标签:des style blog http io os 使用 ar strong
|
语法及详解参数:
官方示例:
drbd及其配置文件中的相关名词: failover:失效转移。通俗地说,即当A无法为客户服务时,系统能够自动地切换,使B能够及时地顶上继续为客户提供服务,且客户感觉不到这个为他提供服务的对象已经更换。(注:来自百度百科。)
diskless mode:无盘模式。在此模式下,节点放弃自己的底层设备,转而通过网络到远程节点上去读写数据。
peer:对等端,在两个NameNode的环境下,指另外一个NameNode
stonith:Shoot The Other Node In The Head的简写,爆其它节点的头!它是避免split brain的一个措施,若发生split brain,则一个node会发出指令让另一个node关机,避免两台node都浮动成primary。但这个功能本身也有一定的风险。
fence-peer:drbd有一个机制,当复制连接被中断时它将隔离对等节点。drbd为这个机制定义一个接口,而与heartbeat绑定的drbd-peer-outdater helper就是个通过此接口来实现此机制的工具。但是我们可以很轻松地实施我们自己的peer fencing helper程序,而实施我们自己的peer fencing程序的前提条件之一就是,必须在handlers配置段中定义fence-peer处理器!
StandAlong mode:即节点无法与其它节点进行通信的状态。
参考:http://www.drbd.org/users-guide/ch-admin.html#s-connection-states
write barriers:日志文件系统中的一种保护机制,用来保持数据的一致性。
日志文件系统在磁盘的专门区域维护着一个日志。当文件系统发觉到元数据的变化时,它将首先把这些变化写入日志,而不是立刻去更改元数据。当这些变化信息(事件信息)写入日志后,文件系统将向日志中添加一个“提交报告”来表明文元数据的更改是合法的。只有当“提交报告”写入日志后,内核才会真正对元数据进行写操作。
在写“提交报告”以前,必须完全保证事件信息已经写入了日志。仅仅如此还不够,与此同时驱动器还维护了一个巨大的内部caches,而且为了更好的性能表现,它会重新对操作进行排序,所以在写“提交报告”之前,文件系统必须明确地指导磁盘来获取所有的日志数据,并存入介质。如果“提交报告”先于事件信息写入日志,日志将被损坏!
内核的I/O子系统通过使用barriers来实现上述功能。大体来说,一个barrier生成后,它将禁止其后的所有数据块的写入,直到该barrier之前的数据块写入被提交到介质。
注意:ext3和ext4文件系统默认不使用barriers,管理员必须明确启用它们才能使用该功能。而且,并非所有文件系统都支持barrier。
meta data:DRBD在专门的区域存储关于数据的各种各样的信息,这些信息就是metadata,它包括如下信息:
1、 DRBD设备的空间大小
2、 Generation Identifier(GI)
3、 Activity Log(AL)
4、 quick-sync bitmap
这些metadata有两种存储方式:internally和externally。存储方式是在每个resource配置段中指定的。这两种存储方式各有优缺点。
Internal metadata:
一个resource被配置成使用internal metadata,意味着DRBD把它的metadata,和实际生产数据存储于相同的底层物理设备中。该存储方式是在设备的最后位置留出一个区域来存储metadata。
该存储方式的优点是:因为metadata是和实际生产数据紧密联系在一起的,如果发生了硬盘损坏,不需要管理员做额外的工作,因为metadata会随实际生产数据的丢失而丢失,同样会随着生产数据的恢复而恢复。
它的缺点在于:如果底层设备只有一块物理硬盘(和RAID相反),这种存储方式对写操作的吞吐量有负面影响,因为应用程序的写操作请求会触发DRBD的metadata的更新。如果metadata存储于硬盘的同一块盘片上,那么,写操作会导致额外的两次磁头读写移动。
要注意的是:如果你打算在已有数据的底层设备中使用internal metadata,需要计算并留出DRBD的metadata所占的空间大小,并采取一些特殊的操作,否则很有可能会破坏掉原有的数据!至于需要什么样的特殊操作,可以参考本条目末尾的链接文章。我要说的是,最好不要这样做!
external metadata:
该存储方式比较简单,就是把metadata存储于一个和生产数据分开的专门的设备块中。
它的优点:对某些写操作,提供某些潜在的改进。
缺点:因为metadata和生产数据是分开的,如果发生了硬盘损坏,在更换硬盘后,需要管理员进行人工干预,从其它存活的节点向刚替换的硬盘进行完全的数据同步。
什么时候应该使用exteranl的存储方式:设备中已经存有数据,而该设备不支持扩展(如LVM),也不支持收缩(shrinking)。
如果计算DRBD的元数据所需要的确切空间:
Cs是磁盘的扇区数,Ms也是使用扇区数来描述的,要转化成MB,除以2048即可。
扇区数可以使用公式echo $(( $(blockdev --getsize64 device) / 512))来计算。
参考:http://www.drbd.org/users-guide-emb/ch-internals.html,以及http://www.wenzizone.cn/?p=280
drbd配置文件: drbd安装完成后,会自动创建一个配置文件/etc/drbd.conf,内容为空,但你可以找到一个模板文件/usr/share/doc/drbd.../drbd.conf,该模板文件只有两个include语句。
为什么模板文件如此简洁?
