标签:写法 dir tuple 排序算法 考题 default == 符号 listdir
2018-05-06
1.讲在课前
# 作业:
# 重要
# 讲解视频
2.复习和今日内容
# 装饰器的进阶
# 给装饰器加上一个开关 — 从外部传了一个参数到装饰器内(从装饰器外通过一个变脸来控制装饰器的使用)
# 多个装饰器装饰同一个函数(既想记录时间,又想打日志) — 套娃
# 每个装饰器都完成一个独立的功能
# 功能与功能之间互相分离
# 同一个函数需要两个或以上额外的功能
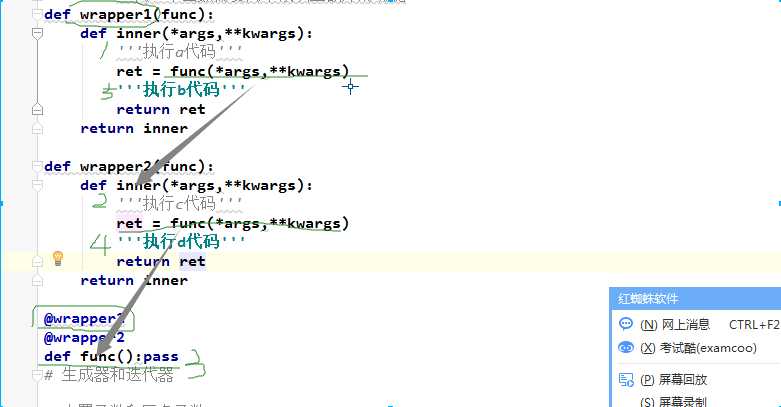
def wrapper1(func):
def inner(*args,**kwargs):
‘‘‘执行a代码‘‘‘
ret = func(*args,**kwargs) # 被装饰的函数:装饰器wrapper2的inner()函数
‘‘‘执行b代码‘‘‘
return ret
return inner
def wrapper2(func):
def inner(*args,**kwargs):
‘‘‘执行c代码‘‘‘
ret = func(*args,**kwargs) # 被装饰的函数
‘‘‘执行d代码‘‘‘
return ret
return inner
@wrapper1
@wrapper2 # 离被装饰函数func最近的装饰器,时间计算
def func():pass
# 执行顺序:
‘‘‘执行a代码‘‘‘
‘‘‘执行c代码‘‘‘
func()
‘‘‘执行b代码‘‘‘
‘‘‘执行d代码‘‘‘
# timmer login
# timmer logger
# 生成器和迭代器
# 迭代器 : iter next
# 可以被for循环 本质上为节省内存空间
# 它没有所谓的索引取值的概念 不能只取某一个值 只能连续的取当前的值和下一个值
# 生成器:
# 生成器和迭代器本质上是一样的 生成器是开发者自己写的
# yield 函数
# 执行生成器函数 不会执行这个函数中的代码,只会得到一个生成器
# 有几个yield,就能从中取出多少个指
# def fff():
# for i in range(10):
# yield i
# 生成器表达式
# 生成器表达式也会返回一个生成器 也不会直接被执行
# for循环里有几个符合条件的值,生成器就返回多少值
#!!! 每一个生成器都会从头开始取值,当取到最后的时候,生成器中就没有值了
#!!! 一个生成器只能用一次
def fff():
for i in range(10):
yield i
g2 = (i**i for i in range(20)) # for循环里有几个符合条件的值,生成器就返回多少值
g = fff()
# li = list(g)
# print(li)
print(next(g))
print(next(g))
print(next(g))
print(next(fff()))
print(next(fff()))
print(next(fff()))
for i in fff():
print(i)
# 如果现在明白 可以车热打铁 先巩固一下
# 如果不明白 先放一放
# 框架和项目 作业
# 毕业时
# 内置函数和匿名函数
# map filter sorted max min zip
def func(n):
if n%2 == 0:
return True
# 以下三种写法相同
ret = filter(func,range(20))
# ret = filter(lambda n: True if n%2 == 0 else False,range(20))
# ret = filter(lambda n: n%2 == 0,range(20))
print(list(ret))
lst = [1,4,6,7,9,12,17]
def func(num):
if num % 2 == 0:return True
for i in filter(func,lst):
print(i)
ret1 = filter(func,lst)
print(list(ret1))
2.递归
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 递归 —— 在函数的内部调用自己
# 不断向函数内部走(递),遇到返回后一步一步返回(归)
# 递归的最大深度:998
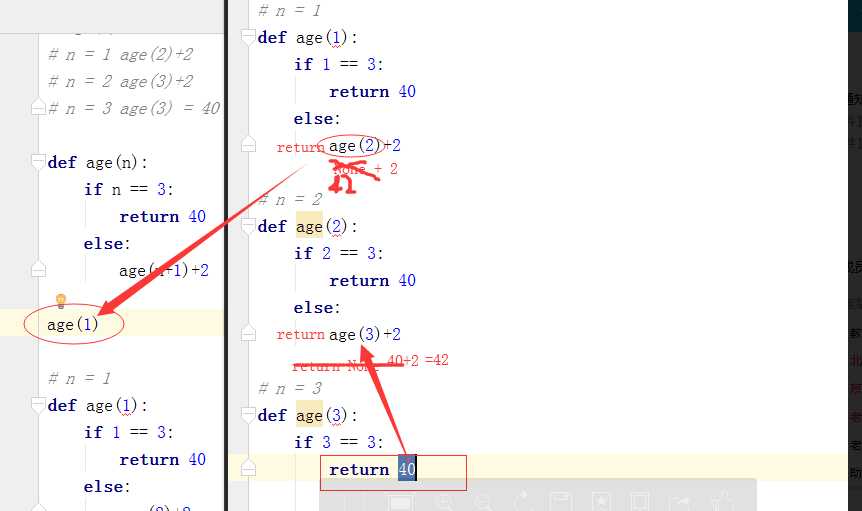
# 小例子:(猜年龄)
# alex多大了 alex比wusir大两岁 40+2+2
# wusir多大了 wusir比金老板大两岁 40+2
# 金老板多大了 40了
# 推理
# age(1)
# n = 1 age(2)+2
# n = 2 age(3)+2
# n = 3 age(3) 40
def age(n):
if n ==3:
return 40
else:
return age(n+1)+2
print(age(1))
