标签:联想 lips info 运用 cli 使用 little 指导书 大数据
使用了eclipse里面的Metrics和AmaterasUML插件生成量化图和类图
第五次作业:
度量:
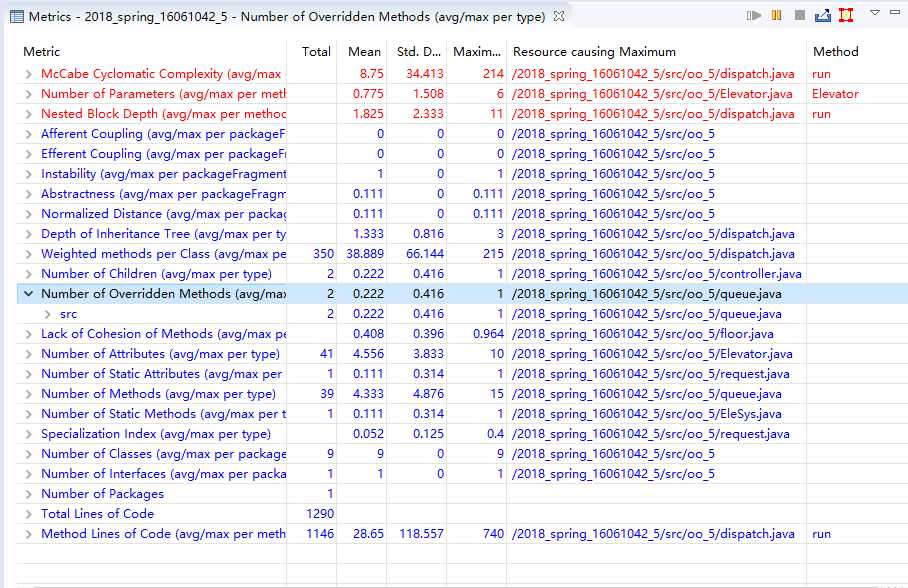
类图:
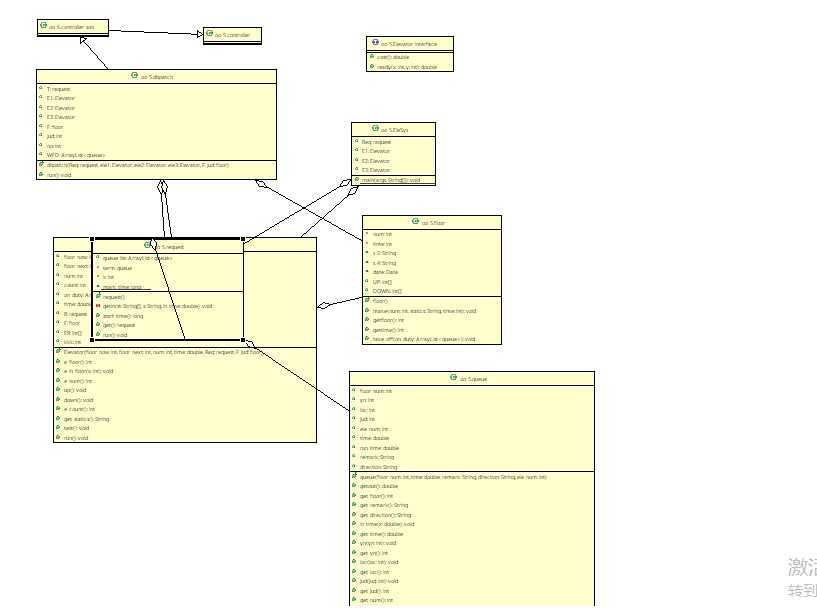
第六次作业:
度量:
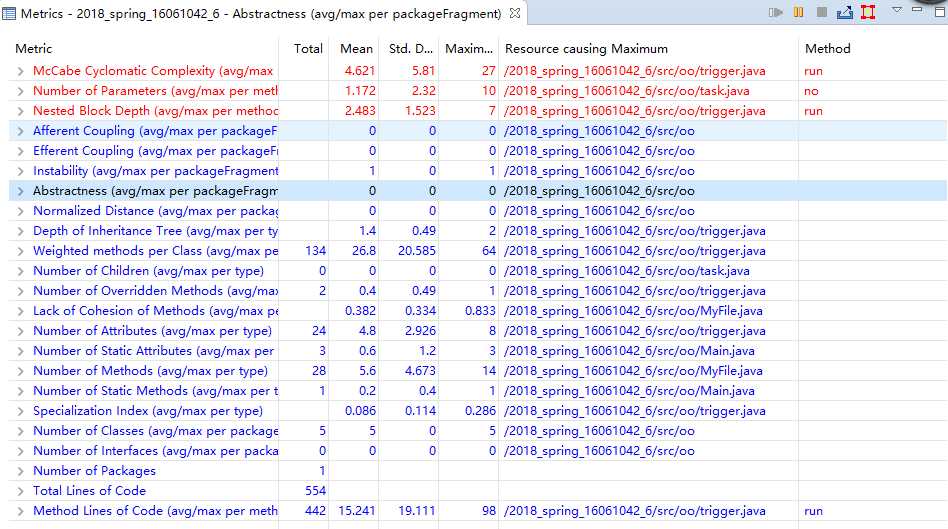
类图:
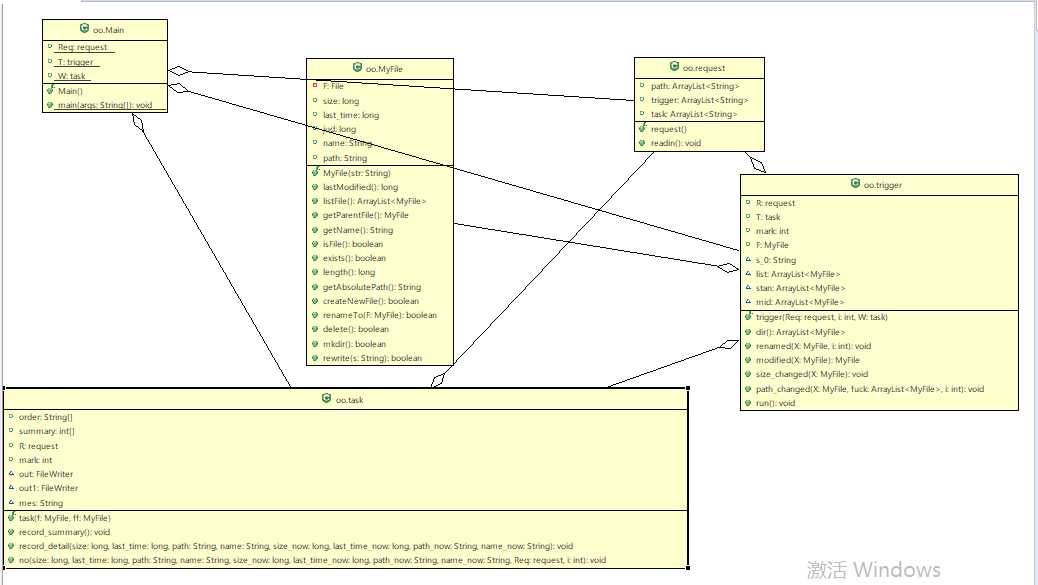
第七次作业:
度量:
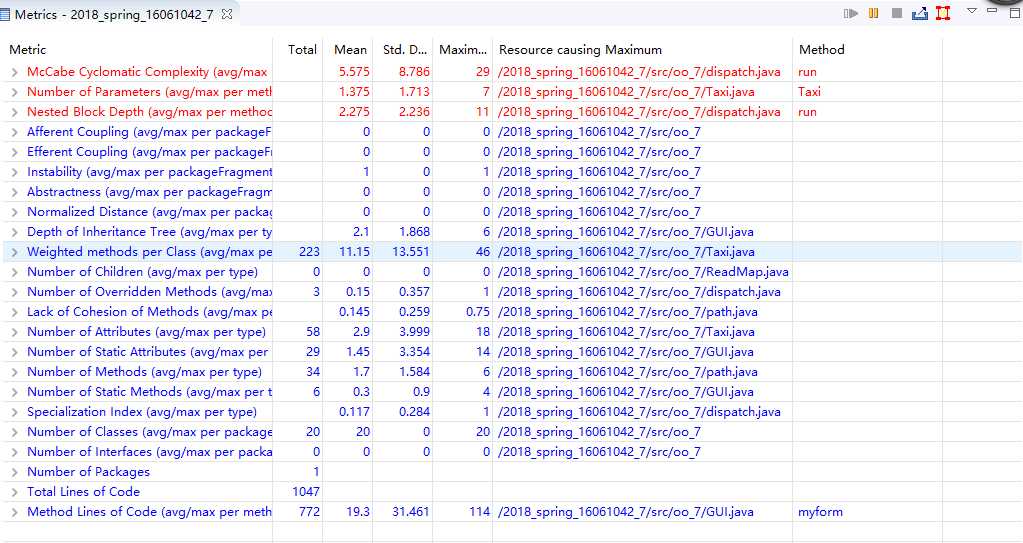
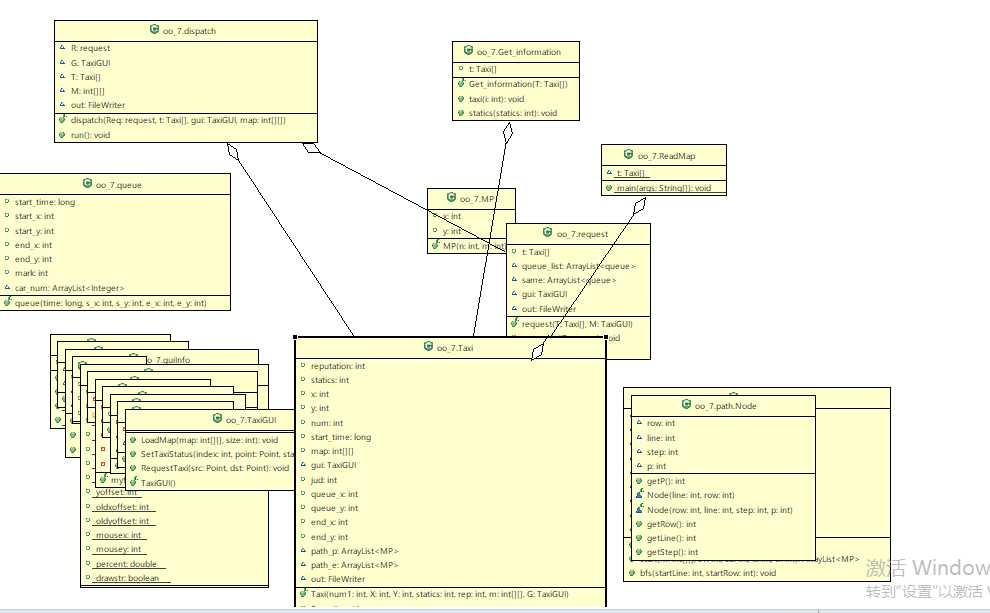