drbd的配置文件分成三个部分:global、common和resource。这三部分虽然可以全部写入一个/etc/drbd.conf文件中,但是按照官方惯例,这三部分是分开的:/etc/drbd.d目录下的global_common.conf文件包含global和common配置段,而目录下的每个.res文件包含一个resource配置段。
关于global配置段:
如果所有配置段都在同一个drbd.conf文件中,则该配置必须放在最顶端。
常用选项:
minor-count:从(设备)个数,取值范围1~255,默认值为32。该选项设定了允许定义的resource个数,当要定义的resource超过了此选项的设定时,需要重新载入drbd内核模块。
dialog-refresh time:time取值0,或任一正数。默认值为1。我没理解官方对该选项的解释。很少见到此选项被启用。
disable-ip-verification:是否禁用ip检查
usage-count:是否参加用户统计,合法参数为yes、no或ask
根据官方示例的说法,一般只配置usage-count选项即可。不过,说实话,drbd的官方文档确实挺操蛋,有些地方说的比较含糊。当然,也有我水平有限的原因。
关于common配置段:
该配置段不是必须的,但可以用来设定多个resource共有的选项,以减少重复性工作。该配置段中又包含如下配置段:disk、net、startup、syncer和handlers。
disk配置段:
该配置段用来精细地调节drbd底层存储的属性。译者注:这是一个非常重要的配置段,如果底层设备(磁盘)发生了错误或损坏,该配置段将按照设定的策略发生作用。
常用选项:
on-io-error选项:此选项设定了一个策略,如果底层设备向上层设备报告发生I/O错误,将按照该策略进行处理。有效的策略包括:
pass_on:把I/O错误报告给上层设备。如果错误发生在primary节点,把它报告给文件系统,由上层设备处理这些错误(例如,它会导致文件系统以只读方式重新挂载),它可能会导致drbd停止提供服务;如果发生在secondary节点,则忽略该错误(因为secondary节点没有上层设备可以报告)。该策略曾经是默认策略,但现在已被detach所取代。
call-local-io-error:调用预定义的本地local-io-error脚本进行处理。该策略需要在resource配置段的handlers部分,预定义一个相应的local-io-error命令调用。该策略完全由管理员通过local-io-error命令(或脚本)调用来控制如何处理I/O错误。
detach:发生I/O错误的节点将放弃底层设备,以diskless mode继续工作。在diskless mode下,只要还有网络连接,drbd将从secondary node读写数据,而不需要failover。该策略会导致一定的损失,但好处也很明显,drbd服务不会中断。官方推荐和默认策略。 译者注:如果使用detach策略来处理底层I/O错误,该策略会不会报告错误给管理员,以便管理员手动更换此节点的磁盘呢? handler处理器部分应该会有这方面的内容。
fencing选项:该选项设定一个策略来避免split brain的状况。有效的策略包括:
dont-care:默认策略。不采取任何隔离措施。
resource-only:在此策略下,如果一个节点处于split brain状态,它将尝试隔离对等端的磁盘。这个操作通过调用fence-peer处理器来实现。fence-peer处理器将通过其它通信路径到达对等节点,并在这个对等节点上调用drbdadm outdate res命令。
resource-and-stonith:在此策略下,如果一个节点处于split brain状态,它将停止I/O操作,并调用fence-peer处理器。处理器通过其它通信路径到达对等节点,并在这个对等节点上调用drbdadm outdate res命令。如果无法到达对等节点,它将向对等端发送关机命令。一旦问题解决,I/O操作将重新进行。如果处理器失败,你可以使用resume-io命令来重新开始I/O操作。
net配置段:
该配置段用来精细地调节drbd的属性,网络相关的属性。常用的选项有:
sndbuf-size:该选项用来调节TCP send buffer的大小,drbd 8.2.7以前的版本,默认值为0,意味着自动调节大小;新版本的drbd的默认值为128KiB。高吞吐量的网络(例如专用的千兆网卡,或负载均衡中绑定的连接)中,增加到512K比较合适,或者可以更高,但是最好不要超过2M。
timeout:该选项设定一个时间值,单位为0.1秒。如果搭档节点没有在此时间内发来应答包,那么就认为搭档节点已经死亡,因此将断开这次TCP/IP连接。默认值为60,即6秒。该选项的值必须小于connect-int和ping-int的值。
