收集日志的目的是有效的利用日志,有效利用日志的前提是日志经过格式化符合我们的要求,这样才能真正的高效利用收集到elasticsearch平台的日志。默认的日志到达elasticsearch 是原始格式,乱的让人抓狂,这个时候你会发现Logstash filter的可爱之处,它很像一块橡皮泥,如果我们手巧的话就会塑造出来让自己舒舒服服的作品,but 如果你没搞好的话那就另说了,本文的宗旨就是带你一起飞,搞定这块橡皮泥。当你搞定之后你会觉得kibana 的世界瞬间清爽了很多!
FIlebeat 的4大金刚
Filebeat 有4个非常重要的概念需要我们知道,
Prospector(矿工);
Harvest (收割者);
libeat (汇聚层);
registry(注册计入者);
Prospector 负责探索日志所在地,就如矿工一样要找矿,而Harvest如矿主一样的收割者矿工们的劳动成果,哎,世界无处不剥削啊!每个Prospector 都有一个对应的Harvest,然后他们有一个共同的老大叫做Libbeat,这个家伙会汇总所有的东西,然后把所有的日志传送给指定的客户,这其中还有个非常重要的角色”registry“,这个家伙相当于一个会计,它会记录Harvest 都收割了些啥,收割到哪里了,这样一但有问题了之后,harvest就会跑到会计哪里问:“上次老子的活干到那块了”?Registry 会告诉Harvest 你Y的上次干到哪里了,去哪里接着干就行了。这样就避免了数据重复收集的问题!
filebeat.prospectors:
- input_type: log
enabled: True
paths:
- /var/log/mysql-slow-*
#这个地方是关键,我们给上边日志加上了tags,方便在logstash里边通过这个tags 过滤并格式化自己想要的内容;
tags: ["mysql_slow_logs"]
#有的时候日志不是一行输出的,如果不用multiline的话,会导致一条日志被分割成多条收集过来,形成不完整日志,这样的日志对于我们来说是没有用的!通过正则匹配语句开头,这样multiline 会在匹配开头
之后,一直到下一个这样开通的语句合并成一条语句。
#pattern:多行日志开始的那一行匹配的pattern
#negate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为false
#match:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
#max_lines:合并的最多行数(包含匹配pattern的那一行 默认值是500行
#timeout:到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去
multiline.pattern: ‘^\d{4}/\d{2}/\d{2}‘ (2018\05\01 我的匹配是已这样的日期开头的)
multiline.negate: true
multiline.match: after
multiline.Max_lines:20
multiline.timeout: 10s
- input_type: log
paths:
- /var/log/mysql-sql-*
tags: ["mysql_sql_logs"]
multiline.pattern: ‘^\d{4}/\d{2}/\d{2}‘
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
encoding: utf-8
document_type: mysql-proxy
scan_frequency: 20s
harverster_buffer_size: 16384
max_bytes: 10485760
tail_files: true
#tail_files:如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。默认是false;input {
kafka {
topics_pattern => "mysql.*"
bootstrap_servers => "x.x.x.x:9092"
#auto_offset_rest => "latest"
codec => json
group_id => "logstash-g1"
}
}
