标签:分享 平面 卷积 等于 标准 cond assigned 分类 部分
总结自论文:Faster_RCNN,与Pytorch代码:
本文主要介绍代码第二部分:model/utils , 首先分析一些主要理论操作,然后在代码分析里详细介绍其具体实现。
目的是提高定位表现。在DPM与RCNN中均有运用。
1) RCNN版本:
在RCNN中,利用class-specific(特定类别)的bounding box regressor。也即每一个类别学一个回归器,然后对该类的bbox预测结果进行进一步微调。注意在回归的时候要将bbox坐标(左上右下)转为中心点(x,y)与宽高(w,h)。对于bbox的预测结果P和gt_bbox Q来说我们学要学一个变换,使得这个变换可以将P映射到一个新的位置,使其尽可能逼近gt_bbox。与Faster-RCNN不同之处是这个变换的参数组为:
![]()
这四个参数都是特征的函数,前两个体现为bbox的中心尺度不变性,后两个体现为体现为bbox宽高的对数空间转换。学到这四个参数(函数)后,就可以将P映射到G‘, 使得G‘尽量逼近ground truth G:
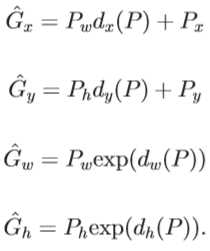 1)
1)
那么这个参数组![]() 是怎么得到的呢?它是关于候选框P的pool5 特征的函数。由pool5出来的候选框P的特征我们定义为
是怎么得到的呢?它是关于候选框P的pool5 特征的函数。由pool5出来的候选框P的特征我们定义为![]() ,那么我们有:
,那么我们有:
![]() 2)
2)
其中W就是可学习的参数。也即我们要学习的参数组![]() 等价于W与特征的乘积。那么回归的目标参数组是什么呢?就是上面四个式子中的逆过程:
等价于W与特征的乘积。那么回归的目标参数组是什么呢?就是上面四个式子中的逆过程:
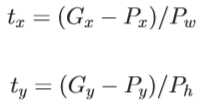
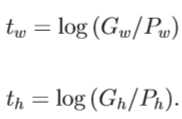 3)
3)
![]() 就是回归的目标参数组。即我们希望对于不同类别分别学一个W,使得对每个类别的候选框在pool5提到的特征与W乘积后可以尽可能的逼近
就是回归的目标参数组。即我们希望对于不同类别分别学一个W,使得对每个类别的候选框在pool5提到的特征与W乘积后可以尽可能的逼近![]() 。很清楚,最小二乘岭回归目标函数:
。很清楚,最小二乘岭回归目标函数:
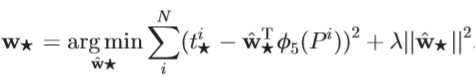 4)
4)
因为是岭回归,所以有一个关于W的L2惩罚项,RCNN论文里给的惩罚因子lambda=1000。还有就是这个回归数据对(P,G)不是随便选的,预测的P应该离至少一个ground truth G很近,这样学出来的参数才有意义。近的度量是P、G的IOU>0.6。
可以看到RCNN的每一个proposal都要经过一次特征提取的过程,这样效率很低,而后续的Fast\Faster-RCNN都是对一张图的feature map上的区域进行bounding box回归。
2) Faster RCNN版本:
较于RCNN,主要有两点不同。
首先,特征不同。RCNN中,回归的特征是每个proposal的经过pool5后的特征,而Faster-RCNN是在整张图的feature map上以3*3大小的卷积不断滑过,每个3*3大小的feature map对应于9个anchor。之后是两个并行1*1的卷积缩小特征通道为4*9(9个abchor的四个坐标)和2*9(9个anchor的0-1类别),分别用来做回归与分类。这也是RPN网络的工作之一。RPN网络也是Faster-RCNN的主要优势。
其次,回归器数目与回归目标函数不同。在Faster-RCNN中不再是class-specific,而是9个回归器。因为feature map上的每个点对应有9个anchor。这9个anchor对应了9种不同的尺度和宽高比。每个回归器只针对1种尺度与宽高比。所以虽然Faster-RCNN中给出的候选框是9种anchor,但是经过多次回归它可以预测出各种大小形状的bounding box,这也归功于anchor的设计。至于回归损失函数,首先看一下预测和目标公式:
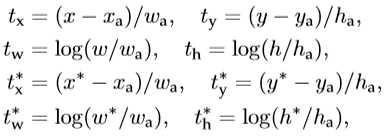
其中x,y,w,h分别为bbox的中心点坐标,宽与高。![]() 分别是预测box、anchor box、真实box。计算类似于RCNN,前两行是预测的box关于anchor的offset与scales,后两行是真实box与anchor的offset与scales。那回归的目的很明显,即使得
分别是预测box、anchor box、真实box。计算类似于RCNN,前两行是预测的box关于anchor的offset与scales,后两行是真实box与anchor的offset与scales。那回归的目的很明显,即使得![]() 尽可能相近。回归损失函数利用的是Fast-RCNN中定义的smooth L1函数,对外点更不敏感:
尽可能相近。回归损失函数利用的是Fast-RCNN中定义的smooth L1函数,对外点更不敏感:
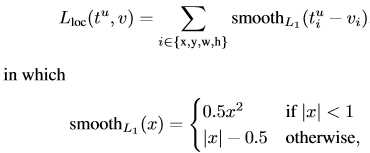
损失函数优化权重W,使得测试时bbox经过W运算后可以得到一个较好的offsets与scales,利用这个offsets与scales可在原预测bbox上微调,得到更好的预测结果。
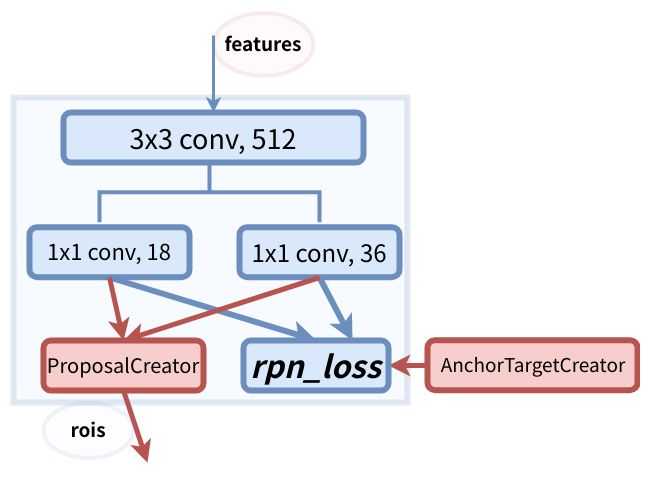
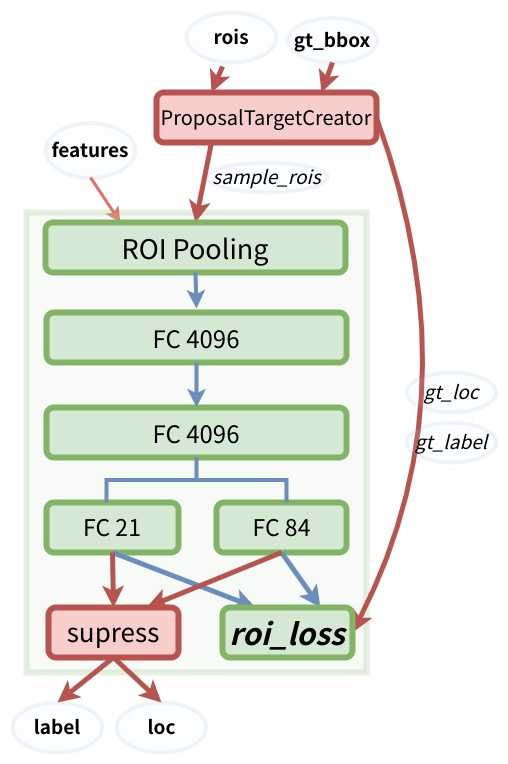
RPN网络 RoIHead网络
RPN网络也是Faster-RCNN中最大的改进。RPN网络的输入为图像特征。RPN网络是全卷积网络。RPN网络要完成的任务是训练自己、提供rois。
训练自己:二分类、bounding box 回归(由AnchorTargetCreator实现)
提供rois:为Fast-RCNN提供训练需要的rois(由ProposalCreator实现)
1)RPN网络综述:
前面提到过,整个训练过程batchsize=1,即每次输入一张图片,所以feature map的shape为(1,512,hh, ww)。那么RPN的输入便是(1,512,hh, ww)。然后经过512个3*3且含pad的卷积后仍为(1,512,hh,ww)。此卷积后shape并没有发生变化,意义是转换语义空间?然后分支出现了。有两路分支,左路是18个1*1卷积,右路是36个1*1卷积。1*1卷积的意义是改变特征维度。那左路卷积后shape为(1,18,hh,ww),右路卷积后shape为(1,36,hh,ww)。左路通道数变为18,是因为每个点对应的9个anchor实现2分类概率预测,所以是9*2 = 18!右路通道数变为36,是因为每个点对应的9个anchor实现4个坐标值的预测,所以是9*4 = 36!
2)RPN网络中AnchorTargetCreator分析:
将20000多个候选的anchor选出256个anchor进行二分类和所有的anchor进行回归位置 。为上面的预测值提供相应的真实值。选择方式如下:
gt_bbox),选择和它重叠度(IoU)最高的一个anchor作为正样本。gt_bbox重叠度超过0.7的anchor,作为正样本,正样本的数目不超过128个。gt_bbox重叠度小于0.3的anchor作为负样本。负样本和正样本的总数为256。对于每个anchor, gt_label 要么为1(前景),要么为0(背景),所以这样实现二分类。在计算回归损失的时候,只计算正样本(前景)的损失,不计算负样本的位置损失。
3) RPN网络中ProposalCreator分析:
RPN利用 AnchorTargetCreator自身训练的同时,还会提供RoIs(region of interests)给Fast RCNN(RoIHead)作为训练样本。RPN生成RoIs的过程(ProposalCreator)如下:
注意:在inference的时候,为了提高处理速度,12000和2000分别变为6000和300.
