 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 16 sda 355.00 0.00 0.95 0 0 17 18 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 19 sda 356.00 0.00 0.96 0 0 20 21 Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn 22 sda 354.00 0.00 0.95 0 0
写入速度基本在1MB/S左右。
Linux的网络流量控制(Traffic Control)基于Linux内核的流量控制功能。cgroup在限制网络IO访问时,也是使用Linux内核的流量控制功能。主要目的是限制从本地外发送出去的数据包的带宽。
假定网卡eth0的带宽为100Mbits,现在需要在cgroup中限制某个组的带宽为10Mbits,可以按照如下步骤来实现这个目标。
(a)为网卡eth0建立一个qdisc队列。
使用tc命令行工具完成这个操作,总带宽为100Mbits。
1 tc qdisc add dev eth0 root handle 1: htb default 100
(b)建立一系列规则类别。
使用HTB模式的队列,即基于令牌桶的规则,内核定时向桶中放入令牌,而发送数据包时则取走相应的令牌,通过对桶中令牌数量的控制达到流量控制的目标。
1 05:07:04 root@abc /#tc class add dev eth0 parent 1: classid 1:1 htb rate 100 2 05:08:38 root@abc /#tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10 3 05:09:21 root@abc /#tc class add dev eth0 parent 1:1 classid 1:20 htb rate 20 4 05:09:37 root@abc /#tc class add dev eth0 parent 1:1 classid 1:40 htb rate 40
其中,classid参数指定类别的ID,这个值将会用于cgroup的参数中。这里创建了一个根类别1:1 (100Mbits),旗下有3个子类别: 1:10 (10Mbits) , 1:20 (20Mbits), 1:40 (40Mbits)。
(c)在cgroup中指定classid。
1 05:37:18 root@abc /#mkdir /sys/fs/cgroup/net_cls,net_prio/developers 2 05:37:44 root@abc /#echo 0x00010010 > /sys/fs/cgroup/net_cls,net_prio/developers/net_cls.classid 3 05:38:58 root@abc /#echo $$ > /sys/fs/cgroup/net_cls,net_prio/developers/tasks
在net_cls.classid文件中的格式为0xAAAABBBB,AAAA为冒号前面的部分,BBBB为冒号后面的部分,对应于前面tc class add 命令中的classid参数。
这里为developers组指定的类别ID为0x00010010,即classid为1:10,限速为10,即10Mbits,大约1.25MBytes/S。
(d)创建一个cgroup过滤器。
1 tc filter add dev eth0 parent 1: protocol ip prio 1 handle 1: cgroup
至此,可以使用scp命令上传文件到其它主机的方式来测试网络带宽的限速功能。
1 05:45:59 root@abc /#scp t1.tar u@11.1.1.11:/home/u/. 2 u@11.1.1.11‘s password: 3 t1.tar 4% 59MB 1.2MB/s 18:44 ETA^
可以看到scp显示的网速为1.2MB/S,大约就是10MBits/S。
将net_cls.classid中的值修改为0x00010020后重新测试。
1 05:46:57 root@abc /#echo 0x00010020 > /sys/fs/cgroup/net_cls,net_prio/developers/net_cls.classid 2 05:47:41 root@abc /#scp t1.tar u@11.1.1.11:/home/u/. 3 u@11.1.1.11‘s password: 4 t1.tar 11% 160MB 2.2MB/s 09:11 ETA^
可以看到网速限定为2.2MB/S,大约20Mbits/S。
实际测试发现,流量控制并不是将带宽绝对限定在低于指定的速度的状态,而是缓慢的降低到指定的速度。
目前只能对发送数据进行流量控制,对下载速度无法控制。
总结:
本博客介绍了在我们的mydocker.sh脚本创建的容器中提供资源限制功能的相关概念和操作步骤,主要是cgroup技术以及相关工具包括tc流量控制工具的使用。这也是Linux容器技术(LXC)提供的功能,也正是Docker使用的技术之一。后续有机会将继续探索Docker中使用的其它技术。
Docker02:Docker核心技术探索(9)使用cgroup限制资源的使用
标签:状态 .sh memset cpp 能力 print uid mil 最大数
原文地址:https://www.cnblogs.com/coe2coe/p/8975389.html