标签:指针函数 file 进程 sleep back lin 同名 use 严格
有以下几个:+ (加) -(减) * (乘) / (除) %(取余)
注意:注意取余运算%,先取整,再取余
自增自减运算符: ++ (加加) -- (减减)
常规:对数字进行自加1或自减1。
字符串: 只能自增,且自增的效果就是“下一个字符”
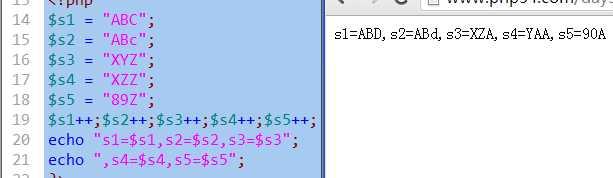
布尔值递增递减无效
ull递减无效,递增结果为1
前++:先完成变量的递增运算,再取得该变量的值参与别的运算。
后++:先将原来变量的值临时存储,再将变量值递增,最后再将临时存储的值参与别的运算。
推论1:如果独立语句中进行自加运算,前自加后自加没有区别 。
推论2:如果前自加后自加是放在别的语句中,则会有所区别。
推论3: 前加加比后加加效率略高(在循环中建议使用前加加)。
包括:> >= < <= ==松散相等 != ===严格相等 !==
==:松散相等,比较的是两个数据“类型转换之后”是否有可能相等,也常常认为是“数据内容是否相同”
===:严格相等,全等,只有两个数据的类型和数据的内容都完全一致,才相等。
正常比较——数字的大小比较
如果有布尔值,均转为布尔值比较:规则:true > false
否则,如果有数字,均转为数字比较:
否则,如果两边都是纯数字字符串,转为数字比较
否则,就按字符串比较
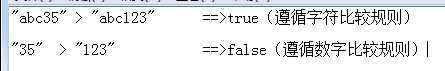
字符串的比较规则为:按字符的先后顺序依次一个一个比较,发现哪个大,则就表示整体大,后续不再比较
前提:都是针对布尔类型的值进行的运算,如果不是布尔,就会转换为布尔。
逻辑与:&&
一般的运算符需要2个数据参与
有几个运算符只需要一个数据参与: ++, -- !
则:
条件运算符就需要至少3个数据参与!
形式为:数据1 ? 数据2 :数据3
通常,数据1最终应该是一个布尔值(如果不是,则会当作布尔值来使用)。
有以下几个:+ - * / % ++ --
注意:注意取余运算%,先取整,再取余
$v1 = 7.5 % 3;//结果是:1
$v2 = 7.5 % 3.5;//结果是:1
对比js中:——js中, 不会进行取整处理
var v1 = 7.5 % 3;//结果是:1.5
var v2 = 7.5 % 3.5;//结果是:0.5
常规:对数字进行自加1或自减1。
字符串: 只能自增,且自增的效果就是“下一个字符”
布尔值递增递减无效
null递减无效,递增结果为1
前++:先完成变量的递增运算,再取得该变量的值参与别的运算。
后++:先将原来变量的值临时存储,再将变量值递增,最后再将临时存储的值参与别的运算。
推论1:如果独立语句中进行自加运算,前自加后自加没有区别 。
推论2:如果前自加后自加是放在别的语句中,则会有所区别。
推论3: 前加加比后加加效率略高(在循环中建议使用前加加)。
包括:> >= < <= ==松散相等 != ===严格相等 !==
==:松散相等,比较的是两个数据“类型转换之后”是否有可能相等,也常常认为是“数据内容是否相同”
===:严格相等,全等,只有两个数据的类型和数据的内容都完全一致,才相等。
严重推荐参考手册〉〉附录〉〉类型比较表。
正常比较——数字的大小比较
如果有布尔值,均转为布尔值比较:规则:true > false
否则,如果有数字,均转为数字比较:
否则,如果两边都是纯数字字符串,转为数字比较
否则,就按字符串比较
字符串的比较规则为:按字符的先后顺序依次一个一个比较,发现哪个大,则就表示整体大,后续不再比较
前提:都是针对布尔类型的值进行的运算,如果不是布尔,就会转换为布尔。
规则(真值表):
true && true ==> true;
true && false ==>false
false && true ==>false;
false && false==>false;
只有两个都是true,结果才是true
只要有一个是false,结果就是false
规则(真值表):
true || true ==> true;
true || false ==>true
false || true ==>true;
false || false==>false;
只有两个都是false,结果才是false
只要有一个是true,结果就是true
!true ==> false
!false ===>true
在实际应用中,参与逻辑运算的数据,往往都不是直接的布尔值,而是有关计算之后的布尔结果值。
