标签:src 部分 import 抓取 台电脑 lxml urllib 分组 数据库
爬虫:按照一定的规则,自动抓取互联网信息的程序或者脚本,从而获取对于我们有价值的信息。
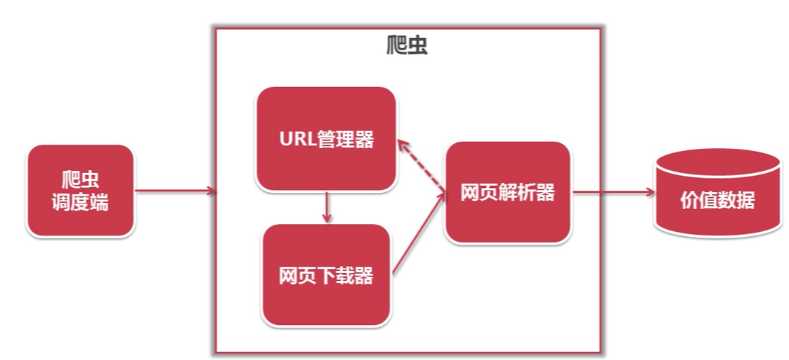
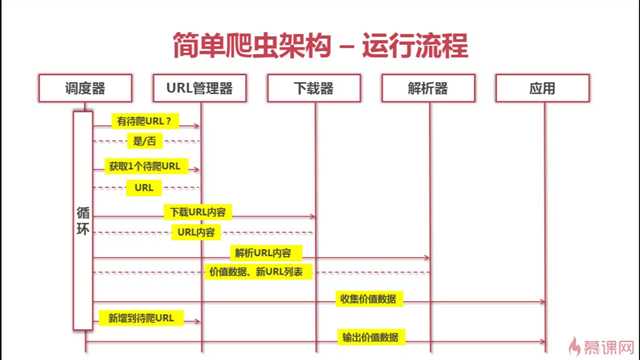
Python爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
Py2.x:
Urllib库Urllin2库Py3.x:
Urllib库变化:
import urllib2——-对应的,在Python3.x中会使用import urllib.request,urllib.error。import urllib——-对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse。import urlparse——-对应的,在Python3.x中会使用import urllib.parse。import urlopen——-对应的,在Python3.x中会使用import urllib.request.urlopen。import urlencode——-对应的,在Python3.x中会使用import urllib.parse.urlencode。import urllib.quote——-对应的,在Python3.x中会使用import urllib.request.quote。cookielib.CookieJar——-对应的,在Python3.x中会使用http.CookieJar。urllib2.Request——-对应的,在Python3.x中会使用urllib.request.Request。标签:src 部分 import 抓取 台电脑 lxml urllib 分组 数据库
原文地址:https://www.cnblogs.com/fu-yong/p/9016749.html