转自:https://blog.csdn.net/cymy001/article/details/79169862
特征生成
特征工程中引入的新特征,需要验证它确实能提高预测得准确度,而不是加入一个无用的特征增加算法运算的复杂度。
1. 时间戳处理
时间戳属性通常需要分离成多个维度比如年、月、日、小时、分钟、秒钟。但是在很多的应用中,大量的信息是不需要的。比如在一个监督系统中,尝试利用一个’位置+时间‘的函数预测一个城市的交通故障程度,这个实例中,大部分会受到误导只通过不同的秒数去学习趋势,其实是不合理的。并且维度’年’也不能很好的给模型增加值的变化,我们可能仅仅需要小时、日、月等维度。因此在呈现时间的时候,试着保证你所提供的所有数据是你的模型所需要的。并且别忘了时区,假如你的数据源来自不同的地理数据源,别忘了利用时区将数据标准化。
2. 分解类别属性(one-hot)
一些属性是类别型而不是数值型,举一个简单的例子,由{红,绿、蓝}组成的颜色属性,最常用的方式是把每个类别属性转换成二元属性,即从{0,1}取一个值。因此基本上增加的属性等于相应数目的类别,并且对于你数据集中的每个实例,只有一个是1(其他的为0),这也就是独热(one-hot)编码方式(类似于转换成哑变量)。
如果你不了解这个编码的话,你可能会觉得分解会增加没必要的麻烦(因为编码大量的增加了数据集的维度)。相反,你可能会尝试将类别属性转换成一个标量值,例如颜色属性可能会用{1,2,3}表示{红,绿,蓝}。这里存在两个问题,首先,对于一个数学模型,这意味着某种意义上红色和绿色比和蓝色更“相似”(因为|1-3| > |1-2|)。除非你的类别拥有排序的属性(比如铁路线上的站),这样可能会误导你的模型。然后,可能会导致统计指标(比如均值)无意义,更糟糕的情况是,会误导你的模型。还是颜色的例子,假如你的数据集包含相同数量的红色和蓝色的实例,但是没有绿色的,那么颜色的均值可能还是得到2,也就是绿色的意思。
能够将类别属性转换成一个标量,最有效的场景应该就是只有两个类别的情况。即{0,1}对应{类别1,类别2}。这种情况下,并不需要排序,并且你可以将属性的值理解成属于类别1或类别2的概率。
3.分箱/分区(数值型转类别型)
有时候,将数值型属性转换成类别型更有意义,同时将一定范围内的数值划分成确定的块,使算法减少噪声的干扰。只有在了解属性的领域知识的基础,确定属性能够划分成简洁的范围时分区才有意义,即所有的数值落入一个分区时能够呈现出共同的特征。在实际应用中,当你不想让你的模型总是尝试区分值之间是否太近时,分区能够避免过拟合。例如,如果你所感兴趣的是将一个城市作为整体,这时你可以将所有落入该城市的维度值进行整合成一个整体。分箱也能减小小错误的影响,通过将一个给定值划入到最近的块中。如果划分范围的数量和所有可能值相近,或对你来说准确率很重要的话,此时分箱就不适合了。
4. 交叉特征(组合分类特征)
交叉特征算是特征工程中非常重要的方法之一了,它是将两个或更多的类别属性组合成一个。当组合的特征要比单个特征更好时,这是一项非常有用的技术。数学上来说,是对类别特征的所有可能值进行交叉相乘。假如拥有一个特征A,A有两个可能值{A1,A2}。拥有一个特征B,存在{B1,B2}等可能值。然后,A&B之间的交叉特征如下:{(A1,B1),(A1,B2),(A2,B1),(A2,B2)},并且你可以给这些组合特征取任何名字,但是需要明白每个组合特征其实代表着A和B各自信息协同作用。一个更好地诠释好的交叉特征的实例是类似于(经度,纬度)。一个相同的经度对应了地图上很多的地方,纬度也是一样。但是一旦你将经度和纬度组合到一起,它们就代表了地理上特定的一块区域,区域中每一部分是拥有着类似的特性。
5. 特征选择
为了得到更好的模型,使用某些算法自动的选出原始特征的子集。这个过程,你不会构建或修改你拥有的特征,但是会通过修剪特征来达到减少噪声和冗余。在数据特征中,存在一些对于提高模型的准确率比其他更重要的特征,也还有一些与其他特征放在一起出现了冗余,特征选择是自动选出对于解决问题最有用的特征子集来解决上述问题的。特征选择算法可能会用评分方法排名和选择特征,比如相关性或其他确定特征重要性的方法,更进一步的方法可能需要通过试错,来搜索出特征子集。
还可以构建辅助模型,逐步回归就是模型构造过程中自动执行特征选择算法的一个实例,还有像Lasso回归和岭回归等正则化方法也被归入到特征选择,通过加入额外的约束或者惩罚项加到已有模型(损失函数)上,以防止过拟合并提高泛化能力。
6. 特征缩放
某些特征比其他特征具有较大的跨度值。举个例子,将一个人的收入和他的年龄进行比较,更具体的例子,如某些模型(像岭回归)要求你必须将特征值缩放到相同的范围值内。通过缩放可以避免某些特征比其他特征获得大小非常悬殊的权重值。
7. 特征提取
特征提取涉及到从原始属性中自动生成一些新的特征集的一系列算法,降维算法就属于这一类。特征提取是一个自动将观测值降维到一个足够建模的小数据集的过程。对于列表数据,可使用的方法包括一些投影方法,像主成分分析和无监督聚类算法。对于图形数据,可能包括一些直线检测和边缘检测,对于不同领域有各自的方法。