大致如下:
if( IsFemale( $uName ) && isAge($uName) > 18){
......echo “女士优先”
}
此时,如果IsFemale()函数判断的结果是false,那么后续的函数isAge()就不再调用,自然也不再进行大于18的判断,这是就称为“短路现象”
if( IsFemale( $uName ) || isAge($uName) < 18){
......echo “有限照顾女士或未成年人”
}
此时,如果IsFemale()函数判断的结果是true,那么后续的函数isAge()就不再调用,自然也不再进行小于18的判断,这就是“或运算符短路现象”
只有一个: .
衍生一个: .=
会将运算符两边的数据转换为字符串。
对比js:+(具有双重含义,此时就需要一定的“判断”)
只有一个:=
衍生多个:+= -= *= /= %= .=
基本形式为:
$变量 符合赋值运算符 数据2;
这些衍生的赋值运算符,是这种运算的一个简化形式:
$v2 = $v2 [运算符] 数据2;//某个变量跟另一个数据进行某种运算之后的结果再存入该变量
对比(它不是这种形式的简化):
$v2 = 数据2 [运算符] $v2;//这种形式不应该简化
一般的运算符需要2个数据参与
有几个运算符只需要一个数据参与: ++, -- !
则:
条件运算符就需要至少3个数据参与!
形式为:
数据1 ? 数据2 :数据3
通常,数据1最终应该是一个布尔值(如果不是,则会当作布尔值来使用)。
含义:
如果数据1为true,则运算结果为数据2, 否则运算结果为数据3
典型举例:
$score = 66;
$result 1= $score >= 60 ? “及格” : “不及格”; //结果是“及格”
$result 2= $score ? “及格” : “不及格”; //结果是“及格”,但含义完全不同,因为即使分数是33,也是及格。只有分数为0才是不及格。
三目运算符可以转换为if else语句来实现:
if( $score >= 60){
$result1 = “及格";
}
else{
$result1 = “不及格";
}
开始结束:
语句(块):
判断:
输入输出:
走向
if语句:
if(条件判断){
//语句块
}
if else 语句:
if(条件判断){
//分支1
}
else{
//分支2;
}
if else if语句
if -else if -else语句:
switch语句:
switch(一个数据$v1){//判断此v1变量跟下面的某个是否相等,如果相等,则进入对应进程。
case 状态值1:
//进程1
[break;]
case 状态值2:
//进程2
[break;]
case 状态值3:
//进程3;
[break;]
。。。。。。
[default :
//默认进程。
]
}
应用冲,break通常都会用上;只有一些特殊数据或需求的时候,可能不用。
如果没有使用break,则一旦某个状态满足,就会继续执行后续状态中的进程代码,而不再判断。
$v1 = 10;//初始化循环变量
while( $v1〉4 ){//判断循环变量的条件
//语句快
echo “abc”;
$v1--;
}
循环3要素:
1,循环变量初始化
2,循环变量判断
3,循环变量改变
此3 要素通常适用于所有循环过程。
do{
//循环体
}while(条件判断);
含义:
先执行一次循环体,然后判断条件,如果条件满足,则继续回去执行循环体,然后再判断,依次类推。
这里指的中断,适用于所有循环。
循环的中断有两种情况:
break中断:终止整个循环语句,而跳出循环进入到循环结构之后的语句
continue中断:终止当前正在执行的循环体中的语句,而进入到循环的下一次过程里(改变,判断)
中断语句的语法如下:
break $n;//$n是一个大于等于1的整数,表示要中断的循环层数;
continew $n;
所谓循环层数,是指一个循环中又嵌套了循环的情况。
以当前循环为“起点”,表示第一层,往上(外)数,就是2,3,4层。。。。
if ( ... ) :
//语句块
endif;
if ( ... ) :
//语句块
else:
//语句块
endif;
if ( ... ):
//语句块
elseif( ... ) :
//语句块
elseif( ... ):
//语句块
else:
//语句块
endif;
switch( ... ) :
case ...
