标签:sts color 反向 利用 简单 使用 print 匹配 key
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列 <6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <7> order_by(*field): 对查询结果排序 <8> reverse(): 对查询结果反向排序,请注意reverse()通常只能在具有已定义顺序的QuerySet上调用(在model类的Meta中指定ordering或调用order_by()方法)。 <9> distinct(): 从返回结果中剔除重复纪录(如果你查询跨越多个表,可能在计算QuerySet时得到重复的结果。此时可以使用distinct(),注意只有在PostgreSQL中支持按字段去重。) <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录 <12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的 models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 类似的还有:startswith,istartswith, endswith, iendswith date字段还可以: models.Class.objects.filter(first_day__year=2017)
语法:
对象.关联字段.字段
示例:
book_obj = models.Book.objects.first() # 第一本书对象 print(book_obj.publisher) # 得到这本书关联的出版社对象 print(book_obj.publisher.name) # 得到出版社对象的名称
语法:
关联字段__字段
示例:
# 查询id是1的书的出版社的名称 # 利用双下划线 跨表查询 # 双下划线就表示跨了一张表 # ret = models.Book.objects.filter(id=1).values_list("publisher__name") # print(ret)
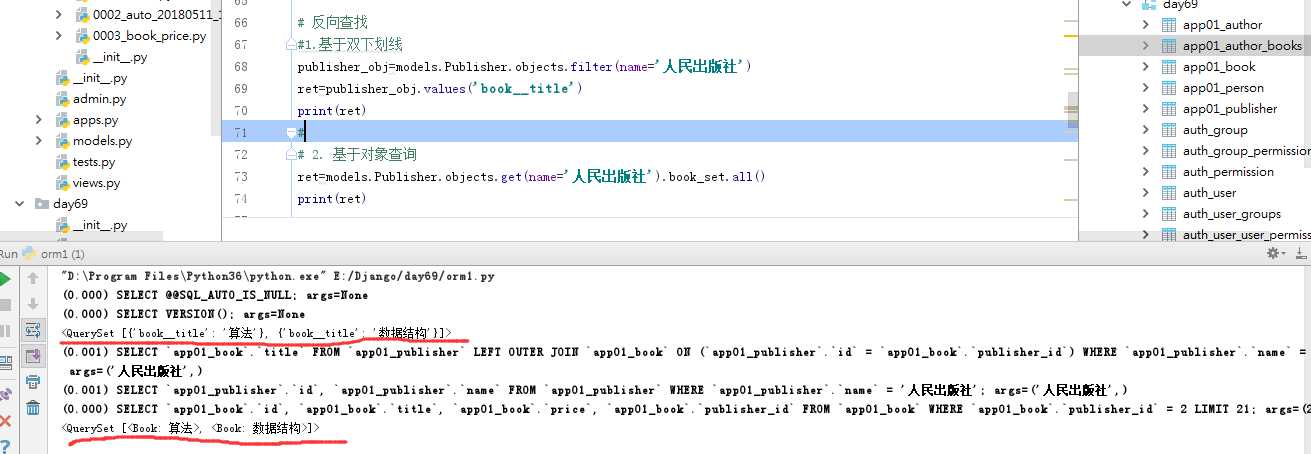
语法:
obj.表名_set
语法:
关联字段__字段
示例:
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
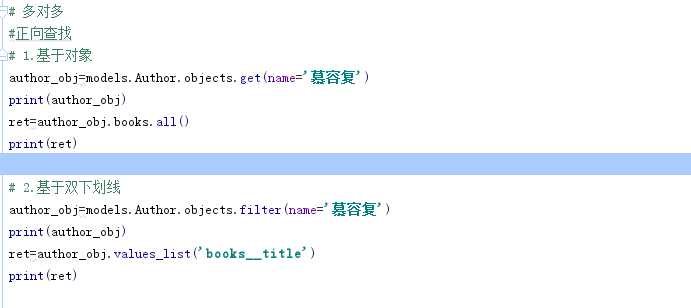

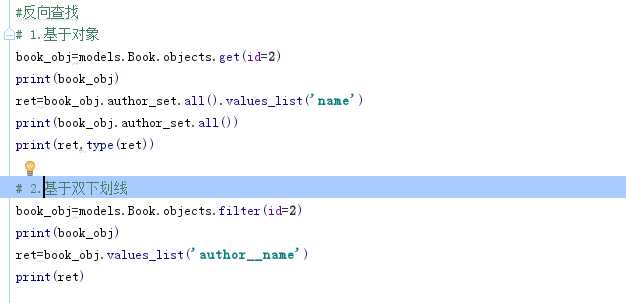
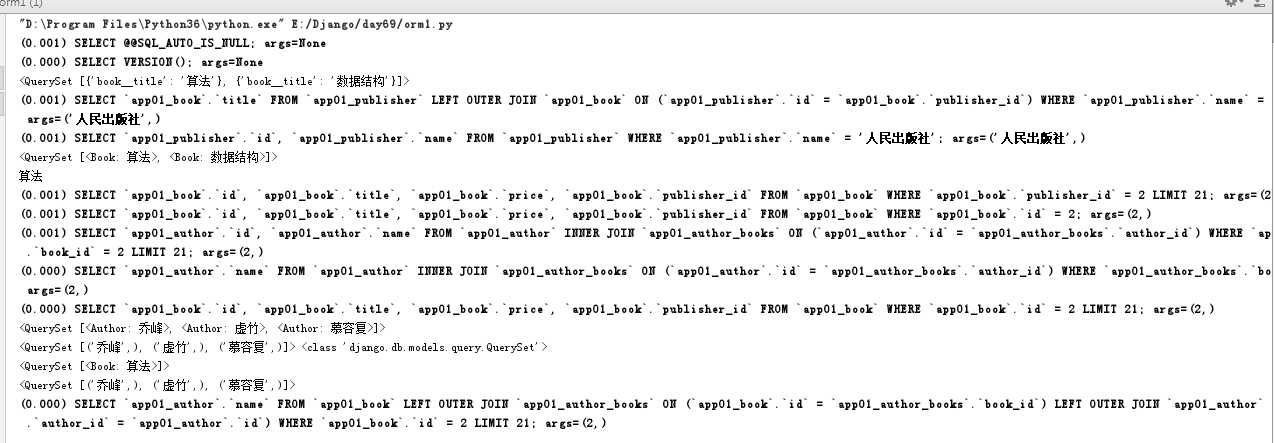
它存在于下面两种情况:
简单来说就是当 点后面的对象 可能存在多个的时候就可以使用以下的方法。
标签:sts color 反向 利用 简单 使用 print 匹配 key
原文地址:https://www.cnblogs.com/strive-man/p/9029576.html