标签:get 大小 app 路径 结构 字母 work alt length
一、什么是XML?有什么用途
1、XML全名为可扩展标记语言(eXtensible Markup Language),是w3c组织的一个技术规范,具有严格的数据格式,主要作用是描述数据并集中于数据的内容。
2、XML的主要用途:
①作为小型数据库存储数据,office软件貌似就是这么用xml存储数据。
②作为配置文件,存储相关的配置信息,如spring、mybatis等框架的配置文件。
③作为传输数据的载体,如webservice。不过由于xml的数据格式冗余太多,没有json高效简洁。
二、XML的文档格式
1、xml的文档声明 :<?xml version="1.0" encoding="GBK" standalone="yes"?>
该声明不是必需,如果有则会在xml文档的第一行。 该声明有三个键值对,version表示版本号,encoding表示该文档使用的字符集编码,standalone表示是否可以在不读取其他文件的情况下处理该文档。
2、xml注释 :<!-- 注释内容 -->
3、标签 <标签><标签/> 、<标签/>
①标签区分大小写
②标签不能以数字或下划线开头、不能以xml开头、不能包含空格
③标签中所有的空格和换行都会当作标签内容来处理
4、xml中的转义字符
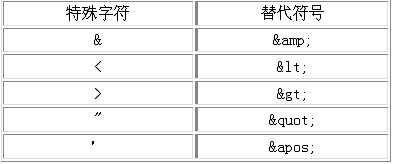
5、 <![CDATA[内容]]> 将内容原样输出
三、XML约束
如果一个XML文件的语法符合W3C的规范,这该XML是一个良好的XML。如果一个良好的XML通过了用户自定义的DTD和Schema的校验约束,则称这个XML为有效的XML。
XML的约束分为两种,DTD约束和Schema约束
1、DTD约束 : 文档类型定义(Document Type Definition,简称DTD)
①DTD的作用
DTD定义了XML文档内容的结构,保证XML以一致的格式存储数据
XML允许用户为应用程序创建自己的DTD
通过DTD定义的词汇表以及文档语法,XML解析器可以检查XML文档内容的有效性
②如何引入DTD
内部编写:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <!DOCTYPE 班级 [ <!ELEMENT 班级 (学生+)> <!ELEMENT 学生 (姓名,性别,年龄)> <!ELEMENT 姓名 (#PCDATA)> <!ELEMENT 性别 (#PCDATA)> <!ELEMENT 年龄 (#PCDATA)> ]> <班级>
<学生> <姓名>小明</姓名> <性别>男</性别> <年龄>67</年龄> </学生> ... </班级>
外部引入本地约束文件:<!DOCTYPE 文档根结点 SYSTEM "DTD文件的URL">
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE books SYSTEM "F:/eclipseWorkSpace/testProject/src/testxml/book.dtd"> <books> <book id="001" name="红楼梦"> <price>10.0</price> </book> <book id="002" name="三国演义"> <price>11.0</price> </book> <book id="003" name="西游记"> <price>12.0</price> </book> <book id="004" name="水浒传"> <price>13.0</price> </book> </books>
<!--DTD约束文件book.dtd--> <?xml version="1.0" encoding="UTF-8" ?> <!ELEMENT books (book)?> <!ELEMENT book (price)?> <!ATTLIST book id ID #REQUIRED name CDATA #REQUIRED > <!ELEMENT price (#PCDATA)>
外部引入公共约束文件:<!DOCTYPE 文档根结点 PUBLIC "DTD名称" "DTD文件的URL">
③DTD语法
元素声明格式:<!ELEMENT 元素名称 元素类型>
元素类型分类:
EMPTY:不能有子元素,不能有文本数据,可以有属性
#PCDATA:不能有子元素,只能有文本元素
ANY:元素可以包含任意类型的元素,子元素、文本、空白
带有子元素的元素配置方式:
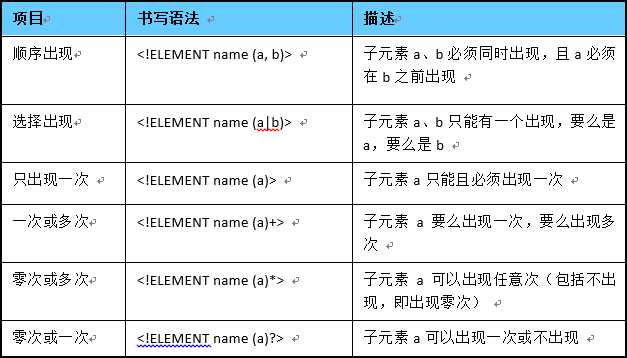
元素属性约束声明:
<!ATTLIST 元素名
属性名1 属性值类型 设置说明
属性名2 属性值类型 设置说明
……>
属性值类型
CDATA:普通文本字符串
ENUMERATED:属性类型是一组列表,XML属性只能从中选择一个 如:<!ATTLIST 肉 品种 ( 鸡肉 | 牛肉 | 猪肉 | 鱼肉 ) "鸡肉">
ID :属性的设置值为一个唯一值。属性的值只能由字母,下划线开始,不能出现空白字符。
设置说明
#REQUIRED 必须设置该属性
#IMPLIED :可以设置也可以不设置
#FIXED :该属性为一固定值。如:<!ATTLIST 姓名 帮派 CDATA #FIXED "丐帮">
直接使用默认值:在 XML 中可以设置该值也可以不设置该属性值。若没设置则使用默认值。如 <!ATTLIST 姓名 帮派 CDATA "丐帮">
④Schema约束:
XML也是一种定义和描述XML文档结构和内容的语言,其出现是为了克服DTD的局限性,其支持更多的数据类型,并支持用户自定义新的数据类型。
XML Schema 文件自身就是一个XML文件,它的扩展名通常为.xsd。