case ...
endSwitch;
while(...):
//语句块
endwhile;
for(...; ...; ...):
//语句块
endfor;
foreach( ):
//语句块
endForeach;
die(“输出内容”)
含义:终止php脚本的运行(后续代码不再执行),并输出其中的内容
也可以:die();die;
exit是die的同义词。
die是一种“语言结构”,并非函数,可以不写括号。
echo也是一种语言结构,而非函数:
echo (“abc”);
echo “abc”;
echo “abc”, “def”, 123;
sleep($n);
含义:让php脚本停止$n秒,然后继续执行。
php中,数组的下标可以是整数,或字符串。
php中,数组的元素顺序不是由下标决定,而是由其“加入”的顺序决定。
定义:
$arr1 = array(元素1,元素2,。。。。。 );
array(1, 5, 1.1, “abc”, true, false);//可以存储任何数据,此时为“默认下标”,
array(2=>1, 5=>5, 3=>1.1, 7=>“abc”, 0=>true);//下标可以任意设定(无需顺序,无需连续)
array(2=>1, 5, 1=>1.1, “abc”, 0=>true)//可以加下标,也可以不加(默认下标),下标分别是:2,3,1,4,0
//默认下标规则:前面已经用过的最大数字下标+1
array(2=>1, ‘dd’=>5, 1=>1.1, “abc”, 0=>true)//混合下标,同样遵循默认下标规则
array(-2=>1, ‘dd’=>5, 1.1, “abc”, true);//负数下标不算在整数下标中,而只当作字符下标
//则最好3项的下标是:0, 1, 2
array(2.7=>1, ‘dd’=>5, 1=>1.1, “abc”, 0=>true);//浮点数下标为自动转换为整数,且直接抹掉小数
array(“2.7” =>1, ‘dd’=>5, “11”=>1.1, “abc”, true)//纯数字字符串下标,当作数字看待,
//则此时下标为:2, ‘dd’, 11, 12, 13
array(2=>1, ‘dd’=>5, true=>1.1, “abc”, false=>true)//布尔值当下标,则true为1,false为0;
array(2=>1, ‘dd’=>5, 2=>1.1, “abc”, true)//如果下标跟前面的重复,则单纯覆盖前面同名下标的值
//此时相当于为:array(2=>1.1, ‘dd’=>5, “abc”, true)
其他形式;
$arr1[] = 1;
$arr1[] = 5;
$arr1[] = 1.1;//直接在变量后面使用[],就成为数组,并依次赋值。
。。。。
$arr2[‘aa’] = 1;
$arr2[‘bbbcc’] = 5;
$arrr2[5] = 1.1;
。。。。。。。。
这种形式写的下标,其实跟使用array语法结构几乎一样。
取值:通过下标。
赋值(同定义):
关联数组:通常是指下标为字符串,并且该字符串大体可以表达出数据的含义的数组。
例:$person = array(
“name” => “小花”,
“age”=>18,
“edu” => “大学毕业” ,
);
索引数组:
通常是指一个数组的下标是严格的从0开始的连续的数字下标——跟js数组一样。
一维数组:
就是一个数组中的每一个元素值,都是一个普通值(非数组值)
$arr1 = array(
“name” => “小花”,
“age”=>18,
“edu” => “大学毕业”
);
二维数组:
一个数组中的每一项,又是一个一维数组。
$arr1 = array(
“name” => array(‘小花’, ‘小芳’, ‘小明’, );
“age”=>array(18, 22, 19),
“edu” => array(“大学毕业”, ‘中学’, ‘小学’)
);
多维数组:
依此类推。。。
多维数组的一般语法形式:
$v1 = 数组名[下标][下标][.....]
