标签:lin ima 页面 cas model nes average 列表 des
存储使用mysql,增量更新东方头条全站新闻的标题 新闻简介 发布时间 新闻的每一页的内容 以及新闻内的所有图片。项目文件结构。
这是run.py的内容
1 #coding=utf-8
2 from scrapy import cmdline
3 import redis,time,threading
4 from multiprocessing import Process
5 #import scrapy.log
6
7 #cmdline.execute("scrapy crawl baoxian -s LOG_FILE=scrapy10.log".split())
8
9 #scrapy crawl myspider -s LOG_FILE=scrapy2.log
10
11
12 start_urls = [‘http://mini.eastday.com/‘,
13 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0010¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=170603095010319,170603093955594-2,170603093955594&jsonpcallback=jQuery18303164258797187358_1496455837718&_=1496455838146‘, #国内
14 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0011¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=170603142336718-2,170603142336718,170603122752716&jsonpcallback=jQuery18307262756496202201_1496477922458&_=1496477923254‘, #国际
15 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0005¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18302500620267819613_1496483754044&_=1496483755277‘,#军事
16 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0003¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery183026658024708740413_1496480575988&_=1496480576634‘,#社会
17 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0002¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery1830691694314358756_1496480816841&_=1496480817500‘,#娱乐
18 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0019¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18303703077440150082_1496480892188&_=1496480892581‘,#健康
19 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0015¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery183023222095426172018_1496480961781&_=1496480962307‘,#时尚
20 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0008¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery183017557532875798643_1496481013410&_=1496481013824‘,#科技
21 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0012¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18308183211348950863_1496481106550&_=1496481106993‘,#汽车
22 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0018¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18309359942991286516_1496481227742&_=1496481228242‘,#人文
23 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0007¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery183019699203735217452_1496481313637&_=1496481314077‘,#游戏
24 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0020¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18307782149398699403_1496481413006&_=1496481413401‘,#星座
25 ‘http://ttpc.dftoutiao.com/jsonpc/refresh?type=0021¶m=null%0914963741798389872%09toutiao%09DFTT%091&readhistory=n170603081129137,n170603071002231,170603142336718-2&jsonpcallback=jQuery18306590236281044781_1496481467020&_=1496481467496‘,#家居
26
27 ]
28
29 r = redis.Redis(host=‘127.0.0.1‘,port=6379,db=0)
30
31
32
33 def check_redis_requsts():
34 while(1):
35 ‘‘‘
36 for url in start_urls:
37 r.rpush(‘eastdayspider:start_urls‘,url)
38 print u‘插入到start_urls的:‘,r.lrange(‘eastdayspider:start_urls‘,0,-1)
39 ‘‘‘
40 for url in start_urls:
41 r.sadd(‘eastdayspider:start_urls‘,url)
42 print u‘插入到start_urls的:‘,r.smembers(‘eastdayspider:start_urls‘)
43
44 count=0
45 while (count<30):
46 if r.exists(‘eastdayspider:requests‘):
47 time.sleep(60)
48 count=0
49 else:
50 count+=1
51 time.sleep(10)
52
53 def run_spider():
54 cmdline.execute("scrapy crawl eastdayspider".split())
55
56
57 if __name__==‘__main__‘:
58 pass
59
60
61 p1= Process(target=check_redis_requsts)
62 p2=Process(target=run_spider)
63
64 p1.start()
65 time.sleep(5)
66 p2.start()
67
68 p1.join()
69 p2.join()
这是settings.py
1 # -*- coding: utf-8 -*-
2
3 # Scrapy settings for eastday project
4 #
5 # For simplicity, this file contains only settings considered important or
6 # commonly used. You can find more settings consulting the documentation:
7 #
8 # http://doc.scrapy.org/en/latest/topics/settings.html
9 # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
10 # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
11
12 BOT_NAME = ‘eastday‘
13
14 SPIDER_MODULES = [‘eastday.spiders‘]
15 NEWSPIDER_MODULE = ‘eastday.spiders‘
16
17 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
18 SCHEDULER = "scrapy_redis.scheduler.Scheduler"
19 REDIS_START_URLS_AS_SET=True #shezhi strat_urls键是集合,默认是false是列表
20 SCHEDULER_PERSIST = True
21
22 DEPTH_PRIORITY=0
23 RETRY_TIMES = 20
24
25 IMAGES_STORE = ‘d:/‘
26 IMAGES_EXPIRES = 90
27
28 REDIS_HOST = ‘localhost‘
29 REDIS_PORT = 6379
30 # Crawl responsibly by identifying yourself (and your website) on the user-agent
31 #USER_AGENT = ‘eastday (+http://www.yourdomain.com)‘
32
33 # Obey robots.txt rules
34 ROBOTSTXT_OBEY = False
35
36 # Configure maximum concurrent requests performed by Scrapy (default: 16)
37 CONCURRENT_REQUESTS = 10
38
39 # Configure a delay for requests for the same website (default: 0)
40 # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
41 # See also autothrottle settings and docs
42 DOWNLOAD_DELAY = 0
43 # The download delay setting will honor only one of:
44 #CONCURRENT_REQUESTS_PER_DOMAIN = 16
45 #CONCURRENT_REQUESTS_PER_IP = 16
46
47 # Disable cookies (enabled by default)
48 #COOKIES_ENABLED = False
49
50 # Disable Telnet Console (enabled by default)
51 #TELNETCONSOLE_ENABLED = False
52
53 # Override the default request headers:
54 #DEFAULT_REQUEST_HEADERS = {
55 # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
56 # ‘Accept-Language‘: ‘en‘,
57 #}
58
59 # Enable or disable spider middlewares
60 # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
61 #SPIDER_MIDDLEWARES = {
62 # ‘eastday.middlewares.EastdaySpiderMiddleware‘: 543,
63 #}
64
65 # Enable or disable downloader middlewares
66 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
67
68 DOWNLOADER_MIDDLEWARES = {
69 "eastday.middlewares.UserAgentMiddleware": 401,
70 #"eastday.middlewares.CookiesMiddleware": 402,
71 }
72
73
74
75 # Enable or disable extensions
76 # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
77 #EXTENSIONS = {
78 # ‘scrapy.extensions.telnet.TelnetConsole‘: None,
79 #}
80
81 # Configure item pipelines
82 # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
83 ITEM_PIPELINES = {
84 #‘eastday.pipelines.EastdayPipeline‘: 300,
85 ‘eastday.pipelines.MysqlDBPipeline‘:400,
86 ‘eastday.pipelines.DownloadImagesPipeline‘:200,
87 #‘scrapy_redis.pipelines.RedisPipeline‘: 400,
88
89 }
90
91 # Enable and configure the AutoThrottle extension (disabled by default)
92 # See http://doc.scrapy.org/en/latest/topics/autothrottle.html
93 #AUTOTHROTTLE_ENABLED = True
94 # The initial download delay
95 #AUTOTHROTTLE_START_DELAY = 5
96 # The maximum download delay to be set in case of high latencies
97 #AUTOTHROTTLE_MAX_DELAY = 60
98 # The average number of requests Scrapy should be sending in parallel to
99 # each remote server
100 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
101 # Enable showing throttling stats for every response received:
102 #AUTOTHROTTLE_DEBUG = False
103
104 # Enable and configure HTTP caching (disabled by default)
105 # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
106 #HTTPCACHE_ENABLED = True
107 #HTTPCACHE_EXPIRATION_SECS = 0
108 #HTTPCACHE_DIR = ‘httpcache‘
109 #HTTPCACHE_IGNORE_HTTP_CODES = []
110 #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
这是pipelines.py,里面有建表文件。里面有个mysql检查url是否存在的语句,其实是多余的。因为url已经在redis中去重了。
1 # -*- coding: utf-8 -*-
2
3 # Define your item pipelines here
4 #
5 # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
7 import time,json,pymysql,re
8 from items import EastdayItem
9 from scrapy import Request
10 from scrapy.pipelines.images import ImagesPipeline
11 from scrapy.exceptions import DropItem
12
13
14 ‘‘‘
15 CREATE TABLE `eastday` (