XML Schema对名称空间支持得非常好。
一个XML Schema文档通常称之为模式文档(约束文档),遵循这个文档书写的xml文件称之为实例文档。
编写了一个XML Schema约束文档后,通常需要把这个文件中声明的元素绑定到唯一的一个URI地址上,在XML Schema技术中有一个专业术语来描述这个过程,即把XML Schema文档声明的元素绑定到一个名称空间上,以后XML文件就可以通过这个URI(即名称空间)来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。
四、XPath基本使用
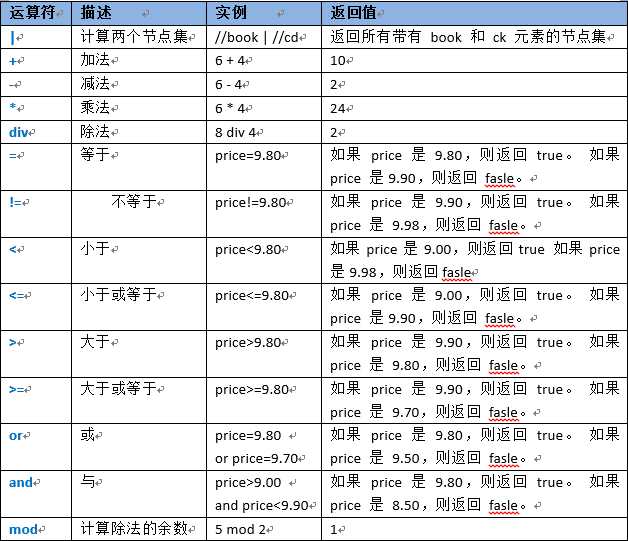
XPath是一种表达式语言,XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。XPath是为了更快更好地选取我们想要选取的XML元素。

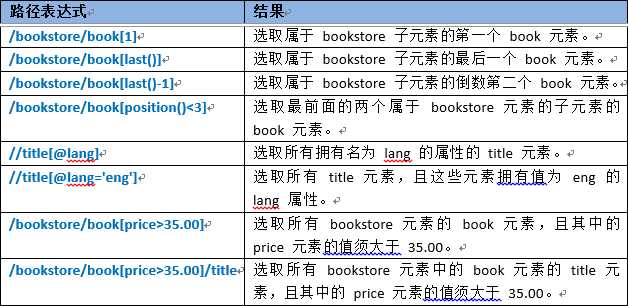
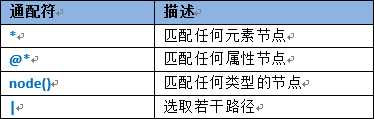
<?xml version="1.0" encoding="utf-8"?> <学生列表> <学生 学号="001"> <姓名>郭靖</姓名> <密码>123</密码> <性别>男</性别> <年龄>30</年龄> <师傅>江南七怪</师傅> </学生> <学生 学号="002"> <姓名 帮派="丐帮">黄蓉</姓名> <密码>456</密码> <性别>女</性别> <年龄>20</年龄> </学生> </学生列表>
@Test public void test1() throws Exception{ SAXReader reader = new SAXReader(); Document doc = reader.read("src/student.xml"); List<Element> eList = doc.selectNodes("/学生列表/学生/姓名"); for(Element e:eList){ System.out.println(e.getText()); } }
五、java解析XML文件
DOM解析:将XML文件加载进内存,构建DOM树,这样可以随意存取和修改文件树的任何部分,没有次数限制,并且易于开发,但不适合大型的XML文件。
SAX解析:类似于流媒体的特点,能够立即对XML进行分析,而不是等待所有数据都加载完成。SAX解析是基于事件的模型,它在解析的过程中可以触发一系列的事件,然后激活回调方法进行处理,并且不能对XML进行修改操作。
SAX只能按照顺序进行解析,并且占用内存较小,适合大型XML文件。
JAXP(Java API for XML Processing,意为XML处理的Java API)是Java XML程序设计的应用程序接口之一,它提供解析和验证XML文档的能力。DOM解析和SAX解析是两种思想,JAXP是java对其的具体实践。
JDOM 实现了JAVA自己的文档模型,其效率比JAXP的DOM解析要快,JDOM自身不包含解析器。它通常使用SAX2解析器来解析和验证输入XML文档。JDOM还是要构建DOM树,所以对超大型XML文件还是不太适合。
DOM4J 是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,并且具有更好的性能,同样也是不适合大型的XML文件。
StAX 是一个基于JAVA API用于解析XML文档,类似SAX解析器的方式。StAX是PULL API,其中作为SAX是PUSH API。这意味着如果StAX解析器,客户端应用程序需要询问StAX解析器从XML获取信息它所需要的,但如果是SAX解析器,客户端应用程序需要获取信息时,SAX解析器会通知客户端应用程序的信息是可用的。StAX的API可以读取和写入XML文档。
代码示例:
public class TestJAXP { public static void main(String[] args) throws Exception{ //jaxpDom(); jaxpSax(); } public static void jaxpDom() throws Exception{ //读取xml文档 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse(new FileInputStream(new File("F:/eclipseWorkSpace/testProject/src/testxml/book.xml"))); String version = document.getXmlVersion(); System.out.println(version); System.out.println(document.getNodeName()); Node rootNode = document.getDocumentElement(); System.out.println(rootNode.getNodeName() + "==" +(rootNode.getNodeType()== Node.ELEMENT_NODE)); NodeList childNodes = rootNode.getChildNodes(); int lenght = childNodes.getLength(); for(int i=0;i<lenght;i++){ Node childNode = childNodes.item(i); if(childNode.getNodeType() == Node.ELEMENT_NODE){ System.out.println(childNode.getNodeName() +"=="+ childNode.getNodeType()); System.out.println(childNode.getTextContent()); NamedNodeMap attributes = childNode.getAttributes(); for(int j=0 ; j<attributes.getLength();j++){ Node attr = attributes.item(j); System.out.println(attr.getNodeName() + "==" + attr.getNodeValue()); } } } Element book = document.createElement("book"); book.setAttribute("id", "005"); book.setAttribute("name", "XXX"); Element privce = document.createElement("price"); privce.setTextContent("15.01"); book.appendChild(privce); rootNode.appendChild(book); //输出xml TransformerFactory tFactory = TransformerFactory.newInstance(); Transformer tf = tFactory.newTransformer(); tf.transform(new DOMSource(document), new StreamResult(new FileOutputStream("F:/eclipseWorkSpace/testProject/src/testxml/book2.xml"))); } public static void jaxpSax() throws Exception{ SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser parser = factory.newSAXParser(); XMLReader xmlReader = parser.getXMLReader(); //XMLReader xmlReader = XMLReaderFactory.createXMLReader();//这种方式获取xmlReader也可以 xmlReader.setContentHandler(new BookParser()); xmlReader.parse(new InputSource(new FileInputStream("F:/eclipseWorkSpace/testProject/src/testxml/book2.xml"))); } } class BookParser extends DefaultHandler{ @Override public void startDocument() throws SAXException { System.out.println("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>"); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { StringBuilder sb = new StringBuilder(); sb.append("<").append(qName); for(int i=0;i<attributes.getLength();i++){ sb.append(" \"").append(attributes.getLocalName(i)).append("\"=").append(attributes.getValue(i)); } sb.append(">"); System.out.print(sb); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.print("</"+qName+">"); } @Override public void characters(char[] ch, int start, int length) throws SAXException { String cnt = new String(ch,start,length); System.out.print(cnt); } }
public class testJDom { public static void main(String[] args) throws JDOMException, IOException { String url = "F:/eclipseWorkSpace/testProject/src/testxml/book3.xml"; getInfo(url); } @SuppressWarnings("unchecked") public static void getInfo(String url) throws JDOMException, IOException{ SAXBuilder saxBuilder = new SAXBuilder(); Document document = saxBuilder.build(new File(url)); Element rootElement = document.getRootElement(); System.out.println(rootElement.getName()); List<Element> children = rootElement.getChildren(); for(Element childElement :children){ System.out.println(childElement.getName()); List<Attribute> attributes = childElement.getAttributes(); for(Attribute attr : attributes){ System.out.println(attr.getName()+"====="+attr.getValue()); } } } }