foreach( $arr as [ $key => ] $value )//$key可以称为键变量,$value可以称为值变量。
{
//这里就可以对$key 和 $value 进行所有可能的操作——因为他们就是一个变量
//$key 代表每次取得元素的下标,可能是数字,也可以能是字符串
//$value 代表每次取得元素的值,可能是各种类型。
//此循环结构会从数组的第一项一直遍历循环到最后一项,然后结束。
}
交换原理:
foreach也是正常的循环语法结构,可以有break和continue等操作。
遍历过程中值变量默认的传值方式是值传递。
遍历过程中值变量可以人为设定为引用传递:
foreach($arr as $key => &$value){ ... }
键变量不可以设定为引用传递
foreach默认是原数组上进行遍历。但如果在遍历过程中对数组进行了某种修改或某种指针性操作(就是指前面的指针函数),则会复制数组后在复制的数组上继续遍历循环。
foreach中如果值变量是引用传递,则无论如何都是在原数组上进行。
目标:将下列数组进行正序(从小到大)排列出来
$arr2 = array( 5, 15, 3, 4, 9, 11);
一般性逻辑描述:
1,对该数组从第一个元素开始,从左到右,相邻的2个元素比较大小:如果左边的比右边的大,则将他们俩交换位置,结果:
array( 5, 15, 3, 4, 9, 11);(原始)
array( 5, 15, 3, 4, 9, 11);
array( 5, 3, 15, 4, 9, 11);
array( 5, 3, 4, 15, 9, 11);
array( 5, 3, 4, 9, 15, 11);
array( 5, 3, 4, 9, 11, 15);
此时,才“走完一轮回”,继续下一轮:
array( 5, 3, 4, 9, 11, 15);(初始)
array( 3 5, 4, 9, 11, 15);
array( 3 4, 5 9, 11, 15);
array( 3 4, 5 9, 11, 15);
array( 3 4, 5 9, 11, 15);
继续下一轮:
array( 3 4, 5 9, 11, 15);
。。。。。。。。
|
最初: |
5 |
15 |
3 |
4 |
9 |
11 |
|
第1趟之后: |
5 |
3 |
4 |
9 |
11 |
15 |
|
第2趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
|
第3趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
|
第4趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
|
第5趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
隐含的逻辑描述(假设数组有n项):
1, 需要进行n-1趟的“冒泡”比较过程。
2, 每一趟的比较都前一趟少比一次,第一趟需要比较n-1次
3, 每趟比较,都是从数组的开头(0)开始,跟紧挨的元素比较,并进行交换(需要的时候)
目标:将下列数组进行正序(从小到大)排列出来
$arr2 = array( 5, 15, 3, 4, 9, 11);
一般性逻辑描述:
第1趟:取得该数组中的最大值及其下标,然后跟该数组的最后一项“交换”(倒数第1项确定)
第2趟:取得该数组中除最后1项中的最大值及其下标,然后跟倒数第2项交换(倒数第2项确定)
第3趟:取得该数组中除最后2项中的最大值及其下标,然后跟倒数第3项交换(倒数第3项确定)
。。。。。。
|
最初: |
