标签:dap 技术 log 最好 location bsp 原因 思想 方式
整理自:
https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1
1.思想
GAN结合了生成模型和判别模型,相当于矛与盾的撞击。生成模型负责生成最好的数据骗过判别模型,而判别模型负责识别出哪些是真的哪些是生成模型生成的。但是这些只是在了解了GAN之后才体会到的,但是为什么这样会有效呢?
假设我们有分布Pdata(x),我们希望能建立一个生成模型来模拟真实的数据分布,假设生成模型为Pg(x;θ),我们的目的是求解θθ的值,通常我们都是用最大似然估计。但是现在的问题是由于我们相用NN来模拟Pdata(x),但是我们很难求解似然函数,因为我们没办法写出生成模型的具体表达形式,于是才有了GAN,也就是用判别模型来代替求解最大似然的过程。
在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
2.表达式
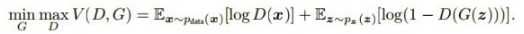
3.实际计算方法
因为我们不可能有Pdata(x)的分布,所以我们实际中都是用采样的方式来计算差异(也就是积分变求和)。具体实现过程如下:

有几个关键点:判别方程训练K次,而生成模型只需要每次迭代训练一次,先最大化(梯度上升)再最小化(梯度下降)。
但是实际计算时V的后面一项在D(x)很小的情况下由于log函数的原因会导致更新很慢,所以实际中通常将后一项的log(1-D(x))变为-logD(x)。
实际计算的时候还发现不论生成器设计的多好,判别器总是能判断出真假,也就是loss几乎都是0,这可能是因为抽样造成的,生成数据与真实数据的交集过小,无论生成模型多好,判别模型也能分辨出来。解决方法有两个:1、用WGAN 2、引入随时间减少的噪声
4.改进
对GAN有一些改进有引入f-divergence,取代Jensen-Shannon divergence,还有很多,这里主要介绍WGAN
5.WGAN
上面说过了用f-divergence来衡量两个分布的差异,而WGAN的思路是使用Earth Mover distance (挖掘机距离 Wasserstein distance)。
标签:dap 技术 log 最好 location bsp 原因 思想 方式
原文地址:https://www.cnblogs.com/helloworld0604/p/9019147.html