标签:高可用架构

众所周知,服务层主要用来处理网站业务逻辑的,是大型业务网站的核心。比如下面三个业务系统就是典型的服务层,提供基础服务功能的聚合

业务发展初期主要以业务为导向,一般采用 「ALL IN ONE」的架构方式来开发产品,这个阶段用一句话概括就是 「糙猛快」。当发展起来之后就会遇到下面这些问题
遇到这些问题,主要还是通过「拆」来解决

具体拆的方式,主要根据业务领域划分单元,进行垂直拆分。拆分开来的好处很明显,主要有以下这些:
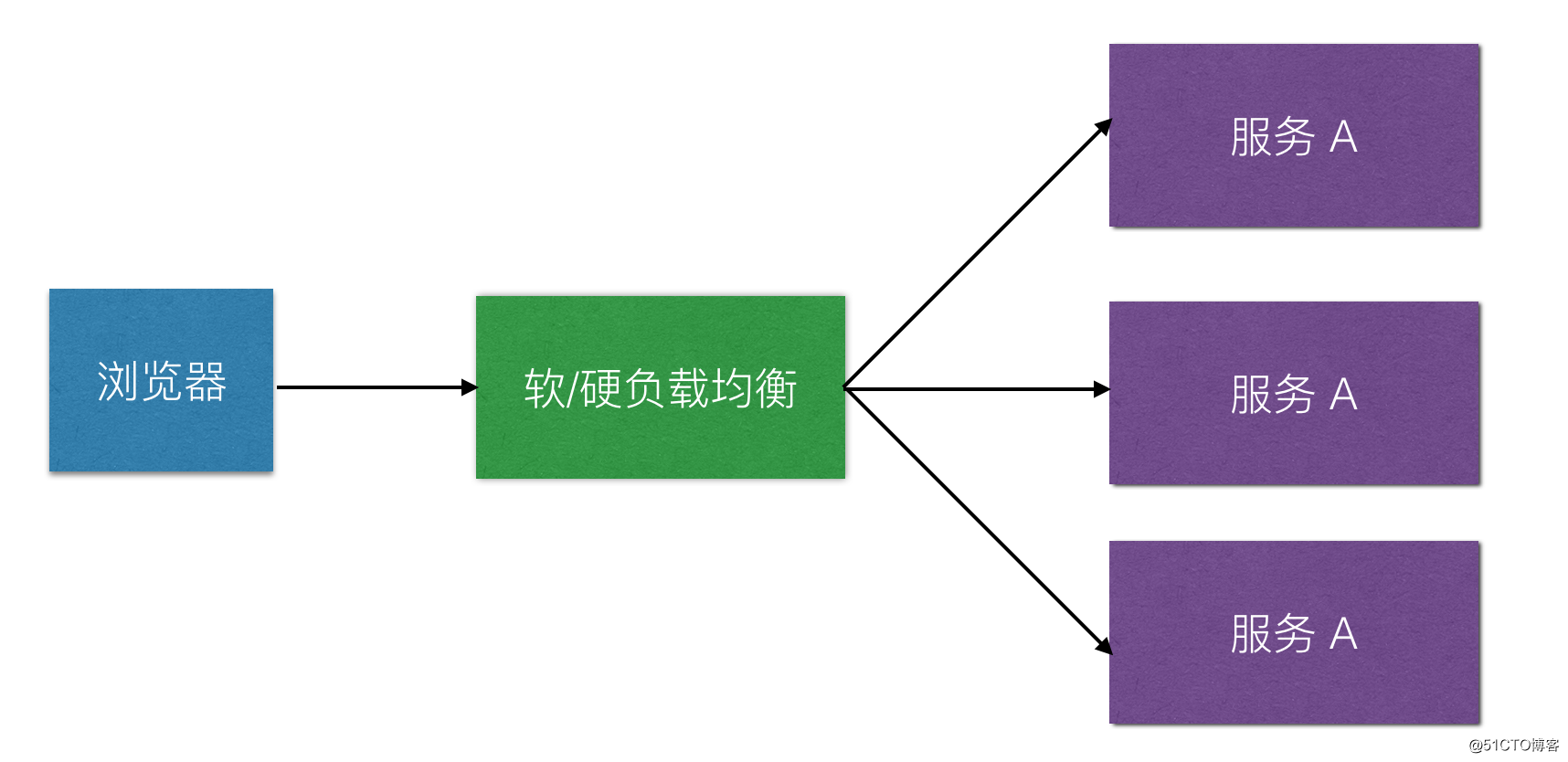
对于业务逻辑服务层,一般会设计成无状态化的服务,无状态化也就是服务模块只处理业务逻辑,而无需关心业务请求的上下文信息。所以无状态化的服务器之间是相互平等且独立的。
只有服务变为无状态的时候,故障转移才会变的很轻松。通常故障转移就是在某一个应用服务器不能服务用户请求的时候,通过负责均衡的方式,转移用户请求到其他应用服务器上来进行业务逻辑处理