5 |
15 |
3 |
4 |
9 |
11 |
|
第1趟之后: |
5 |
11 |
3 |
4 |
9 |
15 |
|
第2趟之后 |
5 |
9 |
3 |
4 |
11 |
15 |
|
第3趟之后 |
5 |
4 |
3 |
9 |
11 |
15 |
|
第4趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
|
第5趟之后 |
3 |
4 |
5 |
9 |
11 |
15 |
隐含的逻辑描述(假设数组有n项):
1,要进行n-1趟才可能得出结论
2,每一趟要找的数据的个数都比前一趟少一个,第1趟要找n个
3,每次找出的最大值所在的项,和要与之进行交换的项的位置,依次减1,第一次的位置n-1
就是从一个数组中找一个元素的数据(可能是找下标,也可以是找数据值)
数组的查找通常有2种需求:
1:判断要找的数据是否存在。
2:找出要找的数据的位置(下标)
从一个数组中按顺序找出一个元素(下标或值)
需求1:判断要找的数据是否存在
$v1 = 10;
function search1( $arr, $v1){
foreach($arr as $value ){
if( $c1 == $value ){
return true;
}
}
return false;
}
需求1:找出要找的数据的位置(下标)
$v1 = 10;
function search2( $arr, $v1){
foreach($arr as $key => $value ){
if( $c1 == $value ){
return $key;//找到,返回位置(下标)
}
}
return false;
}
//特别注意以下写法:
if ( ($m = search2( $arr, 10)) === false){
echo “没找到。”
}
else{
echo “找到了,位置为:$m”
}
二分查找的前提:
1,针对一个已经进行了排序的数组(即里面的数据已经是有序了)
2,是连续的索引数组,比如下标为:0, 1, 2, 3, ......
比如:
$arr2 = array( 3, 4, 5, 15, 19, 21, 25, 28, 30, 30, 33, 38, 44, 51, 52, 55, 60, 77, 80, 82, 83);
function 函数名 (形参1,形参2,.... ){
//函数体(代码块)
}
本质上就是使用一个名字来达到执行其中函数中的代码的作用。通常可以分两种情形的调用:
第一种:没有返回值的函数,则调用语句是独立语句:
函数名(实参1,实参2, .... );//实参个数应该跟形参有匹配性。
第二种:有返回值的函数,则调用语句,通常会“混杂”在别的语句中,并将要将该调用语句当作一个“数据”来使用:
A: $v1 = 函数名();//赋值给其他变量;这里省略实参语法,下同。
B: $v1 = 函数名() * 3 + 6;//参与运算,然后再赋值;
C: echo 函数名();//直接输出
D: echo 函数名() * 3 + 6;//参与运算,然后再输出
E: $v1 = 函数名2( 函数名() , 实参2,实参3, .... );//当作实参使用
实际上,一个变量(数据)也只有这几种场合的使用情况。
· 函数调用流程分析
o 开始调用:实际参数传数据给形式参数
o 程序执行流程进入到函数中(一个独立的运行空间),跟全局执行空间是隔离的
o 按常规的程序逻辑执行函数中的代码
o 如果碰到return语句,则终止函数的执行,跳回函数开始调用的位置;
o 如果执行到函数的最后位置,也同样跳回函数开始调用的位置
其运行流程原理图如下:
一个函数,
1,形参一定是一个变量名!
