标签:img 资料 oca 主机名 ram one ati ica nfa
vim /etc/hosts
172.16.213.8 solrmaster s27
172.16.213.12 solrslave1 ss1
172.16.213.13 solrslave2 ss2
172.16.213.9 solrslave3 ss3
172.16.213.10 solrslave4 ss4
172.16.213.14 solrslave5 ss5
172.16.213.11 solrslave6 ss6
./solr create_collection -c collection_coupon -n collection_coupon -shards 6 -replicationFactor 3
-d /opt/lucidworks-hdpsearch/solr/server/solr/configsets/coupon_schema_configs/conf
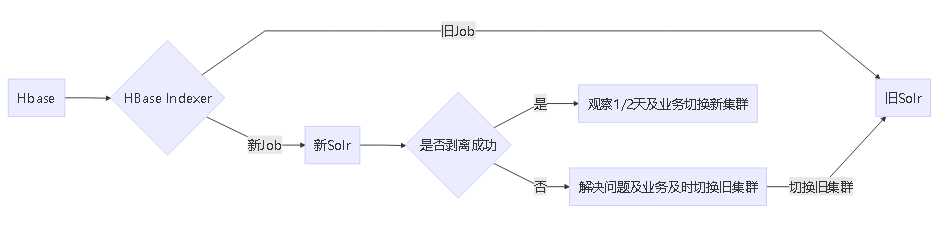
可以通过scp把旧的配置的配置文件拷贝到新集群,保证配置一致,以免出现莫名的错误。
./hbase-indexer add-indexer -n indexer_coupon_solr -c /opt/lucidworks-hdpsearch/hbase-indexer/demo/coupon_indexer_mapper.xml
-cp solr.zk=solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr -cp solr.collection=collection_coupon
这里要注意solr.zk 的设置,一定要设置为新加入solr集群的zk
./hbase-indexer list-indexers
remote_indexer_coupon
+ Lifecycle state: ACTIVE
+ Incremental indexing state: SUBSCRIBE_AND_CONSUME
+ Batch indexing state: INACTIVE
+ SEP subscription ID: Indexer_remote_indexer_coupon
+ SEP subscription timestamp: 2018-05-07T18:04:28.434+08:00
+ Connection type: solr
+ Connection params:
+ solr.zk = solrslave1:2181,solrslave2:2181,solrslave3:2181,solrslave4:2181,solrslave5:2181,solrslave6:2181/solr
+ solr.collection = collection_coupon
+ Indexer config:
940 bytes, use -dump to see content
+ Indexer component factory: com.ngdata.hbaseindexer.conf.DefaultIndexerComponentFactory
+ Additional batch index CLI arguments:
(none)
+ Default additional batch index CLI arguments:
(none)
+ Processes
+ 1 running processes
+ 0 failed processes
在Processes中,关键是否有1个任务是否正在运行,如果没有或者失败,检查修复
su hdfs
hadoop jar /opt/lucidworks-hdpsearch/hbase-indexer/tools/hbase-indexer-mr-1.6-SNAPSHOT-job.jar
--conf /opt/lucidworks-hdpsearch/hbase-indexer/conf/hbase-site.xml --hbase-indexer-zk localhost:2181
--hbase-indexer-name indexer_coupon_solr --reducers 0
注意观察日志信息,如果没有错误,继续下面的操作
在操作过程中也可以参考我以前的文章
标签:img 资料 oca 主机名 ram one ati ica nfa
原文地址:https://www.cnblogs.com/lzh-boy/p/9009836.html