一般网站服务都会有主调服务和被调服务之分。超时设置就是主调服务在调用被调服务的时候,设置一个超时等待时间 Timeout。主调服务发现超时后,就进入超时处理流程。

超时设置的好处在于当某个服务不可用时,不至于整个系统发生雪崩反应。
一般请求调用分为同步与异步两种。同步请求就像打电话,需要实时响应,而异步请求就像发送邮件一样,不需要马上回复。
这两种调用各有优劣,主要看面对哪种业务场景。比如在面对并发性能要求比较高的场景,异步调用就比同步调用有比较大的优势,这就好比一个人不能同时打多个电话,但是可以发送很多邮件。
那我们什么时候该采用异步调用?
其实主要看业务场景,如果业务允许延迟处理,那就采用异步的方式处理
那我们该怎么实现异步调用呢?
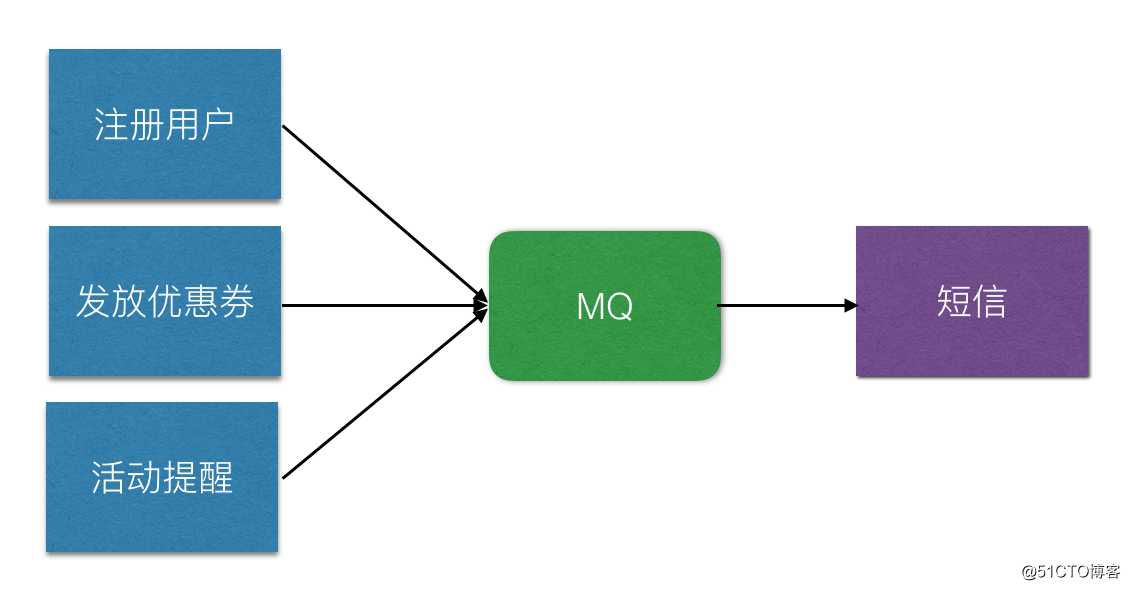
通常采用队列的方式来实现业务上的延迟处理,比如像订单中心调用配送中心,这种场景下面,业务是能接受延迟处理的。
那消息队列主要有哪些功能呢?