注意:这部分的操作不需要进行反向传播,因此可以利用numpy/tensor实现。
RPN的输出:RoIs(形如2000×4或者300×4的tensor)
ProposalTargetCreator是RPN网络与ROIHead网络的过渡操作,前面讲过,RPN会产生大约2000个RoIs,这2000个RoIs不是都拿去训练,而是利用ProposalTargetCreator 选择128个RoIs用以训练。选择的规则如下:
为了便于训练,对选择出的128个RoIs,还对他们的gt_roi_loc 进行标准化处理(减去均值除以标准差)
对于分类问题,直接利用交叉熵损失. 而对于位置的回归损失,一样采用Smooth_L1Loss, 只不过只对正样本计算损失.而且是只对正样本中的这个类别4个参数计算损失。举例来说:
1. bbox_tools.py
有关生成、微调bounding box的操作

import numpy as np import numpy as xp import six from six import __init__ def loc2bbox(src_bbox, loc): """Decode bounding boxes from bounding box offsets and scales. Given bounding box offsets and scales computed by :meth:`bbox2loc`, this function decodes the representation to coordinates in 2D image coordinates. Given scales and offsets :math:`t_y, t_x, t_h, t_w` and a bounding box whose center is :math:`(y, x) = p_y, p_x` and size :math:`p_h, p_w`, the decoded bounding box‘s center :math:`\\hat{g}_y`, :math:`\\hat{g}_x` and size :math:`\\hat{g}_h`, :math:`\\hat{g}_w` are calculated by the following formulas. * :math:`\\hat{g}_y = p_h t_y + p_y` * :math:`\\hat{g}_x = p_w t_x + p_x` * :math:`\\hat{g}_h = p_h \\exp(t_h)` * :math:`\\hat{g}_w = p_w \\exp(t_w)` The decoding formulas are used in works such as R-CNN [#]_. The output is same type as the type of the inputs. .. [#] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014. Args: src_bbox (array): A coordinates of bounding boxes. Its shape is :math:`(R, 4)`. These coordinates are :math:`p_{ymin}, p_{xmin}, p_{ymax}, p_{xmax}`. loc (array): An array with offsets and scales. The shapes of :obj:`src_bbox` and :obj:`loc` should be same. This contains values :math:`t_y, t_x, t_h, t_w`. Returns: array: Decoded bounding box coordinates. Its shape is :math:`(R, 4)`. The second axis contains four values :math:`\\hat{g}_{ymin}, \\hat{g}_{xmin}, \\hat{g}_{ymax}, \\hat{g}_{xmax}`. """ if src_bbox.shape[0] == 0: return xp.zeros((0, 4), dtype=loc.dtype) src_bbox = src_bbox.astype(src_bbox.dtype, copy=False) src_height = src_bbox[:, 2] - src_bbox[:, 0] src_width = src_bbox[:, 3] - src_bbox[:, 1] src_ctr_y = src_bbox[:, 0] + 0.5 * src_height src_ctr_x = src_bbox[:, 1] + 0.5 * src_width dy = loc[:, 0::4] dx = loc[:, 1::4] dh = loc[:, 2::4] dw = loc[:, 3::4] ctr_y = dy * src_height[:, xp.newaxis] + src_ctr_y[:, xp.newaxis] ctr_x = dx * src_width[:, xp.newaxis] + src_ctr_x[:, xp.newaxis] h = xp.exp(dh) * src_height[:, xp.newaxis] w = xp.exp(dw) * src_width[:, xp.newaxis] dst_bbox = xp.zeros(loc.shape, dtype=loc.dtype) dst_bbox[:, 0::4] = ctr_y - 0.5 * h dst_bbox[:, 1::4] = ctr_x - 0.5 * w dst_bbox[:, 2::4] = ctr_y + 0.5 * h dst_bbox[:, 3::4] = ctr_x + 0.5 * w return dst_bbox def bbox2loc(src_bbox, dst_bbox): """Encodes the source and the destination bounding boxes to "loc". Given bounding boxes, this function computes offsets and scales to match the source bounding boxes to the target bounding boxes. Mathematcially, given a bounding box whose center is :math:`(y, x) = p_y, p_x` and size :math:`p_h, p_w` and the target bounding box whose center is :math:`g_y, g_x` and size :math:`g_h, g_w`, the offsets and scales :math:`t_y, t_x, t_h, t_w` can be computed by the following formulas. * :math:`t_y = \\frac{(g_y - p_y)} {p_h}` * :math:`t_x = \\frac{(g_x - p_x)} {p_w}` * :math:`t_h = \\log(\\frac{g_h} {p_h})` * :math:`t_w = \\log(\\frac{g_w} {p_w})` The output is same type as the type of the inputs. The encoding formulas are used in works such as R-CNN [#]_. .. [#] Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014. Args: src_bbox (array): An image coordinate array whose shape is :math:`(R, 