标签:开始 conda reader col task justify mes bsp 应用
1.支持大数据的技术:
存储设备容量不断增加(1PB=1024TB)
计算,CPU处理能力不断提升
网络带宽不断增加
2.大数据特性:4V
(1)大量化(volume)
大数据摩尔定律:数据一直一每年50%的速度增长
1ZB=1024EB,1EB=1024PB,1PB=1024TB
结构化数据/非结构化数据
(2)快速化(velocity)
(3)多样化(variety)
(4)价值(value)
价值密度低
3.大数据影响:
全样而非抽样
效率而非精确
相关而非因果
4.大数据应用:
谷歌预测流感
纸牌屋
5.大数据关键技术:
数据采集
数据隐私,安全
数据存储,管理
数据处理,分析
两大核心:
分布式存储
分布式处理
计算模式:
批处理:MapReduce,spark(可以迭代计算)
流计算:(实时计算)strom,S4,Flume
图计算:图结构数据
查询分析:大规模数据存储与查询:hive
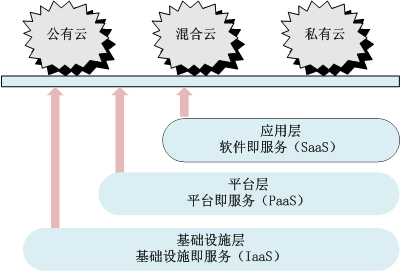
云计算:
SaaS:(SoftWare as a Service)google apps
PaaS:(Platform as a Service)类似于IaaS但包含操作系统和围绕特定的应用的必须服务,平台
IaaS:(Infrastructure as aService)基础设施(计算资源和存储)
云计算数据中心:
自己百度云账户的中的数据在百度的云数据中心
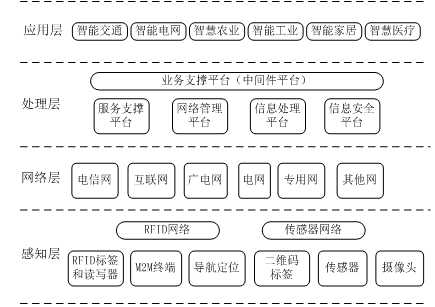
物联网:
Eg1:(掌上智能公交):
公交上GPS定位:移动通信的3G/4G传输模块,将公交车位置实时的通过沿途的移动电信基站传输信息到交通管理站,用户通过Internet访问
Eg2:二维码(矩阵式(分割为小单元):解析填充为0 不填充为1)
物联网体系架构
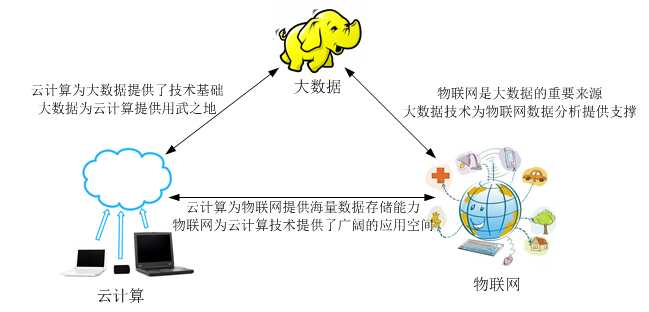
云计算,物联网,大数据关系
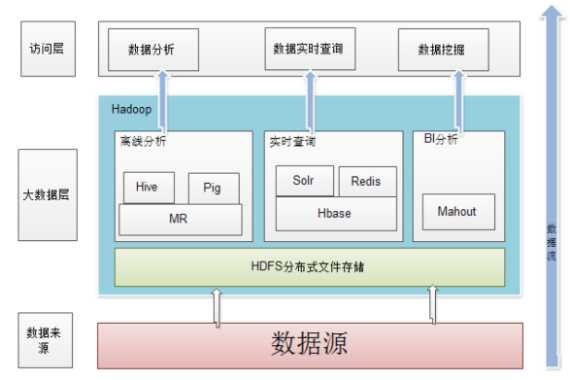
Hadoop
核心:分布式文件系统HDFS(Hadoop distributed file system)和MapReduce
应用架构:
版本区分:
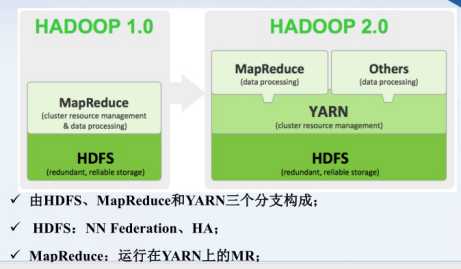 YARN资源调度
YARN资源调度
HDFS:有NN(name node)
项目结构:
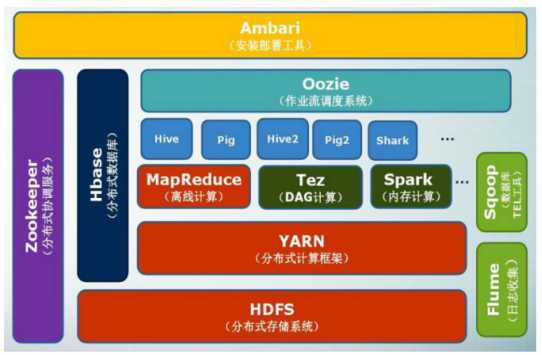
MapReduce:1.从磁盘或网络读取数据(IO密集工作)2.计算数据(CPU密集工作)
Hadoop集群节点:
NameNode:
DataNode:
JobTracker:
MapReduce
TaskTracker:
SecondaryNameNode:
HDFS(分布式文件系统)
块:默认一个块64MB,一个文件被分为多个块
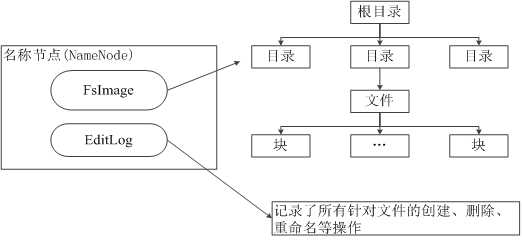
NameNode:负责管理分布式文件系统的命名空间(NameSpace)