那到底有多少种队列呢?其实主要看处理业务的范围大小
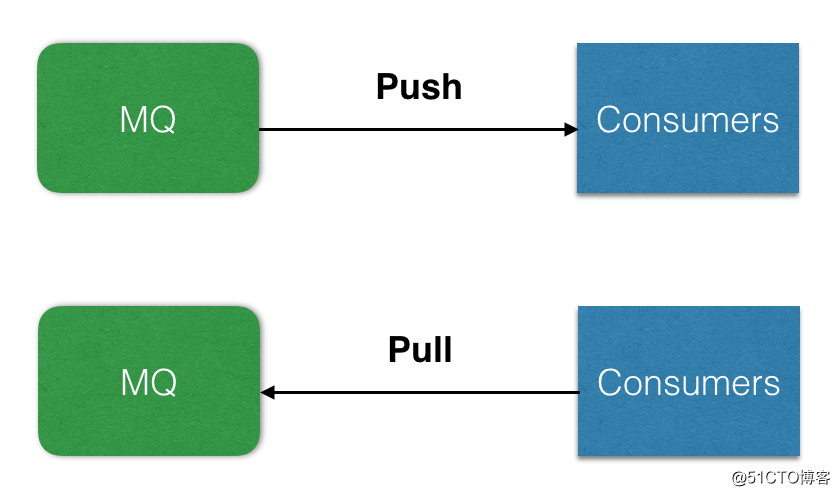
同时,技术上来讲,消息队列一般分为两种模型:Pull VS Push
其中 Pull 模式可以控制消费速度,不必担心自己处理不了消息,只需要维护队列中偏移量 Offset。所以对于消费量有限并且推送到队列的生产者不均匀的情况下,采用 Pull 模式比较合适。
Push 比较适合实时性要求比较高的情况,只要生产者消息发送到消息队列中,队列就会主动 Push 消息到消费者,不过这种模式对消费者的能力要求就提高很多,如果出现队列给消费者推送一些不能处理的消息,消费者出现 Exception 情况下,就会再次入队列,造成消费堵塞的情况。
不过互联网业界比较成熟的队列主要以采用 Pull 模式为主,像 Kafka、RabbitMQ(两种方式都支持)、RocketMQ 等
什么是幂等设计呢?
其实很简单,就是一次请求和多个请求的作用是一样的。用数学上的术语,即是 f(x) = f(f(x))。
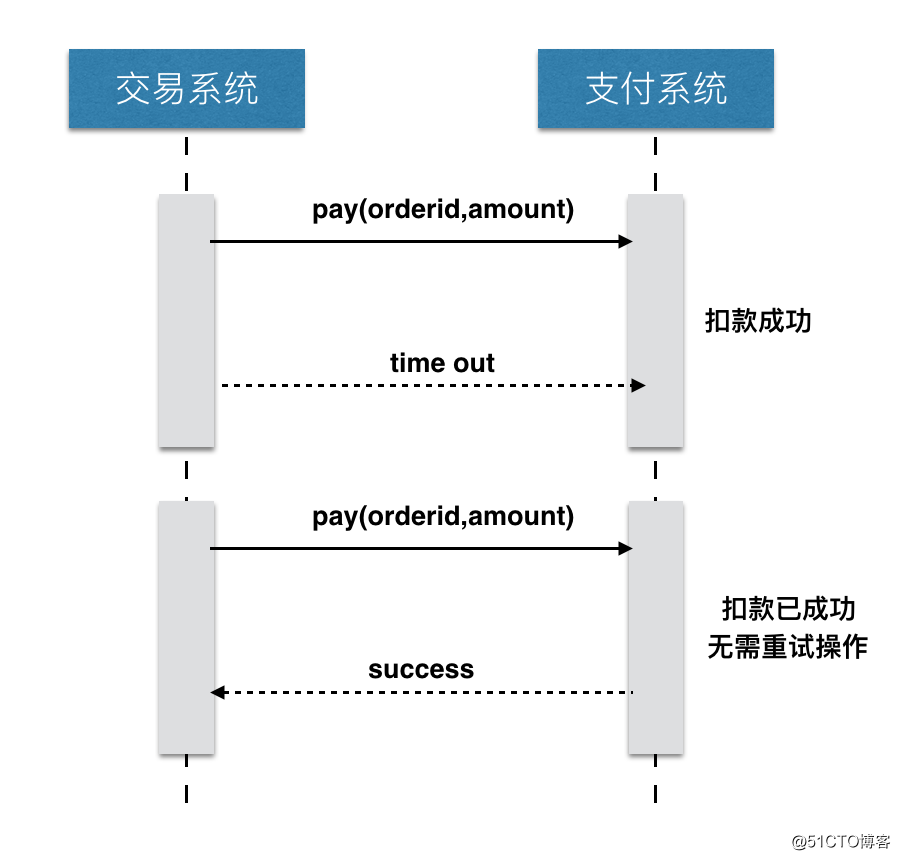
那我们为什么要做幂等性的设计呢?主要是因为现在的系统都是采用分布式的方式设计系统,在分布式系统中调用一般分为 3 个状态:成功、失败、超时。
如果调用是成功或者失败都不要紧,因为状态是明确和清晰,但是如果出现超时的情况,就不知道请求是成功还是失败的。

如果出现这种情况,我们该怎么办呢?一般采取重试的操作,重新请求对应接口。如果请求接口是 Get 操作的话,那到还好,因为请求多次的效果是一样的。但是如果是 Post 、Put 操作的话,就会造成数据不一致,甚至数据覆盖等问题。
举个例子:在支付收银台页面进行支付的时候,因为网络超时的问题导致支付失败,这个时候我们都会再进行一次支付操作,但是当支付成功后,发现你的账户余额被减了 2 次,这个时候心里肯定很不爽,心里都要开始骂娘了...
