标签:内容 接下来 并且 语句 开始 ima 建立 方法 表示法
下面从模型涉及到的符号开始介绍。
以命名实体识别问题为例。命名实体系统可以自动识别出文本中出现的人名、公司名、时间、地点、国家名、货币名等。
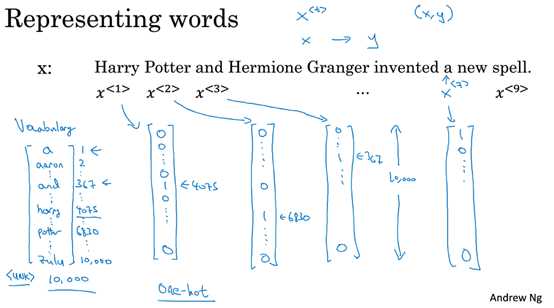
现在,我们要建立一个能够自动识别句子中人名位置的序列模型。它的输入语句是:
x: Harry Potter and Hermione Granger invented a new spell.
给定输入x,我们想让这个序列模型输出y,使得输入的每个单词都对应一个输出值,表示输入单词是否是人名的一部分(输出1表示是人名的一部分,输出0表示不是人名的一部分)。
上面的输入数据是9个单词组成的序列,我们用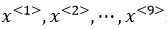 来表示这9个单词。
来表示这9个单词。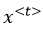 表示输入序列中第t个单词。输出序列也是一样。输出与输入单词一一对应,用
表示输入序列中第t个单词。输出序列也是一样。输出与输入单词一一对应,用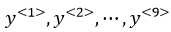 表示。同时,我们用
表示。同时,我们用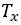 来表示输入序列的长度,此处
来表示输入序列的长度,此处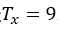 。我们使用
。我们使用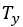 来表示输出序列的长度,此处,
来表示输出序列的长度,此处,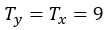 。其他情况,
。其他情况,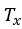
与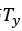 可能不相同。
可能不相同。
我们用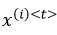 来表示第i个训练样本的第t个元素,
来表示第i个训练样本的第t个元素,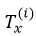 表示第i个训练样本的长度;同样地,
表示第i个训练样本的长度;同样地,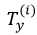 表示第i个训练样本的输出序列长度。
表示第i个训练样本的输出序列长度。

那么如何表示一个序列里单独的单词呢?如何表示像Harry这样的单词?
我们需要做一张词表,也称为词典。假如我要做一个包含10000个单词的词典,那么构建这个词典的一个方法就是遍历你的训练集,并且找到前10000个常用单词;或者你也可以去浏览一些网络词典,找出英语里最常用的10000个单词。假设在这个字典中,a是第一个单词,Harry是第4075个单词,最后一个单词是zulu。接下来我们可以用One-hot表示法来表示词典里的每个单词。举个例子,在这里表示Harry这个单词,那么
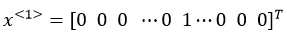
其中第4075行是1,其余都是0的向量。
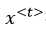 指代句子里的任意词,用One-hot表示,它只有一个1值,其余都是0。所以上面的例子中会有9个One-hot向量来表示上面的输入x。
指代句子里的任意词,用One-hot表示,它只有一个1值,其余都是0。所以上面的例子中会有9个One-hot向量来表示上面的输入x。
接下来我们就可以建立一个序列模型,来学习输入x和目标输出y之间的一个映射,这是一个监督学习。
最后,如果输入序列中的单词在词典中不存在,那么可以创建一个新的标记,Unknown Word,UNK,表示不在词典里面的单词。
注:内容主要来自:Andrew NG的序列模型课程。
标签:内容 接下来 并且 语句 开始 ima 建立 方法 表示法
原文地址:https://www.cnblogs.com/hejunlin1992/p/8999454.html