4)`. :math:`R` is the number of bounding boxes. These coordinates are :math:`p_{ymin}, p_{xmin}, p_{ymax}, p_{xmax}`. dst_bbox (array): An image coordinate array whose shape is :math:`(R, 4)`. These coordinates are :math:`g_{ymin}, g_{xmin}, g_{ymax}, g_{xmax}`. Returns: array: Bounding box offsets and scales from :obj:`src_bbox` to :obj:`dst_bbox`. This has shape :math:`(R, 4)`. The second axis contains four values :math:`t_y, t_x, t_h, t_w`. """ height = src_bbox[:, 2] - src_bbox[:, 0] width = src_bbox[:, 3] - src_bbox[:, 1] ctr_y = src_bbox[:, 0] + 0.5 * height ctr_x = src_bbox[:, 1] + 0.5 * width base_height = dst_bbox[:, 2] - dst_bbox[:, 0] base_width = dst_bbox[:, 3] - dst_bbox[:, 1] base_ctr_y = dst_bbox[:, 0] + 0.5 * base_height base_ctr_x = dst_bbox[:, 1] + 0.5 * base_width eps = xp.finfo(height.dtype).eps height = xp.maximum(height, eps) width = xp.maximum(width, eps) dy = (base_ctr_y - ctr_y) / height dx = (base_ctr_x - ctr_x) / width dh = xp.log(base_height / height) dw = xp.log(base_width / width) loc = xp.vstack((dy, dx, dh, dw)).transpose() return loc def bbox_iou(bbox_a, bbox_b): """Calculate the Intersection of Unions (IoUs) between bounding boxes. IoU is calculated as a ratio of area of the intersection and area of the union. This function accepts both :obj:`numpy.ndarray` and :obj:`cupy.ndarray` as inputs. Please note that both :obj:`bbox_a` and :obj:`bbox_b` need to be same type. The output is same type as the type of the inputs. Args: bbox_a (array): An array whose shape is :math:`(N, 4)`. :math:`N` is the number of bounding boxes. The dtype should be :obj:`numpy.float32`. bbox_b (array): An array similar to :obj:`bbox_a`, whose shape is :math:`(K, 4)`. The dtype should be :obj:`numpy.float32`. Returns: array: An array whose shape is :math:`(N, K)`. An element at index :math:`(n, k)` contains IoUs between :math:`n` th bounding box in :obj:`bbox_a` and :math:`k` th bounding box in :obj:`bbox_b`. """ if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4: raise IndexError # top left tl = xp.maximum(bbox_a[:, None, :2], bbox_b[:, :2]) # bottom right br = xp.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:]) area_i = xp.prod(br - tl, axis=2) * (tl < br).all(axis=2) area_a = xp.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1) area_b = xp.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1) return area_i / (area_a[:, None] + area_b - area_i) def __test(): pass if __name__ == ‘__main__‘: __test() def generate_anchor_base(base_size=16, ratios=[0.5, 1, 2], anchor_scales=[8, 16, 32]): """Generate anchor base windows by enumerating aspect ratio and scales. Generate anchors that are scaled and modified to the given aspect ratios. Area of a scaled anchor is preserved when modifying to the given aspect ratio. :obj:`R = len(ratios) * len(anchor_scales)` anchors are generated by this function. The :obj:`i * len(anchor_scales) + j` th anchor corresponds to an anchor generated by :obj:`ratios[i]` and :obj:`anchor_scales[j]`. For example, if the scale is :math:`8` and the ratio is :math:`0.25`, the width and the height of the base window will be stretched by :math:`8`. For modifying the anchor to the given aspect ratio, the height is halved and the width is doubled. Args: base_size (number): The width and the height of the reference window. ratios (list of floats): This is ratios of width to height of the anchors. anchor_scales (list of numbers): This is areas of anchors. Those areas will be the product of the square of an element in :obj:`anchor_scales` and the original