两个核心数据结构:
Fslmage:维护文件系统树以及文件树中所有文件,文件夹的元数据
EditLog:操作日志文件
冗余保存数据:(一个数据块的多个副本会被分布到不同的数据节点上)
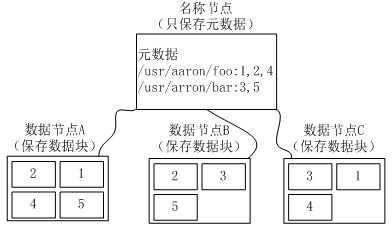
(1)加快数据传输速度
(2)容易检查数据错误
(3)保证数据可靠性
//读取文件: import java.io.BufferedReader; import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.FSDataInputStream; public class Chapter3 { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); Path filename = new Path(“hdfs://localhost:9000/user/hadoop/test.txt"); FSDataInputStream is = fs.open(filename); BufferedReader d = new BufferedReader(new InputStreamReader(is)); String content = d.readLine(); //读取文件一行 System.out.println(content); d.close(); //关闭文件 fs.close(); //关闭hdfs } catch (Exception e) { e.printStackTrace(); } } }
//写入文件: import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; public class Chapter3 { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); byte[] buff = "Hello world".getBytes(); // 要写入的内容 String filename = " hdfs://localhost:9000/user/hadoop/test.txt "; //要写入的文件名 FSDataOutputStream os = fs.create(new Path(filename)); os.write(buff,0,buff.length); System.out.println("Create:"+ filename); } catch (Exception e) { e.printStackTrace(); } } }
HBase(一个稀疏、多维度、排序的映射表)
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据,处理庞大的表
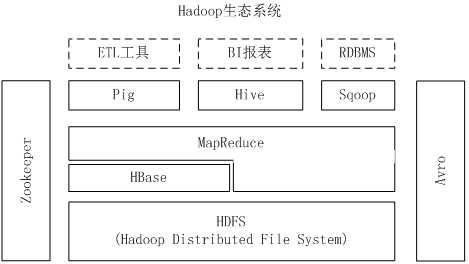
Zookeeper(协同服务管理)负责集群管理
??? 关系数据库已经流行很多年,并且Hadoop已经有了HDFS和MapReduce,为什么需要HBase?