#终于到了关键的地方了,logstash的filter ,使用filter 过滤出来我们想要的日志,
filter {
#if 还可以使用or 或者and 作为条件语句,举个栗子: if “a” or “b” or “c” in [tags],这样就可以过滤多个tags 的标签了,我们这个主要用在同型号的交换设备的日志正规化,比如说你有5台交换机,把日志指定到了同一个syslog-ng 上,收集日志的时候只能通过同一个filebeat,多个prospector加不同的tags。这个时候过滤就可以通过判断相应的tags来完成了。
if "mysql_slow_logs" in [tags]{
grok {
#grok 里边有定义好的现场的模板你可以用,但是更多的是自定义模板,规则是这样的,小括号里边包含所有一个key和value,例子:(?<key>value),比如以下的信息,第一个我定义的key是data,表示方法为:?<key> 前边一个问号,然后用<>把key包含在里边去。value就是纯正则了,这个我就不举例子了。这个有个在线的调试库,可以供大家参考,http://grokdebug.herokuapp.com/
match => { "message" => "(?<date>\d{4}/\d{2}/\d{2}\s(?<datetime>%{TIME}))\s-\s(?<status>\w{2})\s-\s(?<respond_time>\d+)\.\d+\w{2}\s-\s%{IP:client}:(?<client-port>\d+)\[\d+\]->%{IP:server}:(?<server-port>\d+).*:(?<databases><\w+>):(?<SQL>.*)"}
#过滤完成之后把之前的message 移出掉,节约磁盘空间。
remove_field => ["message"]
}
}
else if "mysql_sql_logs" in [tags]{
grok {
match => { "message" => "(?<date>\d{4}/\d{2}/\d{2}\s(?<datetime>%{TIME}))\s-\s(?<status>\w{2})\s-\s(?<respond_time>\d+\.\d+)\w{2}\s-\s%{IP:client}:(?<client-port>\d+)\[\d+\]->%{IP:server}:(?<server-port>\d+).*:(?<databases><\w+>):(?<SQL>.*)"}
remove_field => ["message"]}
}
}2018/05/01 16:16:01.892 - OK - 759.2ms - 172.29.1.7:35184[485388]->172.7.1.39:3306[1525162561129639717]:<DB>:select count(*) from test[];
过滤后的结果如下:
{
"date": [
[
"2018/05/01 16:16:01.892"
]
],
"datetime": [
[
"16:16:01.892"
]
],
"TIME": [
[
"16:16:01.892"
]
],
"HOUR": [
[
"16"
]
],
"MINUTE": [
[
"16"
]
],
"SECOND": [
[
"01.892"
]
],
"status": [
[
"OK"
]
],
"respond_time": [
[
"759"
]
],
"client": [
[
"172.29.1.7"
]
],
"IPV6": [
[
null,
null
]
],
"IPV4": [
[
"172.29.1.7",
"172.7.1.39"
]
],
"client-port": [
[
"35184"
]
],
"server": [
[
"172.7.1.39"
]
],
"server-port": [
[
"3306"
]
],
"databases": [
[
"<DB>"
]
],
"SQL": [
[
"select count(*) from test[];"
]
]
}#有图有真相: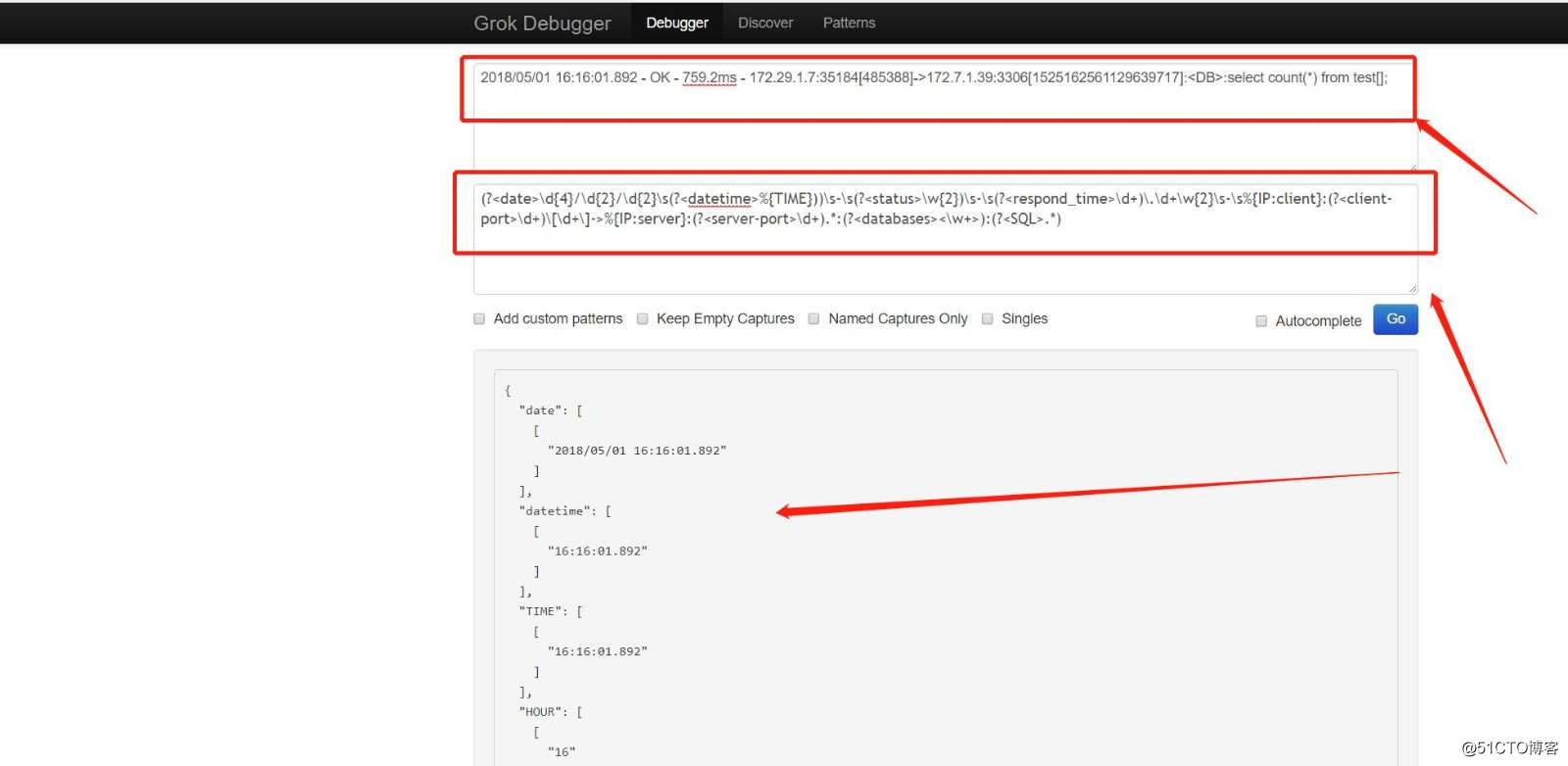
ELK 之Filebeat 结合Logstash 过滤出来你想要的日志
原文地址:http://blog.51cto.com/seekerwolf/2110174