area of the reference window. Returns: ~numpy.ndarray: An array of shape :math:`(R, 4)`. Each element is a set of coordinates of a bounding box. The second axis corresponds to :math:`(y_{min}, x_{min}, y_{max}, x_{max})` of a bounding box. """ py = base_size / 2. px = base_size / 2. anchor_base = np.zeros((len(ratios) * len(anchor_scales), 4), dtype=np.float32) for i in six.moves.range(len(ratios)): for j in six.moves.range(len(anchor_scales)): h = base_size * anchor_scales[j] * np.sqrt(ratios[i]) w = base_size * anchor_scales[j] * np.sqrt(1. / ratios[i]) index = i * len(anchor_scales) + j anchor_base[index, 0] = py - h / 2. anchor_base[index, 1] = px - w / 2. anchor_base[index, 2] = py + h / 2. anchor_base[index, 3] = px + w / 2. return anchor_base
函数bbox2loc输入的是源bbox和目标bbox,然后输出的是参数组,即源bbox相对于bbox的offset和scales。即实现的是上述公式3)。注意对坐标的转换(顶点坐标转为中心、宽高)。
函数loc2bbox输入的是源bbox和参数组,输出的是目标bbox,正好是上面的逆过程,实现的是上述公式2)。bbox2loc称编码过程,那loc2bbox即为解码过程。
函数bbox_iou实现的是交并比IOU,即任给两组bbox(N,4 与 K,4),输出数组shape为(N,K),即求出两组bbox中两两的交并比。
函数generate_anchor_base实现生成9个base anchor,为什么是base呢,因为对于每个feature map平面中的点,都要以此点为中心生成9个anchor。下图所示是以(0,0)为中心:
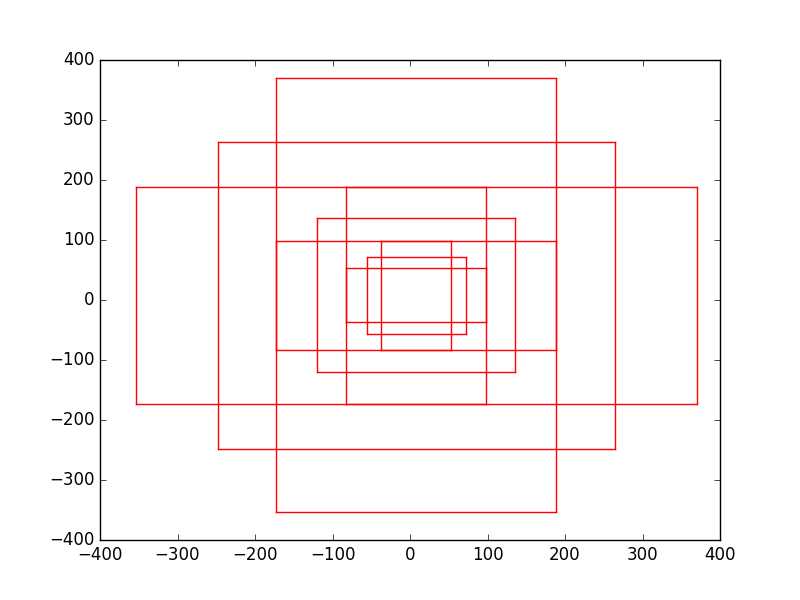
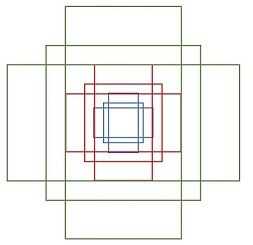
上图是按照论文所述:9个anchor对应于3种scales(面积分别为1282,2562,5122)和3种aspect ratios(宽高比分别为1:1, 1:2, 2:1)。这9个anchor形状应为:
90.50967 *181.01933 = 1282
181.01933 * 362.03867 = 2562
362.03867 * 724.07733 = 5122
128.0 * 128.0 = 1282
256.0 * 256.0 = 2562
512.0 * 512.0 = 5122
181.01933 * 90.50967 = 1282
362.03867 * 181.01933 = 2562
724.07733 * 362.03867 = 5122
该函数返回值为anchor_base,形状9*4,是9个anchor的坐上右下坐标:
-37.2548 -82.5097 53.2548 98.5097
-82.5097 -173.019 98.5097 189.019
-173.019 -354.039 189.019 370.039
-56 -56 72 72
-120 -120 136 136
-248 -248 264 264
-82.5097 -37.2548 98.5097 53.2548
-173.019 -82.5097 189.019 98.5097
-354.039 -173.019 370.039 189.019
那么问题来了,上面这个只产生的是以左上角(0,0)为中心的bbox,如何产生以feature map上的每个点为中心得到的anchor呢?
代码 model / region_proposal_network 中的函数实现了这一操作:
self.anchor_base = generate_anchor_base(anchor_scales=anchor_scales, ratios=ratios) # 首先生成上述以(0,0)为中心的9个base anchor
... n, _, hh, ww = x.shape # x为feature map,n为batch_size,此版本代码为1. hh,ww即为宽高 anchor = _enumerate_shifted_anchor( # 调用下述函数 np.array(self.anchor_base), self.feat_stride, hh, ww) # feat_stride=16 ,因为是经4次pool后提到的特征,故feature map较原图缩小了16倍 ... def _enumerate_shifted_anchor(anchor_base, feat_stride, height, width): # 利用base anchor生成所有对应feature map的anchor # Enumerate all shifted anchors: # anchor_base :(9,4) 坐标,这里 A=9 # # add A anchors (1, A, 4) to # cell K shifts (K, 1, 4) to get # shift anchors (K, A, 4) # reshape to (K*A, 4) shifted anchors # return (K*A, 4) # !TODO: add support for torch.CudaTensor # xp = cuda.get_array_module(anchor_base) # it seems that it can‘t be boosed using GPU import numpy as xp shift_y = xp.arange(0, height * feat_stride, feat_stride) # 纵向偏移量(0,16,32,...) shift_x = xp.arange(0, width * feat_stride, feat_stride) # 横向偏移量(0,16,32,...) shift_x, shift_y = xp.meshgrid(shift_x, shift_y) shift = xp.stack((shift_y.ravel(), shift_x.ravel(), shift_y.ravel(), shift_x.ravel()), axis=1) A = anchor_base.shape[0] # 9 K = shift.shape[0] # K = hh*ww ,K约为20000 anchor = anchor_base.reshape((1, A, 4)) + shift.reshape((1, K, 4)).transpose((1, 0, 2)) anchor = anchor.reshape((K * A, 4)).astype(np.float32) return anchor # 返回(K,4),所有anchor的坐标
分析上述代码:函数_enumerate_shifted_anchor首先生成横向与纵向的偏移量,我们需要将特征图的每一个点放大16倍到原图:
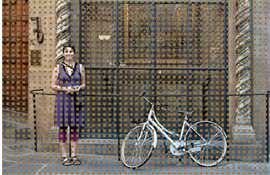
原始图片的锚点中心 ,两两相距16像素 (图源:机器之心)
得到偏移量后我们将每个偏移量与base anchor的坐标相加,即得到所有anchor的左上右下坐标。每张图都约生成有hh*ww=20000个anchor!