# 算法 计算一些比较复杂的问题
# 所采用的 在空间上(内存里) 或者时间上(执行时间) 更有优势的算法
# 排序算法 500w个数排序 快速排序 堆排序 冒泡排序
# 查找算法
# 递归求解二分查找算法:只能处理有序的数字集合的查找问题

l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
def cal(l,num=66):
length = len(l) # 拿到长度
mid = length//2
if num > l[mid]:
l = l[mid+1:]
cal(l,66)
elif num < l[mid]:
l = l[:mid]
cal(l, 66)
else:
print(‘找到了‘,l[mid],mid)
cal(l,66)
# 找到了 66 0
# 问题:索引位返回0,不符合预期
# 进阶
# 列表不能变,所因为返回正常
# 算法
def cal(l,num,start=0,end=None):
# if end is None:end = len(1)-1
end = len(l)-1 if end is None else end
if start <= end:
mid = (end -start)//2 +start
if l[mid] > num:
return cal(l,num,start,mid-1)
elif l[mid] < num:
return cal(l,num,mid+1,end)
else:
return mid
else:
return None
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
print(cal(l,56))

4.模块
# 模块
# 模块是写好了但不直接使用的功能
# 常用的和某个操作相关的 根据相关性分类 分成不同的模块
# 模块分为三种: 内置模块 扩展模块 自定义模块
# 内置模块 只要安装了python解释器同时一起安装了
# 扩展模块 django... http://Pypi.org
‘‘‘常用模块:
collections模块
time时间模块
random模块
os模块
sys模块
序列化模块
re模块‘‘‘
# collections模块
‘‘‘
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数【略】
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
‘‘‘
# 4.OrderedDict: 有序字典
# 5.defaultdict: 带有默认值的字典
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
# 默认这个字典的value是一个空列表,当k1、k2键值不存在时,首次赋值时不会报错
for value in values:
if value>66:
my_dict[‘k1‘].append(value)
else:
my_dict[‘k2‘].append(value)
print(my_dict)
# 1.namedtuple: 生成可以使用名字来访问元素内容的tuple
from collections import namedtuple
Point = namedtuple(‘Point‘,[‘x‘,‘y‘])
p = Point(1,2)
print(p.x)
print(p.y)
Card = namedtuple(‘card‘,[‘rank‘,‘suit‘])
c = Card(‘红心‘,‘2‘)
print(c.rank,c.suit)
print(Card)

# 2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
from collections import deque
q = deque()
q.append(1)
q.append(2)
q.append(3)
q.append(3)
print(q)
print(q.pop())
print(q)
q.appendleft(‘a‘)
q.appendleft(‘b‘)
q.appendleft(‘c‘)
print(q)
q.popleft()
print(q)
# time时间模块
import time
# 时间戳时间
print(time.time()) # 时间戳时间 英国伦敦时间 1970年1月1日0点0分0秒距今的时间
print(time.time()) # 时间戳时间 北京时间(东8区) 1970 1 1 8 0 0
# 格式化时间 用字符串表示的时间
print(time.strftime(‘%H:%M:%S‘)) # 时分秒
print(time.strftime(‘%Y-%m-%d‘)) # 年月日
print(time.strftime(‘%x‘)) # 05/06/18
print(time.strftime(‘%c‘)) # Sun May 6 15:35:17 2018
