标签:文件 存在 节点 存储 为什么 并且 性能 中间 范围
问题一:数据库索引为什么要用树结构存储? -------- 树查询快,并且可以保持有序
问题二:为什么索引没有用二叉查找树来实现? --------数据库索引是存在磁盘上的,
B树是一种多路平衡查找树,它的每一个节点最多包含m个孩子,m称为B树的阶。m的大小取决于磁盘页的大小。
一个m阶的B树具有如下几个特征:
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
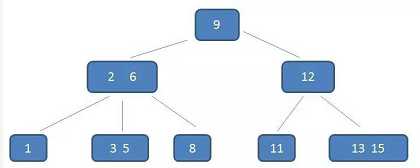
只要树的高度足够低,IO的次数足够少,查找性能就提高了。
应用:主要应用于文件系统以及部分数据库索引,比如非关系型数据库。
B+树是基于B树的,更好的查询性能。
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
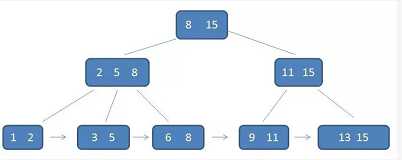
B-树中每个节点都带有卫星数据,而B+树中只有叶子结点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联。
需要补充的是,在数据库的聚集索引中,叶子节点直接包含卫星数据。在非聚集索引中,叶子节点带有指向卫星数据的指针。
对比B-树,如何提高性能:
单行查询下:
1)B+树中间节点不带卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素。也就意味着,数据量相同时,B+树更加矮胖,IO查询次数更少。
2)B+树的查询必须最终匹配到叶子结点,而B-树只要找到匹配元素即可,查询性能不稳定。
范围查找下:B+树可以通过链表指针遍历即可,查询简便。
B+树的特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
标签:文件 存在 节点 存储 为什么 并且 性能 中间 范围
原文地址:https://www.cnblogs.com/mcahkf/p/9025371.html