2,该变量名只能是在该函数中有效的变量名;
3,而且只在该函数调用并执行时有效,函数结束,通常这些变量也就“销毁”。
实参就是一个“实际数据”,
该数据可以是一个“直接数据”(比如5,”abc”),也可以是一个变量中存储的数据。
实参的作用是将其数据“赋值给”形参变量。
实参跟形参之间通常应该有个“一一对应”关系:
定义形式: function 函数名(形参1,形参2,...... ){ 。。。。}
调用形式: 函数名(实参1,实参2,..... )
定义一个函数的时候,在形式参数的位置,可以给形式参数设定“默认值”,此时就可以称为默认值参数。比如:
还要注意:
默认值不能是对象或资源类型;
默认值只能是常量表达式,或常量,不能是变量
即:如下语法是正确的:function f1($v1 = 3), function f1($v1 = __LINE__),
如下语法是错误的:function f1($v1 = 3+1),$m = 3; function f1($v1 = $m),
实际上,函数的参数传值问题,跟变量之间的传值问题,是一样的规则(模式):默认都是值传递。
如果实参本身就是“直接数据”,则不存在传值问题,而是简单的“赋值”。
传值问题只发生在实参是变量的情形:
我们也可以让某个参数(形参)以引用传递的方式来传值:
引用传递的形参(实参),在函数内部改变其值,在函数外面的实参,也会相应修改:
注意:如果某个形参设定为引用传递,此时,实参只能使用变量,否则出现语法错误:比如:
1,函数的参数的数量可以是0个或多个——具体多少个,不是语法问题,而是应用问题。
2,通常,实际参数的数量应该跟形式参是的数量一致。
3,但是,在2的基础上,如果形式参是中有默认值,则实际参数的对应项可以省略。
即:实参的个数,至少应该不少于形参中的非默认值参数的个数。
但:
我们还有一种特殊的处理函数参数的用法:自由参数数量
定义时可以不给定形参,但调用时,却又可以给定任何个数的实参。
在系统中,var_dump()这个函数也有同样的使用效果:
var_dump($v1);
var_dump($v1, $v2, $v3);//也可以
这种应用的实现,是依赖与系统中的3个系统函数来达到的:
func_get_args();//获得一个函数所接收到的所有实参数据,并结果是一个数组
func_get_arg(n);//获得一个函数所接收到的第n歌实参数据(n从0开始)
func_num_args();//获得一个函数所接收到的所有实参数据的个数
结果:
通常来说,一个函数中,使用return语句,并其后带一个数据(直接数据,变量数据,表达式结果数据)
则该函数就会返回该数据到“调用的位置”:
通常情况下,函数返回的数据都是以“值传递”的形式返回:函数中的变量的值“拷贝”一份,然后返回给接收的位置的相应代码(赋值,输出,计算)。
但:
我们也可以让函数中的变量数据的值,以“引用传递”的方式返回:
形式如下:
定义函数:
function &函数名(形参1,形参2,.....)//注意函数名前有个引用符号“&”
{
$result = 0;//初始化
。。。。。。。
return $result;//此时返回数据,只能是变量
}
调用函数:
$v1 = &函数名(实参1,实参2,....);//引用返回的函数,自然是指有返回值。
可变函数,就是函数名“可变”——其实跟可变变量一样的道理。
$str1 = “f1”;//只是一个字符串,内容为”f1”
$v1 = $str1(3, 4);//形式上看起来是一个变量后面加上括号,则其本质是该变量的“内容”(f1)后面加括号,即这里是调用函数f1(3, 4);
实际应用中,常常是需要根据“用户给定”的数据,来决定调用哪个函数,比如:
function jpg(){处理jpg图}
function png(){处理png图}
function gif(){处理gif图}
$fileName = get_fileName(){获取用户上传的图片名};
$houzhui = get_houzhui($fileName);
$houzhui();
匿名函数就是没有名字的函数,其有两种表现形式:
表现1:
$f1 = function(){。。。函数体;};
//这里的匿名函数定义形式上没有名字,但其实又将之赋值给了变量$f1
使用时,就跟“可变函数”一样了:$v1 = $f1();
表现形式2:
调用其他函数2(匿名函数,实参1,实参2, ...... );
说明:
1此形式的匿名函数只有定义的函数体(无函数名)
2此形式的匿名函数只能作为其他函数调用时的参数(其他函数通常有特定用处)
3此匿名函数会在调用其他函数的“过程中”被执行。
能够使用(匿名)函数当作实参的函数,并不多!