# 结构化时间 机器时间与人类时间的桥梁 (时间戳 — 结构化时间 — 格式化时间)
t = time.localtime()
print(t)
t = time.localtime()
print(t.tm_year)
print(t.tm_mday)
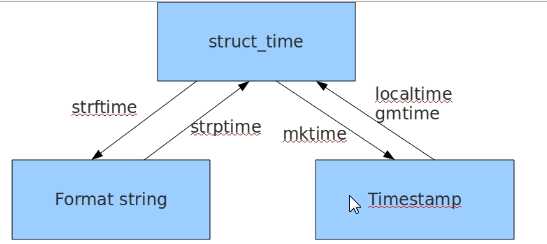
import time
print(time.time())
print(time.localtime(1500000000))
print(time.localtime(1600000000))
print(time.localtime(2000000000))
struct_time = time.gmtime(2000000000)
print(time.strftime(‘%Y-%m-%d %H:%M:%S‘))
print(time.strftime(‘%Y-%m-%d %H:%M:%S‘),struct_time)
# ‘2015-12-3 8:30:20‘ 时间戳时间
s = ‘2015-12-3 8:30:20‘
ret = time.strptime(s,‘%Y-%m-%d %H:%M:%S‘)
print(ret)
print(time.mktime(ret))
# 思考题
# 1.拿到当前时间的月初1号的0点的时间戳时间
# 2.计算任意两个时间点之间经过了多少年月日时分秒
# import time
# true_time=time.mktime(time.strptime(‘2017-09-11 08:30:00‘,‘%Y-%m-%d %H:%M:%S‘))
# time_now=time.mktime(time.strptime(‘2017-09-12 11:00:00‘,‘%Y-%m-%d %H:%M:%S‘))
# dif_time=time_now-true_time
# struct_time=time.gmtime(dif_time)
# print(‘过去了%d年%d月%d天%d小时%d分钟%d秒‘%(struct_time.tm_year-1970,struct_time.tm_mon-1,
# struct_time.tm_mday-1,struct_time.tm_hour,
# struct_time.tm_min,struct_time.tm_sec))
# random模块
import random
# 4位随机验证码
s = ‘‘
for i in range(4):
s += str(random.randint(0,9))
print(s)
# 随机数字+字母
print(chr(98))
import random
num = random.randint(56,90)
# 某一位置 到底是一个字母还是一个数字的事儿也是随机的
import random
s = ‘‘
for i in range(6):
num = random.randint(65,90)
alpha1 = chr(num)
num2 = random.randint(97,122)
alpha2 = chr(num2)
num3 = str(random.randint(0,9))
print(alpha1,alpha2,num3)
s += random.choice([alpha1,alpha2,num3])
print(s)
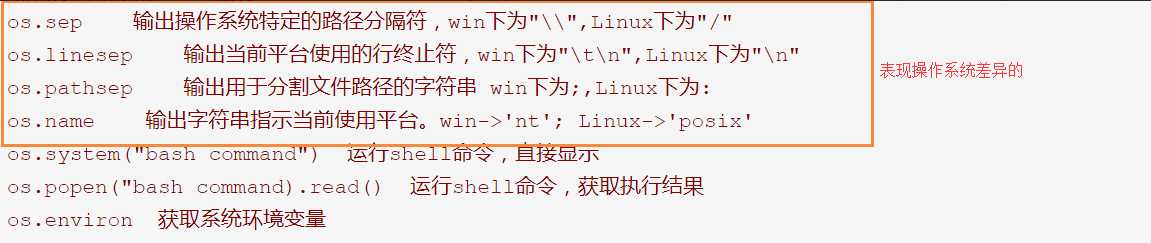
# os模块
import os
# 创建删除文件夹
os.makedirs(‘dirname1/dirname2/dirname3‘) # 递归创建文件夹
os.removedirs(‘dirname‘) # 递归删除文件夹,直到删除到非空目录
os.mkdir(‘dirname‘) # 创建单级文件夹
os.rmdir(‘dirname‘) # 删除单级文件夹,非空则不能删除
os.listdir() # ls 返回值为列表
os.path.join() # 路径拼接
os.path.getsize() # 获取文件夹大小 始终是4096
ret = os.listdir(r‘D:\eva‘)
print(ret)
sum = 0
for path in ret:
sum += os.path.getsize(path)
print(sum)


# sys模块
import sys
# sys.path 一个模块是否能够被导入 全看在不在sys.path列表包含的路径下
print(sys.path)
# sys.argv 脚本执行 在执行python脚本的时候,可以传递一些参数进来
print(sys.argv)
# if sys.argv[1] == ‘alex‘ and sys.argv[2] == ‘alex3714‘:
# print(‘可以执行代码‘)
# else:
# sys.exit()
# sys.modules 放了所有在解释器运行的过程中导入的模块名
print(sys.modules)
# sys.exit() 解释器退出 = 程序结束
5.正则表达式
