标签:数据流 palette 读写 采样率 实例 为我 而且 灰度 pad
PNG,JPEG,GIF,BMP作为数据压缩文件,有许多重要的信息我们需要区深度解析。
PNG文件结构很简单,主要有数据块(Chunk Block)组成,最少包含4个数据块。
| PNG标识符 | PNG数据块(IHDR) | PNG数据块(其他类型数据块) | ... | PNG结尾数据块(IEND) |
PNG定义了两种类型的数据块,一种是称为关键数据块(critical chunk),这是标准的数据块,另一种叫做辅助数据块(ancillary chunks),这是可选的数据块。关键数据块定义了4个标准数据块,每个PNG文件都必须包含它们,PNG读写软件也都必须要支持这些数据块。虽然PNG文件规范没有要求PNG编译码器对可选数据块进行编码和译码,但规范提倡支持可选数据块。
下表就是PNG中数据块的类别,其中,关键数据块部分我们使用深色背景加以区分。
|
PNG文件格式中的数据块 |
||||
|
数据块符号 |
数据块名称 |
多数据块 |
可选否 |
位置限制 |
| IHDR | 文件头数据块 | 否 | 否 | 第一块 |
| cHRM | 基色和白色点数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| gAMA | 图像γ数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| sBIT | 样本有效位数据块 | 否 | 是 | 在PLTE和IDAT之前 |
| PLTE | 调色板数据块 | 否 | 是 | 在IDAT之前 |
| bKGD | 背景颜色数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| hIST | 图像直方图数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| tRNS | 图像透明数据块 | 否 | 是 | 在PLTE之后IDAT之前 |
| oFFs | (专用公共数据块) | 否 | 是 | 在IDAT之前 |
| pHYs | 物理像素尺寸数据块 | 否 | 是 | 在IDAT之前 |
| sCAL | (专用公共数据块) | 否 | 是 | 在IDAT之前 |
| IDAT | 图像数据块 | 是 | 否 | 与其他IDAT连续 |
| tIME | 图像最后修改时间数据块 | 否 | 是 | 无限制 |
| tEXt | 文本信息数据块 | 是 | 是 | 无限制 |
| zTXt | 压缩文本数据块 | 是 | 是 | 无限制 |
| fRAc | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFg | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFt | (专用公共数据块) | 是 | 是 | 无限制 |
| gIFx | (专用公共数据块) | 是 | 是 | 无限制 |
| IEND | 图像结束数据 | 否 | 否 | 最后一个数据块 |
PNG文件中,每个数据块由4个部分组成,如下:
|
名称 |
字节数 |
说明 |
|
Length (长度) |
4字节 |
指定数据块中数据域的长度,其长度不超过(231-1)字节 |
|
Chunk Type Code (数据块类型码) |
4字节 |
数据块类型码由ASCII字母(A-Z和a-z)组成的“数据块符号” |
|
Chunk Data (数据块数据) |
可变长度 |
存储按照Chunk Type Code指定的数据 |
|
CRC (循环冗余检测) |
4字节 |
存储用来检测是否有错误的循环冗余码 |
CRC(cyclic redundancy check)域中的值是对Chunk Type Code域和Chunk Data域中的数据进行计算得到的。CRC具体算法定义在ISO 3309和ITU-T V.42中,其值按下面的CRC码生成多项式进行计算:
x32+x26+x23+x22+x16+x12+x11+x10+x8+x7+x5+x4+x2+x+1
CRC: 一种校验算法。仅仅用来校验数据的正确性的,这里因为使用了4个字节,说明使用的是CRC32标准算法。
根据PNG文件的定义来说,其文件头位置总是由位固定的字节来描述的:
|
十进制数 |
137 80 78 71 13 10 26 10 |
|
十六进制数 |
89 50 4E 47 0D 0A 1A 0A |
