标签:style blog http io os 使用 ar for 文件
决策树有着非常广泛的应用,可以用于分类和回归问题。以下针对分类问题对决策树进行分析。
分类情况下,可以处理离散(if-then)的特征空间,也可以是连续(阈值化的if-than)的特征空间。
决策树由结点和边构成,其中结点分内结点(属性,特征)和外结点(类别)。边上代表着判别的规则,即if-then规则——Splitting datasets one feature at a time.
思想,决策树的每个分枝根据边代表的属性利用if-then规则将特征分类,直至获得分类的结果。
决策树的训练属于监督学习,训练生成的决策树作为分类器用于新样本的分类决策。因为决策树的生成可能会产生过拟合,需要提前停止树的生成或剪枝来解决。
决策树的三个主要问题,特征选择,生成,剪枝。其中特征的选择的概念,即熵、信息增益/比的概念很重要。
决策树的主要流行方法有,C3,C4.5,CART。
?
决策树的优点:
一、 决策树易于理解和解释.人们在通过解释后都有能力去理解决策树所表达的意义。
二、 对于决策树,数据的准备往往是简单或者是不必要的.其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
三、 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
四、 决策树是一个白盒模型。如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
五、 易于通过静态测试来对模型进行评测。表示有可能测量该模型的可信度。
六、 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
七、 可以对有许多属性的数据集构造决策树。
八、 决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小。
?
决策树的缺点:
一、 对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
二、 决策树处理缺失数据时的困难。
三、 过度拟合问题的出现。
四、 忽略数据集中属性之间的相关性。
?
下图是weka软件安装目录下自带的测试数据例子。
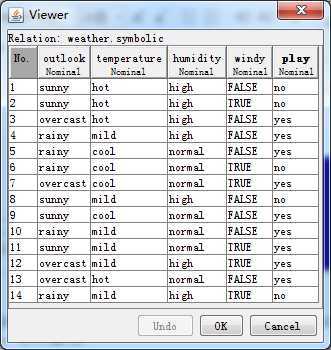
这个数据文件内容表示的意思是:在不同的天气情况下,是否去玩。
一共有14个实例(天数),五种属性(天气外观,温度,湿度,有无风,是否玩),前四种是特征,最后一种是分类结果。这个例子的数值域都是离散的。
就以这个例子讲决策树的基本概念。
以下是weka中用决策树J48 (C4.5)算法生成的例子。
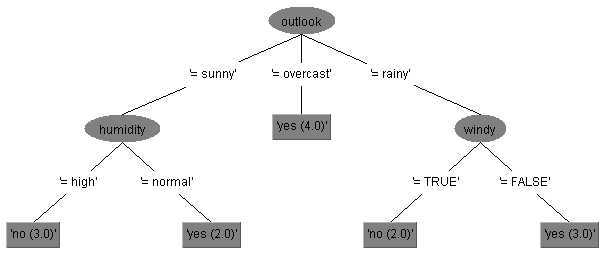
根据这个图我们来分析下决策树的基本要素。
决策树结构,结点和边构成的决策树,其中结点分内结点(特征)和外结点(类别)
边上代表着判别的规则,即if-then规则。I.E. Splitting datasets one feature at a time
发现没有少用了一个特征"温度",因为这个特征最不重要,而且加上它有可能并不能提高整体性能,即可能产生过拟合。
为了避免过拟合,办法有提前终止树的生成,和剪枝。
综上,决策树的三个主要问题,特征选择,生成,剪枝。具体细节请看《统计学习理论》李航。以下只叙述大致框架和要点
一共有14个实例,每个实例可以建立一个if-then规则来确定分类,如第1个实例:if(天气晴,温度高,湿度大,无风),then(不玩)。那么根据训练数据就可建立14种规则,但是一共有4!种情况,对新的实例并不能很好的分类,因此并不能这样简单的建立。
那该如何建立呢,根据机器学习监督学习分类的基本目标,要建立一套规则能很好的拟合训练实例情况,又能够有很好的泛化能力,即预测未知实例情况。所以在if-then规则中,要选取最好的特征来进行分类。
那什么是较好的特征呢?想想看,如果取极端的情况,要求这个例子中四个特征中只选择一个特征来进行分类,你会选择哪个作为if的判别条件呢?也就是选定一个特征后,其他特征先不看,根据这个特征从训练实例中来建立if-then规则进行分类,比如选第十个特征"风",8次无风情况下其中2次不去,6次有风情况下其中3次不去。那么根据概率大的情况作为判定结果。规则是:if(有风),then(不去或者去,因为概率一样);if(无风),then(去)。根据这样的规则就能建立一个树结构模型。还能算出训练的错误率为(2+3)/14。然后看看分别单独选不同情况下的错误率哪个最小。显然为了使得训练误差要小,就选择那样的特征——错误率哪个最小代表的特征。这种很好理解的规则,就是使分类误差率最小。
根据这样的方法选好的以一个if-then规则中使用的特征,然后根据情况划分成几块情况,每块又可以重复上述过程,程序中表现为迭代。每次选择特征使用的方法就是启发式算法,得到次优解。因为建立一套整体规则是NP问题,并且生成这一套整体规则可以用树来表示,称之为决策树。
那还有哪些启发式算法可以作为选特征的依据吗?看下图
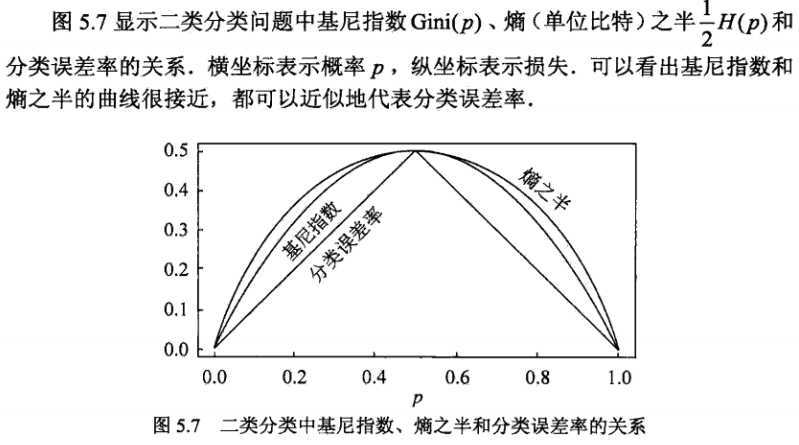
是的,还有熵、基尼指数可以作为选取特征的衡量标准来使用。下面就只说关于熵的。