特征提取的关键点在于这些方法是自动的(只需要从简单方法中设计和构建得到),还能够解决不受控制的高维数据的问题。大部分的情况下,是将这些不同类型数据(如图,语言,视频等)存成数字格式来进行模拟观察。
特征选择
(1)子集产生:按照一定的搜索策略产生候选特征子集;
(2)子集评估:通过某个评价函数评估特征子集的优劣;
(3)停止条件:决定特征选择算法什么时候停止;
(4)子集验证:用于验证最终所选的特征子集的有效性。
特征选择的搜索策略分为:完全搜索策略、启发式策略以及随机搜索策略。
特征选择本质上是一个组合优化问题,求解组合优化问题最直接的方法就是搜索,理论上可以通过穷举法来搜索所有可能的特征组合,选择使得评价标准最优的特征子集作为最后的输出,但是n个特征的搜索空间为2n,穷举法的运算量随着特征维数的增加呈指数递增,实际应用中经常碰到几百甚至成千上万个特征,因此穷举法虽然简单却难以实际应用。其他的搜索方法有启发式搜索和随机搜索,这些搜索策略可以在运算效率和特征子集质量之间寻找到一个较好的平衡点,而这也是众多特征选择算法努力的目标。
完全搜索(Complete)
广度优先搜索( Breadth First Search ):广度优先遍历特征子空间。枚举所有组合,穷举搜索,实用性不高。
分支限界搜索( Branch and Bound ):穷举基础上加入分支限界。例如:剪掉某些不可能搜索出比当前最优解更优的分支。
其他,如定向搜索 (Beam Search ),最优优先搜索 ( Best First Search )等。
启发式搜索(Heuristic)
序列前向选择(SFS,Sequential Forward Selection):从空集开始,每次加入一个选最优。
序列后向选择(SBS,Sequential Backward Selection):从全集开始,每次减少一个选最优。
增L去R选择算法 (LRS,Plus-L Minus-R Selection):从空集开始,每次加入LL个,减去RR个,选最优(L>RL>R)或者从全集开始,每次减去RR个,增加LL个,选最优(L<RL<R)。
其他,如双向搜索(BDS,Bidirectional Search),序列浮动选择(Sequential Floating Selection)等。
随机搜索(Random)
随机产生序列选择算法(RGSS, Random Generation plus Sequential Selection):随机产生一个特征子集,然后在该子集上执行SFS与SBS算法。
模拟退火算法( SA, Simulated Annealing ):以一定的概率接受一个比当前解要差的解,而且这个概率随着时间推移逐渐降低。
遗传算法( GA, Genetic Algorithms ):通过交叉、突变等操作繁殖出下一代特征子集,并且评分越高的特征子集被选中参加繁殖的概率越高。
随机算法共同缺点:依赖随机因素,实验结果难重现。
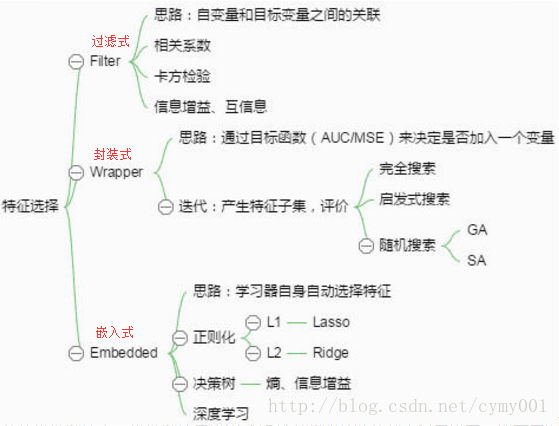
Embedded:在嵌入式特征选择中,特征选择算法本身作为组成部分嵌入到学习算法里。最典型的即决策树算法,如ID3、C4.5以及CART算法等,决策树算法在树增长过程的每个递归步都必须选择一个特征,将样本集划分成较小的子集,选择特征的依据通常是划分后子节点的纯度,划分后子节点越纯,则说明划分效果越好,可见决策树生成的过程也就是特征选择的过程。
Filter:过滤式特征选择的评价标准从数据集本身的内在性质获得,与特定的学习算法无关,因此具有较好的通用性。通常选择和类别相关度大的特征或者特征子集。过滤式特征选择的研究者认为,相关度较大的特征或者特征子集会在分类器上获得较高的准确率。过滤式特征选择的评价标准分为四种,即距离度量、信息度量、关联度度量以及一致性度量。
优点:算法的通用性强;省去了分类器的训练步骤,算法复杂性低,因而适用于大规模数据集;可以快速去除大量不相关的特征,作为特征的预筛选器非常合适。缺点:由于算法的评价标准独立于特定的学习算法,所选的特征子集在分类准确率方面通常低于Wrapper方法。
Wrapper:封装式特征选择是利用学习算法的性能评价特征子集的优劣。因此,对于一个待评价的特征子集,Wrapper方法需要训练一个分类器,根据分类器的性能对该特征子集进行评价。Wrapper方法中用以评价特征的学习算法是多种多样的,例如决策树、神经网络、贝叶斯分类器、近邻法、支持向量机等等。
优点:相对于Filter方法,Wrapper方法找到的特征子集分类性能通常更好。缺点:Wrapper方法选出的特征通用性不强,当改变学习算法时,需要针对该学习算法重新进行特征选择;由于每次对子集的评价都要进行分类器的训练和测试,所以算法计算复杂度很高,尤其对于大规模数据集来说,算法的执行时间很长。
非监督特征学习的目标是捕捉高维数据中的底层结构,挖掘出低维的特征。
在特征学习中,K-means算法可以将一些没有标签的输入数据进行聚类,然后使用每个类别的质心来生成新的特征。
以上内容参考:
1)http://www.dataguru.cn/article-9861-1.html
2)https://www.jianshu.com/p/ab697790090f