# http://www.cnblogs.com/Eva-J/articles/7228075.html#_label10
# 正则表达式 字符串匹配相关的操作的时候 用到的一种规则
# 正则表达式的规则
# 使用python中的re模块取操作正则表达式
# http://tool.chinaz.com/regex/
# 字符组:[字符组] 一个字符组只代表一个字符
# [0-9a-fA-F] 可以匹配数字,大小写形式的a~f,用来验证十六进制字符
# 元字符 对一个字符的匹配创建的一些规则
# 这些规则是在正则表达式中有着特殊意义的符号
# 如果要匹配的字符刚好是和元字符一模一样 那么需要对这个元字符进行转义
# 量词 量词跟在一个元字符的后面 约束某个字符的规则能够重复多少次
# 默认贪婪匹配会在当前量词的约束范围,匹配最多的次数
‘‘‘
匹配内容
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线 与\W互斥
\s 匹配任意的空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
\b 匹配一个单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线 与\w互斥
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b 把较长子串放在左边 ABCD|ABC
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[ ^...] 匹配除了字符组中字符的所有字符 [^ABC]除了ABC之外的字符都能匹配到
‘‘‘
‘‘‘
量词:
用法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次 1[3-9][0-9]{9} 简单过滤电话号码 紧贴要重复的
{n,} 重复n次或更多次
{n,m} 重复n到m次
‘‘‘
# 贪婪匹配
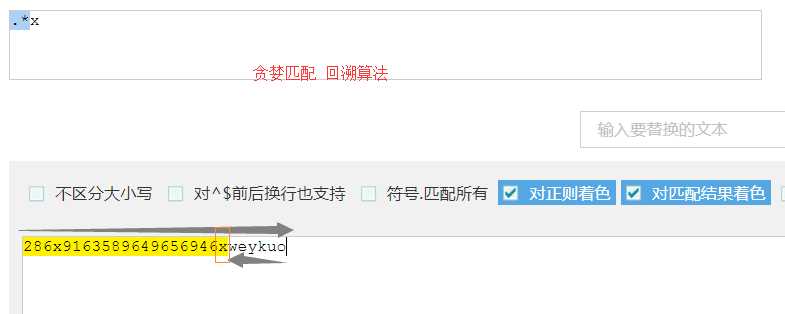
# 非贪婪匹配 惰性匹配
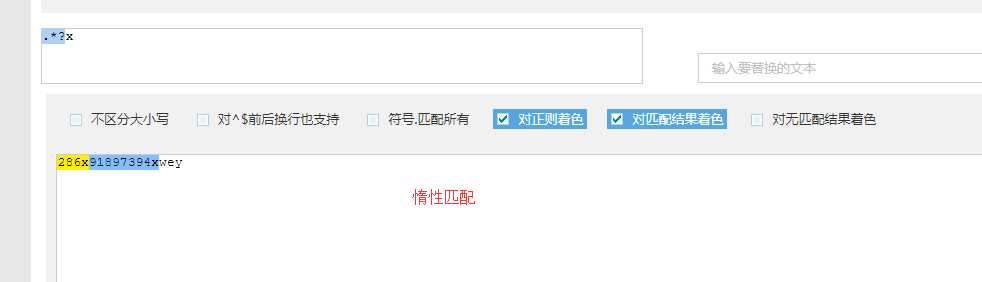
# \d+\.?\d* 匹配
import re
# findall 找所有
ret = re.findall(‘\d+‘,‘eva1236 e12gon y1280uan‘)
print(ret)
ret = re.search(‘\d+‘,‘eva1236 e12gon y1280uan‘)
print(ret) #返回地址
print(ret.group())
# search 值匹配第一个
# 返回的值不是一个直接的结果 而是一个内存地址
ret = re.search(‘----‘,‘eva1236 e12gon y1280uan‘)
if ret:print(ret.group())
# 预编译节省时间
obj = re.compile(‘\d{3}‘) #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search(‘abc123eeee‘) #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
# 节省空间
ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
# findall的优先级查询
ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘)
print(ret) # [‘oldboy‘] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘)
print(ret) # [‘www.oldboy.com‘]
#split的优先级查询
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘egon‘, ‘yuan‘]
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘]
# 在匹配部分加上()之后所切出的结果是不同的,
# 没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
# 这个在某些需要保留匹配部分的使用过程是非常重要的。
#######
# 作业 计算器
express = ‘1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )‘
# 2776672.6952380957
# 先算小括号里的
# 再先乘除后加减的计算
# 50行之内
标签:写法 dir tuple 排序算法 考题 default == 符号 listdir
原文地址:https://www.cnblogs.com/rainbow91/p/9022450.html