16 `id` INT(10) NOT NULL AUTO_INCREMENT,
17 `title` VARCHAR(255) DEFAULT NULL,
18 `url` VARCHAR(80) DEFAULT NULL,
19 `tag` VARCHAR(30) DEFAULT NULL,
20 `brief` VARCHAR(300) DEFAULT NULL,
21 pubdate DATETIME,
22 origin VARCHAR(50),
23 crawled_time DATETIME,
24
25 `miniimg` VARCHAR(500) DEFAULT NULL,
26 `img_urls` TEXT,
27 `article` TEXT,
28 PRIMARY KEY (`id`)
29 ) ENGINE=INNODB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
30 ‘‘‘
31
32 class EastdayPipeline(object):
33
34 def process_item(self, item, spider):
35 print ‘----------------------------%s‘%json.dumps(dict(item),ensure_ascii=False)
36 item["crawled_time"] = time.strftime(‘%Y-%m-%d %H:%M:%S‘, time.localtime(time.time()))
37 return item
38
39
40 class MysqlDBPipeline(object):
41 def __init__(self):
42
43
44 self.conn = pymysql.connect(
45 host=‘localhost‘,
46 port=3306,
47 user=‘root‘,
48
49 passwd=‘123456‘,
50 db=‘test‘,
51 charset=‘utf8‘,
52 )
53 self.cur = self.conn.cursor()
54
55 def process_item(self, item, spider):
56
57
58 if isinstance(item, EastdayItem):
59 item["crawled_time"] = time.strftime(‘%Y-%m-%d %H:%M:%S‘, time.localtime(time.time()))
60 print item[‘pubdate‘]
61
62 try:
63 for key in dict(item):
64 pass
65 item[key]=str(item[key]).replace("‘", "\\\‘")
66 item[key] = str(item[key]).replace(‘"‘,‘\\\"‘)
67
68 sql="""insert into eastday values(NULL,"{title}","{url}","{tag}","{brief}","{pubdate}","{origin}","{crawled_time}","{miniimg}","{img_urls}","{article}")""".format(title=item[‘title‘],url=item[‘url‘],tag=item[‘tag‘],brief=item[‘brief‘],pubdate=item[‘pubdate‘],origin=item[‘origin‘],crawled_time=item[‘crawled_time‘],miniimg=item[‘miniimg‘],img_urls=item[‘img_urls‘],article=item[‘article‘])
69 sql2 = ‘select 1 from eastday where url="%s"‘%item[‘url‘]
70 print ‘sql:‘,sql
71
72 self.cur.execute(sql2)
73 is_exist = self.cur.fetchone()
74 if is_exist==(1,):
75 print ‘已存在%s‘%item[‘url‘]
76
77 else:
78 self.cur.execute(sql)
79 self.conn.commit()
80 print ‘插入成功‘
81
82 except Exception as e:
83 print u‘数据库error:‘,e
84 pass
85
86
87 else:
88 print ‘nonnonono‘
89
90
91
92 class DownloadImagesPipeline(ImagesPipeline):
93
94
95 def get_media_requests(self, item, info):
96
97
98 if item[‘img_urls‘]:
99 for img_url in item[‘img_urls‘]:
100
101 yield Request(img_url,meta={‘name‘:img_url})
102
103 def item_completed(self, results, item, info):
104 image_paths = [x[‘path‘] for ok, x in results if ok]
105 if not image_paths:
106 raise DropItem("Item contains no images")
107 return item
108
109 def file_path(self, request, response=None, info=None):
110 m=request.meta
111 img_name=re.findall(‘/([a-z_0-9]*)\.[(jpeg)|(jpg)|(png)|(bmp)|(gif)|(JPEG)|(JPG)|(PNG)|(BMP)|(GIF)]‘,m[‘name‘])[-1]
112 #print ‘img_name‘,img_name
113 filename = ‘full3/%s.jpg‘%img_name
114 return filename
这是items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # http://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class EastdayItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 title=scrapy.Field() 15 url=scrapy.Field() 16 tag=scrapy.Field() 17 article=scrapy.Field() 18 img_urls=scrapy.Field() 19 crawled_time=scrapy.Field() 20 pubdate=scrapy.Field() 21 origin=scrapy.Field() 22 23 24 brief = scrapy.Field() 25 miniimg = scrapy.Field() 26 27 28 pass 29 30 ‘‘‘ 31 class GuoneiItem(scrapy.Item): 32 # define the fields for your item here like: 33 # name = scrapy.Field() 34 title=scrapy.Field() 35 url=scrapy.Field() 36 tag=scrapy.Field() 37 article=scrapy.Field() 38 img_urls=scrapy.Field() 39 crawled_time=scrapy.Field() 40 41 brief=scrapy.Field() 42 miniimg=scrapy.Field() 43 44 45 pass 46 ‘‘‘
文件太多啦,不一一贴了,源码文件已打包已上传到博客园,但没找到分享文件链接的地方,如果要源码的可以评论中留言。
这是mysql的存储结果:
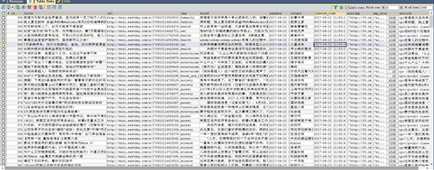
东方头条内容也是采集其他网站报刊的,内容还是很丰富,把东方头条的爬下来快可以做一个咨询内容的app了。
文章图片采用的是新闻中图片的连接的源文件名,方便前端开发在页面中展现正确的图片。
[置顶]使用scrapy_redis,自动实时增量更新东方头条网全站新闻
标签:lin ima 页面 cas model nes average 列表 des
原文地址:https://www.cnblogs.com/zxtceq/p/8985702.html