左侧:锚点、中心:特征图空间单一锚点在原图中的表达,右侧:所有锚点在原图中的表达 (图源:机器之心)
2. creator_tool.py
import numpy as np import cupy as cp from model.utils.bbox_tools import bbox2loc, bbox_iou, loc2bbox from model.utils.nms import non_maximum_suppression class ProposalTargetCreator(object): """Assign ground truth bounding boxes to given RoIs. The :meth:`__call__` of this class generates training targets for each object proposal. This is used to train Faster RCNN [#]_. .. [#] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NIPS 2015. Args: n_sample (int): The number of sampled regions. pos_ratio (float): Fraction of regions that is labeled as a foreground. pos_iou_thresh (float): IoU threshold for a RoI to be considered as a foreground. neg_iou_thresh_hi (float): RoI is considered to be the background if IoU is in [:obj:`neg_iou_thresh_hi`, :obj:`neg_iou_thresh_hi`). neg_iou_thresh_lo (float): See above. """ def __init__(self, n_sample=128, pos_ratio=0.25, pos_iou_thresh=0.5, neg_iou_thresh_hi=0.5, neg_iou_thresh_lo=0.0 ): self.n_sample = n_sample self.pos_ratio = pos_ratio self.pos_iou_thresh = pos_iou_thresh self.neg_iou_thresh_hi = neg_iou_thresh_hi self.neg_iou_thresh_lo = neg_iou_thresh_lo # NOTE: py-faster-rcnn默认的值是0.1 def __call__(self, roi, bbox, label, loc_normalize_mean=(0., 0., 0., 0.), loc_normalize_std=(0.1, 0.1, 0.2, 0.2)): """Assigns ground truth to sampled proposals. This function samples total of :obj:`self.n_sample` RoIs from the combination of :obj:`roi` and :obj:`bbox`. The RoIs are assigned with the ground truth class labels as well as bounding box offsets and scales to match the ground truth bounding boxes. As many as :obj:`pos_ratio * self.n_sample` RoIs are sampled as foregrounds. Offsets and scales of bounding boxes are calculated using :func:`model.utils.bbox_tools.bbox2loc`. Also, types of input arrays and output arrays are same. Here are notations. * :math:`S` is the total number of sampled RoIs, which equals :obj:`self.n_sample`. * :math:`L` is number of object classes possibly including the background. Args: roi (array): Region of Interests (RoIs) from which we sample. Its shape is :math:`(R, 4)` bbox (array): The coordinates of ground truth bounding boxes. Its shape is :math:`(R‘, 4)`. label (array): Ground truth bounding box labels. Its shape is :math:`(R‘,)`. Its range is :math:`[0, L - 1]`, where :math:`L` is the number of foreground classes. loc_normalize_mean (tuple of four floats): Mean values to normalize coordinates of bouding boxes. loc_normalize_std (tupler of four floats): Standard deviation of the coordinates of bounding boxes. Returns: (array, array, array): * **sample_roi**: Regions of interests that are sampled. Its shape is :math:`(S, 4)`. * **gt_roi_loc**: Offsets and scales to match the sampled RoIs to the ground truth bounding boxes. Its shape is :math:`(S, 4)`. * **gt_roi_label**: Labels assigned to sampled RoIs. Its shape is :math:`(S,)`. Its range is :math:`[0, L]`. The label with value 0 is the background. """ n_bbox, _ = bbox.shape roi = np.concatenate((roi, bbox), axis=0) pos_roi_per_image = np.round(self.n_sample * self.pos_ratio) iou = bbox_iou(roi, bbox) gt_assignment = iou.argmax(axis=1) max_iou = iou.max(axis=1) # Offset range of classes from [0, n_fg_class - 1] to [1, n_fg_class]. # The label with value 0 is the background. gt_roi_label = label[gt_assignment] + 1 # Select foreground RoIs as those with >= pos_iou_thresh IoU. pos_index = np.where(max_iou >= self.pos_iou_thresh)[0] pos_roi_per_this_image = int(min(pos_roi_per_image, pos_index.size)) if pos_index.size > 0: pos_index = np.random.choice( pos_index, size=pos_roi_per_this_image, replace=False) # Select background RoIs as those within # [neg_iou_thresh_lo, neg_iou_thresh_hi). neg_index = np.where((max_iou < self.neg_iou_thresh_hi) & (max_iou >= self.neg_iou_thresh_lo))[0] neg_roi_per_this_image = self.n_sample - pos_roi_per_this_image neg_roi_per_this_image = int(min(neg_roi_per_this_image, neg_index.size)) if neg_index.size > 0: neg_index = np.random.choice( neg_index, size=neg_roi_per_this_image, replace=False) # The indices that we‘re selecting (both positive and negative). keep_index = np.append(pos_index, neg_index) gt_roi_label = gt_roi_label[keep_index] gt_roi_label[pos_roi_per_this_image:] = 0 # negative labels --> 0 sample_roi = roi[keep_index] # Compute offsets and scales to match sampled RoIs to the GTs. gt_roi_loc = bbox2loc(sample_roi, bbox[gt_assignment[keep_index]]) gt_roi_loc = ((gt_roi_loc - np.array(loc_normalize_mean, np.float32) ) / np.array(loc_normalize_std, np.float32)) return sample_roi, gt_roi_loc, gt_roi_label class AnchorTargetCreator(object): """Assign the ground truth bounding boxes to anchors. Assigns the ground truth bounding boxes to anchors for training Region Proposal Networks introduced in Faster R-CNN [#]_. Offsets and scales to match anchors to the ground truth are calculated using the encoding scheme of :func:`model.utils.bbox_tools.bbox2loc`. .. [#] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NIPS 2015. Args: n_sample (int): The number of regions to produce. pos_iou_thresh (float): Anchors with IoU above this threshold will be assigned as positive. neg_iou_thresh (float): Anchors with IoU below this threshold will be assigned as negative. pos_ratio (float): Ratio of positive regions in the sampled regions. """ def __init__(self, n_sample=256, pos_iou_thresh=0.7, neg_iou_thresh=0.3, pos_ratio=0.5): self.n_sample = n_sample self.pos_iou_thresh = pos_iou_thresh self.neg_iou_thresh = neg_iou_thresh self.pos_ratio = pos_ratio def __call__(self, bbox, anchor, img_size): """Assign ground truth supervision to sampled subset of anchors. Types of input arrays and output arrays are same. Here are notations. * :math:`S` is the number of anchors. * :math:`R` is the number of bounding boxes. Args: bbox (array): Coordinates of bounding boxes. Its shape is :math:`(R, 4)`. anchor (array): Coordinates of anchors. Its shape is :math:`(S, 4)`. img_size (tuple of ints): A tuple :obj:`H, W`, which is a tuple of height and width of an image. Returns: (array, array): #NOTE: it‘s scale not only offset * **loc**: Offsets and scales to match the anchors to the ground truth bounding boxes. Its shape is :math:`(S, 4)`. * **label**: Labels of anchors with values :obj:`(1=positive, 0=negative, -1=ignore)`. Its shape is :math:`(S,)`. """ img_H, img_W = img_size n_anchor = len(anchor) inside_index = _get_inside_index(anchor, img_H, img_W) anchor = anchor[inside_index] argmax_ious, label = self._create_label( inside_index, anchor, bbox) # compute bounding box regression targets loc = bbox2loc(anchor, bbox[argmax_ious]) # map up to original set of anchors label = _unmap(label, n_anchor, inside_index, fill=-1) loc = _unmap(loc, n_anchor, inside_index, fill=0) return loc, label def _create_label(self, inside_index, anchor, bbox): # label: 1 is positive, 0 is negative, -1 is dont care label = np.empty((len(inside_index),), dtype=np.int32) label.fill(-1) argmax_ious, max_ious, gt_argmax_ious = self._calc_ious(anchor, bbox, inside_index) # assign negative labels first so that positive labels can clobber them label[max_ious < self.neg_iou_thresh] = 0 # positive label: for each gt, anchor with highest iou label[gt_argmax_ious] = 1 # positive label: above threshold IOU label[max_ious >= self.pos_iou_thresh] = 1 # subsample positive labels if we have too many n_pos = int(self.pos_ratio * self.n_sample) pos_index = np.where(label == 1)[0] if len(pos_index) > n_pos: disable_index = np.random.choice( pos_index, size=(len(pos_index) - n_pos), replace=False) label[disable_index] = -1 # subsample negative labels if we have too many n_neg = self.n_sample - np.sum(label == 1) neg_index = np.where(label == 0)[0] if len(neg_index) > n_neg: disable_index = np.random.choice( neg_index, size=(len(neg_index) - n_neg), replace=False) label[disable_index] = -1 return argmax_ious, label def _calc_ious(self, anchor, bbox, inside_index): # ious between the anchors and the gt boxes ious = bbox_iou(anchor, bbox) argmax_ious = ious.argmax(axis=1) max_ious = ious[np.arange(len(inside_index)), argmax_ious] gt_argmax_ious = ious.argmax(axis=0) gt_max_ious = ious[gt_argmax_ious, np.arange(ious.shape[1])] gt_argmax_ious = np.where(ious == gt_max_ious)[0] return argmax_ious, max_ious, gt_argmax_ious def _unmap(data, count, index, fill=0): # Unmap a subset of item (data) back to the original set of items (of # size count) if len(data.shape) == 1: ret = np.empty((count,), dtype=data.dtype) ret.fill(fill) ret[index] = data else: ret = np.empty((count,) + data.shape[1:], dtype=data.dtype) ret.fill(fill) ret[index, :] = data return ret def _get_inside_index(anchor, H, W): # Calc indicies of anchors which are located completely inside of the image # whose size is speficied. index_inside = np.where( (anchor[:, 0] >= 0) & (anchor[:, 1] >= 0) & (anchor[:, 2] <= H) & (anchor[:, 3] <= W) )[0] return index_inside class ProposalCreator: # unNOTE: I‘ll make it undifferential # unTODO: make sure it‘s ok # It‘s ok """Proposal regions are generated by calling this object. The :meth:`__call__` of this object outputs object detection proposals by applying estimated bounding box offsets to a set of anchors. This class takes parameters to control number of bounding boxes to pass to NMS and keep after NMS. If the paramters are negative, it uses all the bounding boxes supplied or keep all the bounding boxes returned by NMS. This class is used for Region Proposal Networks introduced in Faster R-CNN [#]_. .. [#] Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NIPS 2015. Args: nms_thresh (float): Threshold value used when calling NMS. n_train_pre_nms (int): Number of top scored bounding boxes to keep before passing to NMS in train mode. n_train_post_nms (int): Number of top scored bounding boxes to keep after passing to NMS in train mode. n_test_pre_nms (int): Number