(1)使得Hadoop无法满足大规模数据实时处理应用的需求
(2)HDFS面向批量访问模式,不是随机访问模式
存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的
关系数据库是基于行模式存储的(行式存储的缺:要想分析某个属性必须扫描所有行得到某列的值才能进行分析)
HBase数据模型
1.只有一个索引 ====== 行键、列族、列限定符和时间戳
2.无数据类型,字节数组byte[]
3.每一行都有一个可排序行键和任意多列
4.更新数据不会删除旧数据(HDFS只允许追加不可修改)
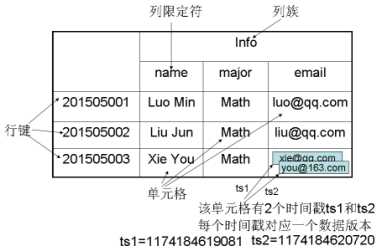
表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
列限定符:列族里的数据通过列限定符(或列)来定位
时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
HBase功能组件:
客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据
客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小
表开始只有一个Region,Region分裂(快速,只是修改指向信息,数据还是存储在旧的Region中),同一个Region不会拆分到不同Region服务器
Region定位
三层结构:
Region ID  Region服务器ID
Region服务器ID
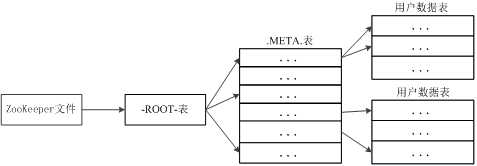
三级寻址
寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器
HBase
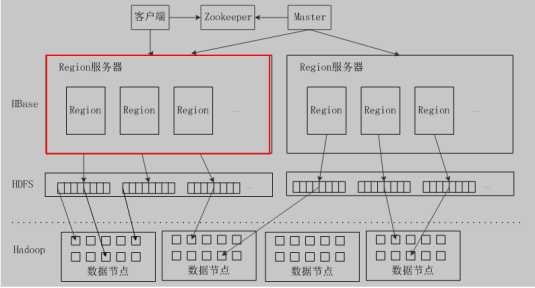
Zookeeper:选出一个Master作为集群管理,并保证任何时候都有唯一一个Master运行
Master: 管理用户表的增删改查;实现不同Region服务器之间的负载均衡;Region分裂,合并后,重新调整Region的分布;Region服务器发生故障失效时,迁移上面的Region
Region服务器:负责维护分配自己的Region,响应用户读写请求
Region服务器
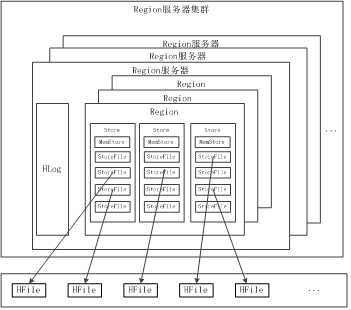
Hlog:日志,一个Region服务器共有一份
用户数据首先被写入到MemStore和Hlog中,只有当操作写入Hlog之后,commit()调用才会将其返回给客户端
MemStore:数据会先写入MemStore缓存,存满之后刷写到StoreFile
系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记
每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件
每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,最后删除旧的Hlog文件,开始为用户提供服务
StoreFile:在HBASE中的表示,实际上在HDFS中存储的为HFile文件格式
每次刷写都生成一个新的StoreFile,调用Store.compact()把多个合并成一个
Store:列族
多个StoreFile合并成一个
单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region
标签:开始 conda reader col task justify mes bsp 应用
原文地址:https://www.cnblogs.com/gree/p/8807458.html