public class TestDom4J { public static void main(String[] args) throws Exception { String url = "F:/eclipseWorkSpace/testProject/src/testxml/book3.xml"; getInfo(url); //updateXml(url); } @SuppressWarnings("unchecked") public static void getInfo(String url) throws DocumentException{ SAXReader reader = new SAXReader(); Document document = reader.read(new File(url)); Element rootNode = document.getRootElement(); System.out.println(rootNode.getName()); List<Element> elements = rootNode.elements(); for(Element n : elements){ System.out.println(n.getName()); List<Attribute> attributes = n.attributes(); for(Attribute attr : attributes){ System.out.println(attr.getName()+"==="+attr.getValue()); } } } public static void updateXml(String url) throws Exception{ SAXReader reader = new SAXReader(); Document document = reader.read(new File(url)); Element rootNode = document.getRootElement(); Element book = rootNode.addElement("book"); book.addAttribute("id", "005"); book.addAttribute("name","封神榜"); Element price = book.addElement("price"); price.setText("123.1"); OutputFormat format = OutputFormat.createCompactFormat(); format.setEncoding("UTF-8"); XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(url),format); xmlWriter.write(document); xmlWriter.close(); } }
public class TestStAX { public static void main(String[] args) throws FileNotFoundException, XMLStreamException { String url = "F:/eclipseWorkSpace/testProject/src/testxml/book.xml"; getInfo(url); } public static void getInfo(String url) throws FileNotFoundException, XMLStreamException{ XMLInputFactory factory = XMLInputFactory.newInstance(); XMLStreamReader reader = factory.createXMLStreamReader(new FileInputStream(url)); while(reader.hasNext()){ int event = reader.next(); if(event == XMLStreamConstants.START_ELEMENT ){ StringBuilder sb = new StringBuilder(); sb.append("<").append(reader.getLocalName()); for(int i=0;i<reader.getAttributeCount();i++){ sb.append(" \"").append(reader.getAttributeLocalName(i)).append("\"=").append(reader.getAttributeValue(i)); } sb.append(">"); System.out.print(sb); } if(event == XMLStreamConstants.END_ELEMENT){ System.out.print("</"+reader.getLocalName()+">"); } if(event == XMLStreamConstants.CHARACTERS){ System.out.print(reader.getText()); } } } }
标签:get 大小 app 路径 结构 字母 work alt length
原文地址:https://www.cnblogs.com/kyleinjava/p/8984712.html