of top scored bounding boxes to keep before passing to NMS in test mode. n_test_post_nms (int): Number of top scored bounding boxes to keep after passing to NMS in test mode. force_cpu_nms (bool): If this is :obj:`True`, always use NMS in CPU mode. If :obj:`False`, the NMS mode is selected based on the type of inputs. min_size (int): A paramter to determine the threshold on discarding bounding boxes based on their sizes. """ def __init__(self, parent_model, nms_thresh=0.7, n_train_pre_nms=12000, n_train_post_nms=2000, n_test_pre_nms=6000, n_test_post_nms=300, min_size=16 ): self.parent_model = parent_model self.nms_thresh = nms_thresh self.n_train_pre_nms = n_train_pre_nms self.n_train_post_nms = n_train_post_nms self.n_test_pre_nms = n_test_pre_nms self.n_test_post_nms = n_test_post_nms self.min_size = min_size def __call__(self, loc, score, anchor, img_size, scale=1.): """input should be ndarray Propose RoIs. Inputs :obj:`loc, score, anchor` refer to the same anchor when indexed by the same index. On notations, :math:`R` is the total number of anchors. This is equal to product of the height and the width of an image and the number of anchor bases per pixel. Type of the output is same as the inputs. Args: loc (array): Predicted offsets and scaling to anchors. Its shape is :math:`(R, 4)`. score (array): Predicted foreground probability for anchors. Its shape is :math:`(R,)`. anchor (array): Coordinates of anchors. Its shape is :math:`(R, 4)`. img_size (tuple of ints): A tuple :obj:`height, width`, which contains image size after scaling. scale (float): The scaling factor used to scale an image after reading it from a file. Returns: array: An array of coordinates of proposal boxes. Its shape is :math:`(S, 4)`. :math:`S` is less than :obj:`self.n_test_post_nms` in test time and less than :obj:`self.n_train_post_nms` in train time. :math:`S` depends on the size of the predicted bounding boxes and the number of bounding boxes discarded by NMS. """ # NOTE: when test, remember # faster_rcnn.eval() # to set self.traing = False if self.parent_model.training: n_pre_nms = self.n_train_pre_nms n_post_nms = self.n_train_post_nms else: n_pre_nms = self.n_test_pre_nms n_post_nms = self.n_test_post_nms # Convert anchors into proposal via bbox transformations. # roi = loc2bbox(anchor, loc) roi = loc2bbox(anchor, loc) # Clip predicted boxes to image. roi[:, slice(0, 4, 2)] = np.clip( roi[:, slice(0, 4, 2)], 0, img_size[0]) roi[:, slice(1, 4, 2)] = np.clip( roi[:, slice(1, 4, 2)], 0, img_size[1]) # Remove predicted boxes with either height or width < threshold. min_size = self.min_size * scale hs = roi[:, 2] - roi[:, 0] ws = roi[:, 3] - roi[:, 1] keep = np.where((hs >= min_size) & (ws >= min_size))[0] roi = roi[keep, :] score = score[keep] # Sort all (proposal, score) pairs by score from highest to lowest. # Take top pre_nms_topN (e.g. 6000). order = score.ravel().argsort()[::-1] if n_pre_nms > 0: order = order[:n_pre_nms] roi = roi[order, :] # Apply nms (e.g. threshold = 0.7). # Take after_nms_topN (e.g. 300). # unNOTE: somthing is wrong here! # TODO: remove cuda.to_gpu keep = non_maximum_suppression( cp.ascontiguousarray(cp.asarray(roi)), thresh=self.nms_thresh) if n_post_nms > 0: keep = keep[:n_post_nms] roi = roi[keep] return roi
这个脚本实现了三个Creator函数,分别是:ProposalCreator、AnchorTargetCreator、ProposalTargetCreator
前两个都在RPN网络里实现,第三个在RoIHead网络里实现:
1) AnchorTargetCreator:
目的:利用每张图中bbox的真实标签来为所有任务分配ground truth!
输入:最初生成的20000个anchor坐标、此一张图中所有的bbox的真实坐标
输出:size为(20000,1)的正负label(其中只有128个为1,128个为0,其余都为-1)、 size为(20000,4)的回归目标(所有anchor的坐标都有)
前面讲到每张图进来都会生成约20000个anchor,前面已经分析了这20000个anchor的生成过程。那问题来了,我们在RPN网络里要做三个操作:分类、回归、提供rois 。分类和回归的ground truth 怎么获取?如何给20000个anchor在分类时赋予正负标签gt_rpn_label?如何给回归操作赋予回归目标gt_rpn_loc??? 这就是此creator的目的,利用每张图bbox的真实标签来为所有任务分配ground truth!
注意虽然是给所有20000个anchor赋予了ground truth,但是我们只从中任挑128个正类和128个负类共256个样本来训练。不利用所有样本训练的原因是显然图中负类远多于正类样本数目。同样回归也只挑256个anchor来完成。
此函数首先将一张图中所有20000个anchor中所有完整包含在图像中的anchor筛选出来,假如挑出15000个anchor,要记录下来这部分的索引。
然后利用函数bbox_iou计算15000个anchor与真实bbox的IOU。然后利用函数_create_label根据行列索引分别求出每个anchor与哪个bbox的iou最大,以及最大值,然后返回最大iou的索引argmax_ious(即每个anchor与真实bbox最大iou的索引)与label(label中背景为-1,负样本为0, 正样本为1)。注意虽然是要挑选256个,但是这里返回的label仍然是全部,只不过label里面有128为0,128个为1,其余都为-1而已。然后函数bbox2loc利用返回的索引argmax_ious来计算出回归的目标参数组loc。然后根据之前记录的索引,将15000个再映射回20000长度的label(其余的label一律置为-1)和loc(其余的loc一律置为(0,0,0,0))。有了RPN网络两个1*1卷积输出的类别label和位置参数loc的预测值,AnchorTargetCreator又为其对应生成了真实值ground truth。那么AnchorTargetCreator的损失函数rpn_loss就很了然了:
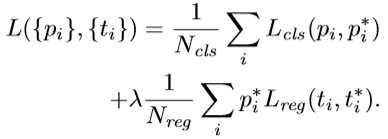
cls代表二分类,reg代表回归。为什么我们挑出来256个label还要映射回20000呢?就是因为这里网络的预测结果(1*1卷积)就是20000个,而我们将要忽略的label都设为了-1,这就允许我们得以筛选,而loc也是一样的道理。所以损失函数里![]() ,而
,而![]() ,hh*ww约为2400, 2400*9约为20000.这也解释了论文中提到要用9个回归器了。
,hh*ww约为2400, 2400*9约为20000.这也解释了论文中提到要用9个回归器了。
2) ProposalCreator :
目的:为Fast-RCNN也即检测网络提供2000个训练样本
输入:RPN网络中1*1卷积输出的loc和score,以及20000个anchor坐标,原图尺寸,scale(即对于这张训练图像较其原始大小的scale)
输出:2000个训练样本rois(只是2000*4的坐标,无ground truth!)