类图:
第五次作业在公测中出的bug主要的原因我第一次运用多线程,对它的理论还不是很清楚,所以公测中出现了一些错误。
第六次作业在公测中出现的bug属于被他报在了公测外面。。。。
第七次作业在公测中是我没有仔细的阅读指导书,漏掉了一个点。
程序的设计应该考虑到分类树中的所有情况,分类树是程序设计的指引,bug是分类树的体现,一但程序设计上与分类树出现了出入,那么肯定会出现bug。而bug出现的位置与程序设计的结构密切相关,bug出现的位置大多数在程序设计逻辑混乱的地方,所以为了减少bug,应该好好了解分类树,使自己的程序设计尽量清晰。
首先加大样例的规格,进行一波数据检查,有的时候程序在大数据的时候就会产生一些平时简单样例不会产生的bug。但是这些不会完全检查出所有的bug,所以这只是刚刚拿到程序时进行的压力测试。
通过分支数的提供的思路,进行仔细的分布检验,检验被测试程序是否支持每一个分支,进行细致分部检查。这样适合局部的检查,只检查具体分支的bug。
在这三次作业中关于多线程程序的设计上我取得了一些心得体会。
多线程在书写的时候要联想到我们的生活中来理解,我们的生活中就是多线程的操作,只要将我们的程序与生活中联系起来,就很容易理解多线程;但多线程的debug还是非常的复杂,只能通过自己的理解和程序的输出来进行。同时每一次进行写程序时,一定要仔细阅读指导书,仔细阅读。
总的来说,在编写程序时一定要做到 A Little Smart!
标签:联想 lips info 运用 cli 使用 little 指导书 大数据
原文地址:https://www.cnblogs.com/yangfenghaha/p/8971360.html