一句话:熵也大,随机变量的不确定性也越大。

因此选择信息增益大的特征,来作为if-then规则的判别条件,这就是决策树ID3的核心思想。
而改进的C4.5算法中,使用的是如下信息增益比来选取特征。

以下例子和程序来自《机器学习实战》第三章,以ID3算法为例,程序不全,附件有全程序是课本的代码。
程序:计算熵
def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {} for featVec in dataSet: #the the number of unique elements and their occurance currentLabel = featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 shannonEnt = 0.0 for key in labelCounts: prob = float(labelCounts[key])/numEntries shannonEnt -= prob * log(prob,2) #log base 2 return shannonEnt |
?
程序:根据信息增益比来选取特征
def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0; bestFeature = -1 for i in range(numFeatures): #iterate over all the features featList = [example[i] for example in dataSet]#create a list of all the examples of this feature uniqueVals = set(featList) #get a set of unique values newEntropy = 0.0 for value in uniqueVals: subDataSet = splitDataSet(dataSet, i, value) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy if (infoGain > bestInfoGain): #compare this to the best gain so far bestInfoGain = infoGain #if better than current best, set to best bestFeature = i return bestFeature #returns an integer |
?
内结点(特征)中选好特征来做为if-then规则的判别条件,根据不同情况在每条边上划分结点,检测结点是否满足成为外结点(类别)的情况,满足就把类别多的结果作为外结点(类别)表示的类。不满足就就是内结点(特征),就重复上一句话的做法(递推)。


程序:生成树
def createTree(dataSet,labels): classList = [example[-1] for example in dataSet] if classList.count(classList[0]) == len(classList): return classList[0]#stop splitting when all of the classes are equal if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet return majorityCnt(classList) bestFeat = chooseBestFeatureToSplit(dataSet) bestFeatLabel = labels[bestFeat] myTree = {bestFeatLabel:{}} del(labels[bestFeat]) featValues = [example[bestFeat] for example in dataSet] uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] #copy all of labels, so trees don‘t mess up existing labels myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels) return myTree |
?
像CD3算法这样递归的产生决策树,因为规则用的过多,过细,树会建的很大,可能会较好的拟合训练数据,但容易产生过拟合,不能很好的预测未知数据的分类结果。
为了避免过拟合,办法有提前终止树的生成,和剪枝。
避免过拟合的方法:

?


构建好的决策树,可以保存好,用于测试集进行分类。
程序:使用构建好的决策树来对测试集进行分类
def classify(inputTree,featLabels,testVec): firstStr = inputTree.keys()[0] secondDict = inputTree[firstStr] featIndex = featLabels.index(firstStr) key = testVec[featIndex] valueOfFeat = secondDict[key] if isinstance(valueOfFeat, dict): classLabel = classify(valueOfFeat, featLabels, testVec) else: classLabel = valueOfFeat return classLabel |
?
这是树的存储结构
{‘tearRate‘: {‘reduced‘: ‘no lenses‘, ‘normal‘: {‘astigmatic‘: {‘yes‘: {‘prescript‘: {‘hyper‘: {‘age‘: {‘pre‘: ‘no lenses‘, ‘presbyopic‘: ‘no lenses‘, ‘young‘: ‘hard‘}}, ‘myope‘: ‘hard‘}}, ‘no‘: {‘age‘: {‘pre‘: ‘soft‘, ‘presbyopic‘: {‘prescript‘: {‘hyper‘: ‘soft‘, ‘myope‘: ‘no lenses‘}}, ‘young‘: ‘soft‘}}}}}}
决策树的结构
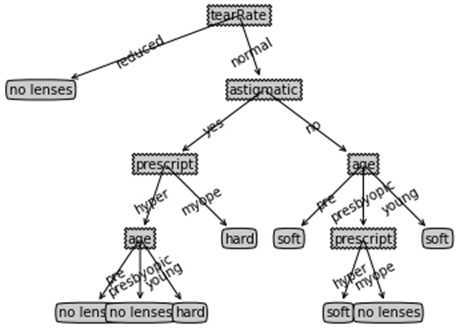
新的测试数据就可以用以上规则来划分类型了。
?
参考:
《统计学习理论》,李航
《机器学习实战》
pedro domingos‘s machine learning course at coursera
各种分类算法比较from http://bbs.pinggu.org/thread-2604496-1-1.html
标签:style blog http io os 使用 ar for 文件
原文地址:http://www.cnblogs.com/Jay-Zen/p/3993399.html