标签:代码 文档 table 资料 部分 methods 定义 version 友好
最近项目组里想做一个ETL数据抽取工具,这是一个研发项目,但是感觉公司并不是特别重视,不重视不是代表它不重要,而是可能不会对这个项目要求太高,能满足我们公司的小需求就行,想从这个项目里衍生出更多的东西估计难。昨天领导让我写写自己的见解,今天写了点,不过说见解还真不敢,所以取了个名字叫建议了,今天把这个文档贴到自己博客里和大伙分享分享。
贴文档之前,我想很多朋友估计并不熟悉ETL,如果接粗过数据挖掘一定对ETL很熟悉了,ETL是数据挖掘里非常重要的一环,具体什么是ETL,大家看下面这段文字:
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)作为BI/DW(Business Intelligence)的核心和灵魂,能够按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。如果说数据仓库的模型设计是一座大厦的设计蓝图,数据是砖瓦的话,那么ETL就是建设大厦的过程。在整个项目中最难部分是用户需求分析和模型设计,而ETL规则设计和实施则是工作量最大的,约占整个项目的60%~80%,这是国内外从众多实践中得到的普遍共识。
ETL是数据抽取(EXTRACT)、转换(TRANSFORM)、清洗(CLEANSING)、装载(LOAD)的过程。是构建 数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
我们所要做的ETL工具不是针对数据仓库,说白了就是要个安全稳定的数据库数据导出导入工具。下面就是我写的文档,希望童鞋们看了后请多多指教。
如图1-1:
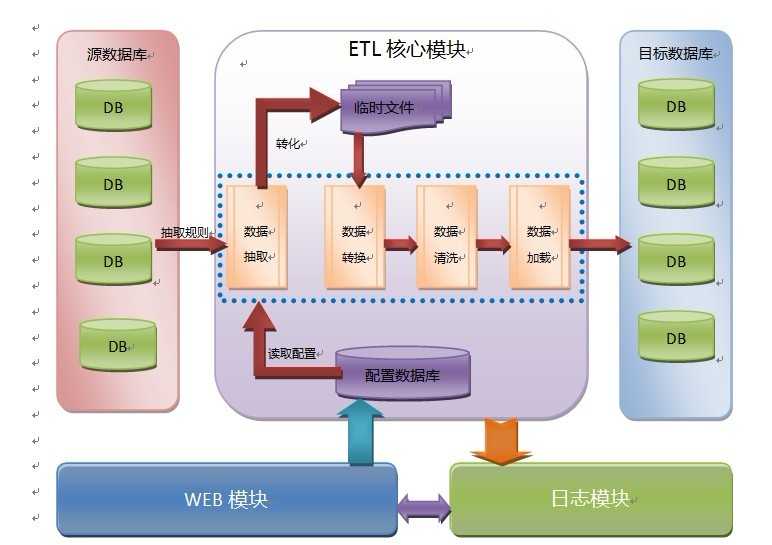
ETL工具共分为三大模块:ETL核心模块、日志模块和WEB模块。
ETL核心模块是整个ETL工具的核心,它主要的功能是根据事先定义好的规则将源数据库的数据抽取到目标数据库。其主要工作流程是:
数据抽取-->数据转换-->数据清洗-->数据加载
ETL工具里的配置数据库必须包含两个方面的数据:
良好的系统最重要的特征之一就是它的差错、容错以及能正确提供系统运行信息的特性。所以日志模块是每个系统必不可少的部分,它设计的优劣直接关系到系统后期维护的成本。
ETL工具里的日志模块,我个人认为应该包含如下的部分:
当我们开发好了ETL工具后我们需要一个入口,告诉我们设计的ETL工具你具体做什么样的任务。WEB模块的作用就是给用户操作的入口,我个人认为WEB模块包含以下功能:
整个WEB模块也是可选的,如果人力和时间不够是没必要做一个web系统,ETL入口我们可以手动的配置任务信息。(假如真的做了WEB模块,对ETL后台的设计和开发要求也会更高)。
我之前看过大家写的ETL需求文档,大家考虑的非常全面,这里我暂时有两个技术建议, 建议如下:
Xml技术在企业级系统开发和互联网开发中使用十分广泛,xml使用的场景也是非常的多,其中一个特点非常适合我们在ETL工具开发中使用到,那就是它可以存储复杂的富有变化的数据结构。而我们定义ETL任务信息(job配置信息)就是一个复杂的富有变化的数据。大家看下面的例子:

<?xml version="1.0" encoding="UTF-8"?>
<Job>
<Id>流水号</Id>
<Extract>
<JDBCSource>
<Url>…</Url>
<Username>…</UserName>
<Password>…</Password>
</JDBCSource>
<JDNISource>…</JNDISource>
<Table>…</Table>
<Columns>
<Column>…</Column>
<Column>…</Column>
…
</Columns>
<Where>…</Where>
<Commit>…</Commit>
<OrderBy>…</OrderBy>
<FilePath></FilePath>
</Extract>
<Transform>
<Columns>
<Column>
<SrcColumn> <!-- 抽取的原字段-->
</SrcColumn>
<Methods>
<Method id="1"> <!-- 第一次转换-->
<Function>...</Function>
</Method>
<Method id="2"> <!-- 第二次转换-->
<Function>...</Function>
</Method>
</Methods>
<DesColumn> <!-- 加载的目标字段-->
</DesColumn>
</Column>
<Column>...</Column>
</Columns>
<SouceFilePath>...</SourceFilePath>
<TargetFilePath>...</TargetFilePath>
<Commit>...</Commit> <!--每一批次的处理条数 -->
</Transform> <Load> <JDBCSource> <Url>…</Url> <Username>…</UserName> <Password>…</Password> </JDBCSource> <JDNISource>…</JNDISource> <Table>…</Table> <Columns> <Column>…</Column> <Column>…</Column> … </Columns> <Commit>…</Commit> <LoadFilePath></LoadFilePath> </Load></Job>
这是一个job配置信息demo,如果我们把这些数据用数据库来存储解析起来一定是非常复杂,数据库的表结构不适合表现出程序里复杂的数据结构。
在这里我们不应该把XML当做配置文件看待,而是当做一种数据存储的介质,其作用主要是便于我们读写数据。
既然对xml有读写操作,因此使用digester解析xml的技术远远不够,这里我建议使用xmlbeans,xmlbeans对于读写xml更加的简便,关于xmlbeans的学习参考如下:
Xmlbeans的使用:
http://blog.163.com/pqg_iloveyou/blog/static/33351875200761811255619/
xsd的学习资料:
http://www.w3school.com.cn/schema/schema_example.asp
xmlbeans官网:
xsd在eclipse开发起来十分的简便。
使用xmlbeans维护xml的成本也会比较低。
对于spring batch技术我现在还不是特别熟悉,到底能不能被我们使用还需要考察和研究,但现在我知道的它的几个特点很符合我们ETL工具开发的场景:
因为本人以前做过和ETL工具类似的项目,因此这里大胆的提出一点自己的建议,仅供参考。
不过我在概述里画的系统结构图希望大家可以好好看看,也许还有很多不合理的地方,这需要大家集体智慧进行改进,我个人觉得系统的整体架构设计十分重要,我在看需求分析时候虽然感觉大家写的很全面,但是很难对系统整体结构有一个清晰认识,究其原因是需求里缺乏对系统的整体架构设计的部分,我个人觉得系统整体设计很重要很有必要,整体架构设计会给我们带来很多好处:
标签:代码 文档 table 资料 部分 methods 定义 version 友好
原文地址:https://www.cnblogs.com/seamplezeus/p/9012749.html