其中有一个常见的是:call_user_func_array();
其使用形式为:
call_user_func_array(匿名函数,数组);
含义:
将数组的每一项当作该匿名函数的若干个实参,传递到该匿名函数中,并执行该匿名函数,并可以从该匿名函数中返回数据。
通常说作用域,有2个:
局部作用域:只能在所定义的函数范围内使用。
全局作用域:在函数的“外部”范围使用。
——php中,局部和全局作用域是不重叠的
——js中,全局作用域是包括局部作用域的
但还有两个:
超全局:就是在函数的内部和外部都可以使用。
超全局变量只有系统内部预定义的那几个,我们不能再程序中创建超全局变量。
静态局部作用域:其实也是局部,但多一个特征:数据能够在函数退出后仍然保持不丢失。
1,在局部范围内,使用global关键字对全局变量进行一次“声明”,则就可以使用了:
语法:global $变量名;
举例:
说明:
1,实际上,函数中的global 语句,其实是创建了一个跟外部变量同名的局部变量,并通过“引用”的方式指向了外部变量的数据区
示例:
2,在函数中(局部范围),使用$GLOBALS超全局数组来引用(使用)全局变量:
$GLOBALS超全局数组的作用是用于存储所有全局变量的数据:变量名为下标,变量值为对应元素值。
但通过 $GLOBALS操作全局变量,是直接操作(而不是引用操作),即如果unset该对应元素,则全局变量对应变量也被unset:
3,实际上,我们还可以在函数内部直接使用$GLOBALS数组,添加元素的方式来创建全局变量,自然也就类似局部使用全局:
通过引用传递的方式向形参传递一个引用实参变量
$v1 = 10;
function f1( &$p1, $p2){ ...... }//$p1是函数的形参,也即就是函数的内部(局部)变量
$v2 = f1( $v1, 10);//此时我们认为$v1就可以使用函数中$p1的值。
使用函数的引用返回形式:见前面引用传递的方式返回数据
函数中使用global关键字来首次引用一个全局变量,则函数结束后在全局范围就可以使用该变量了
结果:
function_exists():判断某个函数是否被定义过,返回布尔值
if( function_exists(“ func1 “) == false ){
function func1(){。。。。。。};//定义函数
}
func_get_arg(n):获得一个函数的第n个实参值(n从0开始)
func_get_args():获得一个函数的所有实参,结果是一个数组
func_num_args():获得一个函数的所有实参的个数。
递归思想的一个基本形式是:在一个函数中,有至少一条语句,又会去调用该函数自身。
但是,从代码角度来说,如果单纯是函数内部调用函数本,则会出现“出不来”的现象。
则我们就必须再来解决下一个问题:
怎么终止(停止)这种调用——找到递归函数的出口。
案例分析:
写一个递归函数,该函数可以计算一个正整数的阶乘:
数学基础:
A: 1的阶乘是1
B: 大于1的数的阶乘,是这个数减1的数的阶乘,乘以该数的结果。
比如:要求6的阶乘:
则定义一个函数jiecheng(){.....};该函数可以计算n的阶乘
递归思想的总结:
为了解决一个“大”问题,根据现实逻辑,该问题可以通过比它小一级的同类问题的答案而“轻松得到”。小一级的问题又可以通过更小一级的问题而轻松得到,依次类推——直到“最小问题”,通常就是一个已知数(答案)。
递归思想的图示
递推思想本身并不跟函数有直接关系(虽然常常写在函数中)。
其基本思路为:
为了解决一个“大”问题,根据现实逻辑,如果能够找到同类问题的一个“最小问题”的答案(通常是已知的),并且根据已知算法,又可以因此得到比最小问题“大一级”问题的答案。 而且,依次类推,又可以得到再大一级问题的答案,最终就可以得到“最大那个问题”(即要解决的问题)的答案。
可见,该思想的过程依赖与2个条件:
1,可知同类最小问题的答案;
2,大一级问题的答案可以通过小一级问题的答案经过简单运算规则而得到。
此思想的解体思路是:从小到大
对比:递归思想是:从大到小,在回归到大。
举例:求斐波那契数列的第n项的值。
斐波那契数列的规则是:某项的值是其前两项的值的和。
斐波那契数列的前几项为:1,1,2,3,5,8,13,21...(前两项是已知的)
标签:指针函数 file 进程 sleep back lin 同名 use 严格
原文地址:https://www.cnblogs.com/baobaoa/p/8989780.html