造成这个问题的关键是:网络超时后,不知道支付是什么状态?成功还是失败呢?所以说幂等性设计是必须的,尤其在电商、金融、银行等对数据要求比较高的行业中。
一般在这种场景下我们该怎么解决呢?
服务降级主要解决资源不足和访问量过大的问题,比如电商平台在双十一、618 等高峰时候采用部分服务不提供访问,减少对系统的影响。
那降级的方式有哪些呢?
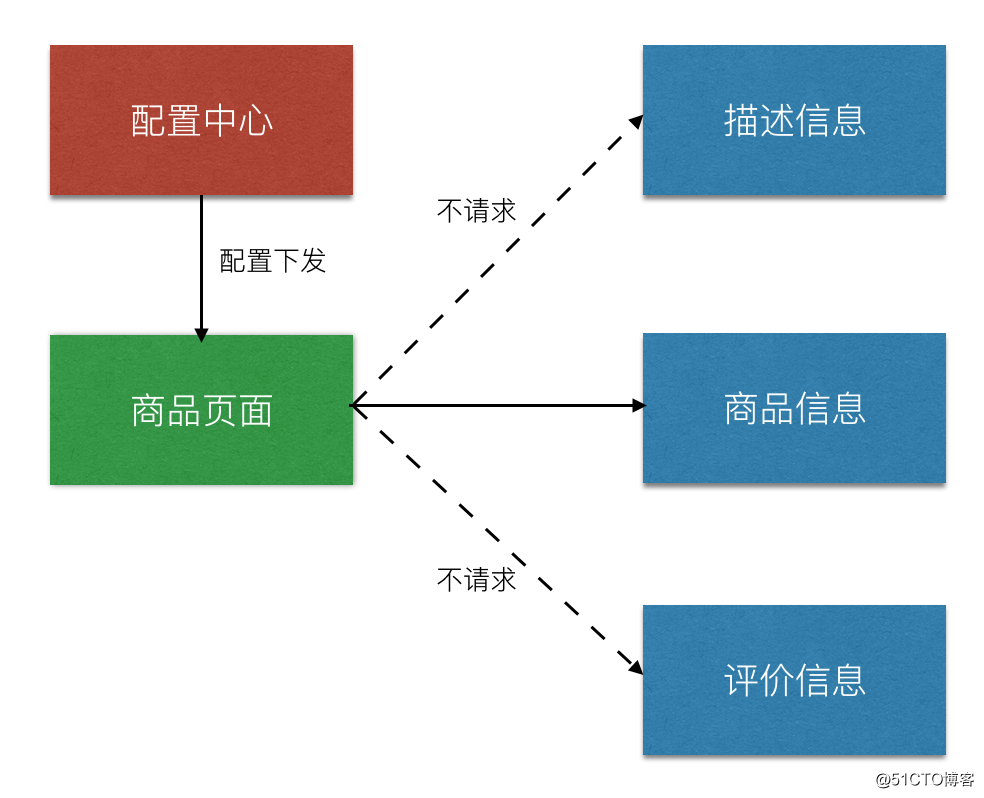
刚刚说了降级的方式,那我们操作降级的时候有哪些注意点呢?
总结一下今天分享的主要内容
下期主要讲高可用架构分布式缓存层,敬请期待。
标签:高可用架构
原文地址:http://blog.51cto.com/13527416/2114544