JPEG,PNG,GIF,BMP等图片都具有不同的图像标识符号,判读一个文件的正确mimeType类型,更应该通过标识符,而不是通过后缀名判断,下面这种方法是不可靠的,因为后缀名可以随便修改。
boolean isPNG = filename.endsWith(".png");
同样,jdk本身提供api判断文件 mime type依旧有问题的,他同样是根据后缀名判断,甚至不去检测文件是否存在。
String contentTypeFor = URLConnection.getFileNameMap().getContentTypeFor("123.gif");
文件头数据块IHDR(header chunk):它包含有PNG文件中存储的图像数据的基本信息,并要作为第一个数据块出现在PNG数据流中,而且一个PNG数据流中只能有一个文件头数据块。
文件头数据块由13字节组成,它的格式如下表所示。
|
域的名称 |
字节数 |
说明 |
|
Width |
4 bytes |
图像宽度,以像素为单位 |
|
Height |
4 bytes |
图像高度,以像素为单位 |
|
Bit depth |
1 byte |
图像深度: |
|
ColorType |
1 byte |
颜色类型: |
|
Compression method |
1 byte |
压缩方法(LZ77派生算法) |
|
Filter method |
1 byte |
滤波器方法 |
|
Interlace method |
1 byte |
隔行扫描方法: |
由于本文很多设计到了PNG在手机方面的应用,因此在此提出MIDP1.0对所使用PNG图片的要求:
bKGD cHRM gAMA hIST iCCP iTXt pHYs
sBIT sPLT sRGB tEXt tIME tRNS zTXt
调色板数据块PLTE(palette chunk)包含有与索引彩色图像(indexed-color image)相关的彩色变换数据,它仅与索引彩色图像有关,而且要放在图像数据块(image data chunk)之前。
PLTE数据块是定义图像的调色板信息,PLTE可以包含1~256个调色板信息,每一个调色板信息由3个字节组成:
|
颜色 |
字节 |
意义 |
|
Red |
1 byte |
0 = 黑色, 255 = 红 |
|
Green |
1 byte |
0 = 黑色, 255 = 绿色 |
|
Blue |
1 byte |
0 = 黑色, 255 = 蓝色 |
因此,调色板的长度应该是3的倍数,否则,这将是一个非法的调色板。
对于索引图像,调色板信息是必须的,调色板的颜色索引从0开始编号,然后是1、2……,调色板的颜色数不能超过色深中规定的颜色数(如图像色深为4的时候,调色板中的颜色数不可以超过2^4=16),否则,这将导致PNG图像不合法。
真彩色图像和带alpha通道数据的真彩色图像也可以有调色板数据块,目的是便于非真彩色显示程序用它来量化图像数据,从而显示该图像。
图像数据块IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。
IDAT存放着图像真正的数据信息,因此,如果能够了解IDAT的结构,我们就可以很方便的生成PNG图像。
图像结束数据IEND(image trailer chunk):它用来标记PNG文件或者数据流已经结束,并且必须要放在文件的尾部。
如果我们仔细观察PNG文件,我们会发现,文件的结尾12个字符看起来总应该是这样的:
00 00 00 00 49 45 4E 44 AE 42 60 82
不难明白,由于数据块结构的定义,IEND数据块的长度总是0(00 00 00 00,除非人为加入信息),数据标识总是IEND(49 45 4E 44),因此,CRC码也总是AE 42 60 82。
以下是由Fireworks生成的一幅图像,图像大小为8*8,
为了方便观看,将图像放大:

使用UltraEdit32或者WinHex打开该文件,如下:
00000000~00000007:

可以看到,选中的头8个字节即为PNG文件的标识。
接下来的地方就是IHDR数据块了:
00000008~00000020:
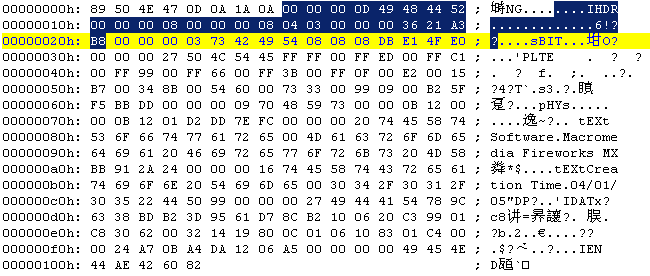
CRC校验代码如下:
import java.util.zip.CRC32; public class CrcTest { public static void main(String[] args) { byte[] checkData = new byte[]{0x49,0x48,0x44,0x52,0x00,0x00,0x00, 0x08,0x00,0x00,0x00, 0x08,0x04,0x03,0x00,0x00,0x00}; CRC32 crc32 = new CRC32(); crc32.update(checkData); long value = crc32.getValue(); byte[] intToBytes = longToBytes(value); String bytesToHexString = bytesToHexString(intToBytes); System.out.println(bytesToHexString); } public static byte[] longToBytes(long value) { byte[] src = new byte[4]; src[0] = (byte) ((value>>24) & 0xFF); src[1] = (byte) ((value>>16)& 0xFF); src[2] = (byte) ((value>>8)&0xFF); src[3] = (byte) (value & 0xFF); return src; } //将字节数组按16进制输出 public static String bytesToHexString(byte[] src){ StringBuilder stringBuilder = new StringBuilder(""); if (src == null || src.length <= 0) { return null; } for (int i = 0; i < src.length; i++) { int v = src[i] & 0xFF; String hv = Integer.toHexString(v); if (stringBuilder.length() != 0) { stringBuilder.append(","); } if (hv.length() < 2) { stringBuilder.append(0); } stringBuilder.append(hv); } return stringBuilder.toString(); } }
00000021~0000002F:
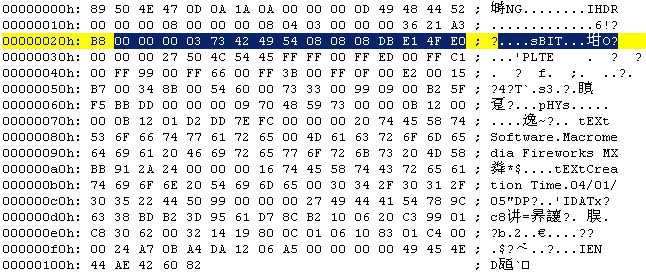
可选数据块sBIT,颜色采样率,RGB都是256(2^8=256)
00000030~00000062:
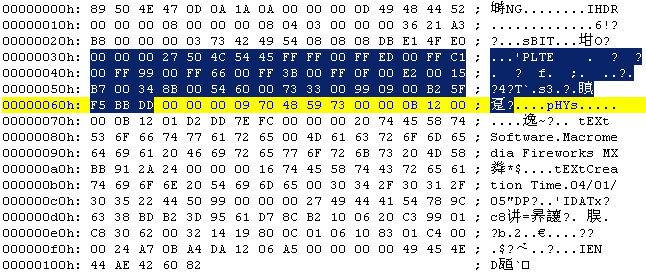
这里是调色板信息
00000063~000000C5:

这部分包含了pHYs、tExt两种类型的数据块共3块,由于并不太重要,因此也不再详细描述了。
000000C0~000000F8:

以上选中部分是IDAT数据块
IDAT中压缩数据部分在后面会有详细的介绍。
000000F9~00000104:
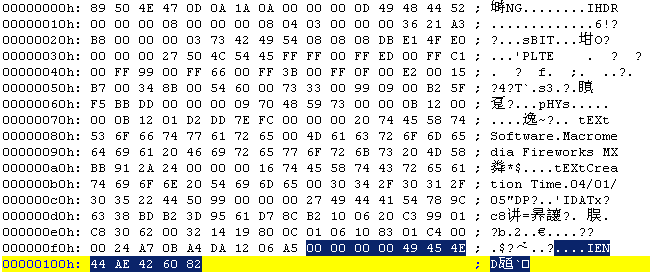
IEND数据块,这部分正如上所说,通常都应该是
00 00 00 00 49 45 4E 44 AE 42 60 82
至此,我们已经能够从一个PNG文件中识别出各个数据块了。由于PNG中规定除关键数据块外,其它的辅助数据块都为可选部分,因此,有了这个标准后,我们可以通过删除所有的辅助数据块来减少PNG文件的大小。(当然,需要注意的是,PNG格式可以保存图像中的层、文字等信息,一旦删除了这些辅助数据块后,图像将失去原来的可编辑性。)
删除了辅助数据块后的PNG文件,现在文件大小为147字节,原文件大小为261字节,文件大小减少后,并不影响图像的内容。参考:打造自由换色的png图片类。
如上说过,IDAT数据块是使用了LZ77压缩算法生成的,由于受限于手机处理器的能力,因此,如果我们在生成IDAT数据块时仍然使用LZ77压缩算法,将会使效率大打折扣,因此,为了效率,只能使用无压缩的LZ77算法,关于LZ77算法的具体实现,此文不打算深究,如果你对LZ77算法的JAVA实现有兴趣,可以参考以下两个站点:
上面我们已经对PNG的存储格式有了了解,因此,生成PNG图片只需要按照以上的数据块写入文件即可。
(由于IHDR、PLTE的结构都非常简单,因此,这里我们只是重点讲一讲IDAT的生成方法,IHDR和PLTE的数据内容都沿用以上的数据内容)
问题确实是这样的,我们知道,对于大多数的图形文件来说,我们都可以将实际的图像内容映射为一个二维的颜色数组,对于上面的PNG文件,由于它用的是16色的调色板(实际是13色),因此,对于图片的映射可以如下:
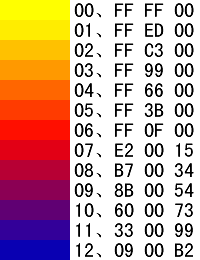
| 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 |
| 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 |
| 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 |
| 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 |
| 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 6 | 5 | 4 | 3 | 2 | 1 | 0 | 0 |
| 5 | 4 | 3 | 2 | 1 | 0 | 0 | 0 |
PNG Spec中指出,如果PNG文件不是采用隔行扫描方法存储的话,那么,数据是按照行(ScanLine)来存储的,为了区分第一行,PNG规定在每一行的前面加上0以示区分,因此,上面的图像映射应该如下:
| 0 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 |
| 0 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 |
| 0 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 |
| 0 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 |
| 0 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 0 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 0 |
| 0 | 5 | 4 | 3 | 2 | 1 | 0 | 0 | 0 |
另外,需要注意的是,由于PNG在存储图像时为了节省空间,因此每一行是按照位(Bit)来存储的,而并不是我们想象的字节(Byte),如果你没有忘记的话,我们的IHDR数据块中的色深就指明了这一点,所以,为了凑成PNG所需要的IDAT,我们的数据得改成如下:
| 0 | 203 | 169 | 135 | 101 |
| 0 | 186 | 152 | 118 | 84 |
| 0 | 169 | 135 | 101 | 67 |
| 0 | 152 | 118 | 84 | 50 |
| 0 | 135 | 101 | 67 | 33 |
| 0 | 118 | 84 | 50 | 16 |
| 0 | 101 | 67 | 33 | 0 |
| 0 | 84 | 50 | 16 | 0 |
最后,我们对这些数据进行LZ77压缩就可以得到IDAT的正确内容了。
然而,事情并不是这么简单,因为我们研究的是手机上的PNG,如果需要在手机上完成LZ77压缩工作,消耗的时间是可想而知的,因此,我们得再想办法加减少压缩时消耗的时间。
好在LZ77也提供了无压缩的压缩方法(奇怪吧?),因此,我们只需要简单的使用无压缩的方式写入数据就可以了,这样虽然浪费了空间,却换回了时间!
好了,让我们看一看怎么样凑成无压缩的LZ77压缩块:
|
字节 |
意义 |
| 0~2 | 压缩信息,固定为0x78, 0xda, 0x1 |
| 3~6 | 压缩块的LEN和NLEN信息 |
|
压缩的数据 |
|
| 最后4字节 | Adler32信息 |
其中的LEN是指数据的长度,占用两个字节,对于我们的图像来说,第一个Scan Line包含了5个字节(如第一行的0, 203, 169, 135, 101),所以LEN的值为5(字节/行) * 8(行) = 40(字节),生成字节为28 00(低字节在前),NLEN是LEN的补码,即NLEN = LEN ^ 0xFFFF,所以NLEN的为 D7 FF,Adler32信息为24 A7 0B A4(具体算法见源程序),因此,按照这样的顺序,我们生成IDAT数据块,最后,我们将IHDR、PLTE、IDAT和IEND数据块写入文件中,就可以得到PNG文件了,如图:

(选中的部分为生成的“压缩”数据)
至此,我们已经能够采用最快的时间将数组转换为PNG图片了。
标签:数据流 palette 读写 采样率 实例 为我 而且 灰度 pad
原文地址:https://www.cnblogs.com/ECJTUACM-873284962/p/8986391.html