RPN利用 AnchorTargetCreator自身训练的同时,还会提供RoIs(region of interests)给Fast RCNN(RoIHead)作为训练样本。
注意这里首次用到了NMS(非极大值抑制)。利用非极大值抑制可以循环筛选bbox,使得从所有bbox中筛选出期望数量的bbox,这是控制bbox数量的主要方法。函数loc2bbox首先利用RPN网络输出的预测值loc来对20000个anchor进行微调,此时微调后的20000个anchor称之为rois。然后根据原图尺寸将这些rois进行截断在原图像大小内部。然后将此时所有roi中所有宽与高皆大于16的roi的索引记录,假设有18000个roi满足。然后利用预测值score对这些roi从高到低排序,只取前12000个。然后利用NMS进一步筛选,得到2000个roi。
与AnchorTargetCreator的关系:ProposalCreator 只是拿1*1卷积的两路输出loc和score和20000个anchor来选出最终的2000个rois。与AnchorTargetCreator其实并无交集。AnchorTargetCreator所做的事情就是训练,输出真实值来和1*1卷积的两路输出loc和score进行训练,使得网络变好,那这样ProposalCreator 选出来的2000个roi质量会更好,所以他俩唯一的共同点就是都利用了预测的loc和score、20000个原始anchor坐标!
3) ProposalTargetCreator
目的:为2000个rois赋予ground truth!(严格讲挑出128个赋予ground truth!)
输入:2000个rois、一个batch(一张图)中所有的bbox ground truth(R,4)、对应bbox所包含的label(R,1)(VOC2007来说20类0-19)
输出:128个sample roi(128,4)、128个gt_roi_loc(128,4)、128个gt_roi_label(128,1)
ProposalCreator 输出的2000个roi作为ProposalTargetCreator的输入,同时输入的还有一张图上的所有bbox、label的ground trurh。如果此输入图像里有5个object,那么就有5个bbox和5个label。那么这时的三个输入可能是:下面我们将使用此例R=5来分析:

5*4 bbox的ground truth 5*1 label 2000*4个roi
代码首先将2000个roi和5个bbox给concatenate了一下成为新的roi(2005,4)。存疑,我觉得这里没必要concatenate。我们只需要从这新的2005个中挑选128个roi出来来为Fast-RCNN提供训练sample。首先还是调用函数bbox_iou来求roi与bbox的iou矩阵,为(2005,5)。然后记录每行的最大值、最大值索引,即这2005个roi和5个bbox里某个roi最大,那么这个roi就属于某个label。下面就是选128个roi,记录下其中的索引,前32个为正类,后96个为负类。然后利用这128个索引值keep_index就得到了128个sample roi,128个gt_label,将sample_roi和其所属bbox经函数bbox2loc就得到了128个gt_loc。

2005*5 iou矩阵 2005*1 max_iou 2005*1 gt_assignment 2005*1 gt_roi_label(其实筛选后才叫gt_roi_label)
具体筛选过程见下图:
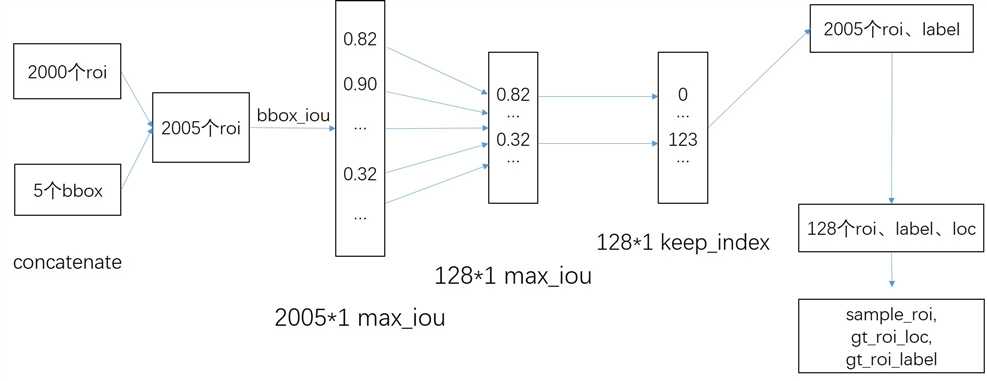
那么此时输出的128*4的sample_roi就可以去扔到 RoIHead网络里去进行分类与回归了。同样, RoIHead网络利用这sample_roi+featue为输入,输出是分类(21类)和回归(进一步微调bbox)的预测值,那么分类回归的groud truth是谁呢?就是ProposalTargetCreator输出的gt_roi_label和gt_roi_loc。那么有了预测值和真实值就能训练损失roi_loss了。注意这里的128个roi肯定是在原图内的,因为ProposalCreator已经将所有roi都截断在原图内了。
与AnchorTargetCreator、ProposalCreator的关系:
ProposalCreator的输出作为此Creator的输入。ProposalTargetCreator和AnchorTargetCreator非常相似了(名字就很相似):都为分类回归损失函数创造ground truth,因为这两个Creator输入都含有一张图片中的gt_bbox。ProposalTargetCreator首次用到了真实的21个类的label。
1. 三个Creator的共同点:
都在各自的类里定义了__call__函数,使对象可以向函数一样调用。都参与训练。
2. rpn_loss与roi_loss的异同:
都是分类与回归的多目标损失。所以Faster-RCNN共有4个子损失函数。
对于 rpn_loss中的分类是2分类,是256个样本参与,正负样本各一半,分类预测值是rpn网络的1*1卷积输出,分类真实标签是AnchorTargetCreator生成的ground truth。 rpn_loss中的回归样本数是所有20000个(严格讲是20000个bbox中所有完整出现在原图中的bbox)bbox来参与,回归预测值是rpn网络的另一个1*1卷积输出,回归目标是AnchorTargetCreator生成的ground truth。
对于roi_loss中的分类是21分类,是128个样本参与,正负样本1:3。分类预测值是Roi_head网络的FC21输出,分类真实标签是ProposalTargetCreator生成的ground truth。roi_loss中的回归样本数是128个,回归预测值是Roi_head网络的FC84输出,回归目标是ProposalTargetCreator生成的ground truth。
Reference:
标签:分享 平面 卷积 等于 标准 cond assigned 分类 部分
原文地址:https://www.cnblogs.com/king-lps/p/8981222.html