connect-int:如果无法立即连接上远程DRBD设备,系统将断续尝试连接。该选项设定的就是两次尝试间隔时间。单位为秒,默认值为10秒。
ping-int:该选项设定一个时间值,单位为秒。如果连接到远程DRBD设备的TCP/IP的空闲时间超过此值,系统将生成一个keep-alive包来检测对等节点是否还存活。默认值为10秒。
ping-timeout:该选项设定一个时间值,单位是0.1秒。如果对等端没有在此时间内应答keep-alive包,它将被认为已经死亡。默认值是500ms。
max-buffers:该选项设定一个由drbd分配的最大请求数,单位是页面大小(PAGE_SIZE),大多数系统中,页面大小为4KB。这些buffer用来存储那些即将写入磁盘的数据。最小值为32(即128KB)。这个值大一点好。
max-epoch-size:该选项设定了两次write barriers之间最大的数据块数。如果选项的值小于10,将影响系统性能。大一点好。
用户手册的另外一部分也提到了max-buffers和max-epoch-size,跟drbd.conf部分的解释稍有不同:drbd.conf的帮助文档中说,max-buffers设定的是最大请求数,max-epoch-size设定的是最高的数据块数;而这部分的帮助文档说,这两个选项影响的是secondary节点写操作的性能,max-buffers设定的是最大的buffers数,这些buffers是drbd系统是为即将写入磁盘的数据而分配的;max-epoch-size设定的是两次write barrier之间所允许的最大请求数。
多数情况下,这两个选项应该并行地设置,而且两个选项的值应该保持一致。两个选项的默认值都是2048,在大多数合理的高性能硬件RAID控制器中,把它们设定为8000比较好。
两个部分的解释结合起来看,max-buffers设定的是最大的数据块数,max-epoch-size设定的是所能请求的最大块数。
ko-count:该选项设定一个值,把该选项设定的值 乘以 timeout设定的值,得到一个数字N,如果secondary节点没有在此时间内完成单次写请求,它将从集群中被移除(即,primary node进入StandAlong模式)。取值范围0~200,默认值为0,即禁用该功能。
allow-two-primaries:这个是drbd8.0及以后版本才支持的新特性,允许一个集群中有两个primary node。该模式需要特定文件系统的支撑,目前只有OCFS2和GFS可以,传统的ext3、ext4、xfs等都不行!
cram-hmac-alg:该选项可以用来指定HMAC算法来启用对等节点授权。drbd强烈建议启用对等节点授权机制。可以指定/proc/crypto文件中识别的任一算法。必须在此指定算法,以明确启用对等节点授权机制。
shared-secret:该选项用来设定在对待节点授权中使用的密码,最长64个字符。
data-integrity-alg:该选项设定内核支持的一个算法,用于网络上的用户数据的一致性校验。通常的数据一致性校验,由TCP/IP头中所包含的16位校验和来进行,而该选项可以使用内核所支持的任一算法。该功能默认关闭。
另外,还有after-sb-0pri, after-sb-1pri, after-sb-2pri这三个选项,split brian有关。
startup配置段:
该配置段用来更加精细地调节drbd属性,它作用于配置节点在启动或重启时。
译者注:我曾试过不配置此部分,在首次启用第二个节点的DRBD块设备时,遇到了一个问题:它一直等待有一个对等节点出现,而迟迟不肯启动,必须手动让它停止等待。如下:
常用选项有:
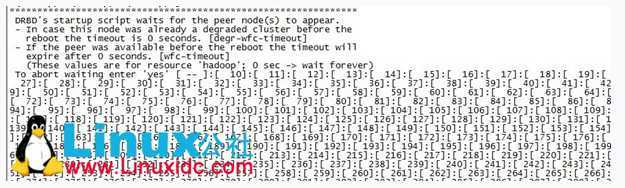
wfc-timeout:该选项设定一个时间值,单位是秒。在启用DRBD块时,初始化脚本drbd会阻塞启动进程的运行,直到对等节点的出现。该选项就是用来限制这个等待时间的,默认为0,即不限制,永远等待。
degr-wfc-timeout:该选项也设定一个时间值,单位为秒。也是用于限制等待时间,只是作用的情形不同:它作用于一个降级集群(即那些只剩下一个节点的集群)在重启时的等待时间。
outdated-wfc-timeout:同上,也是用来设定等待时间,单位为秒。它用于设定等待过期节点的时间。
syncer配置段:
该配置段用来更加精细地调节服务的同步进程。
常用选项有:
rate:设置同步时的速率,默认为250KB。默认的单位是KB/sec,也允许使用K、M和G,如40M。注意:syncer中的速率是以bytes,而不是bits来设定的。
配置文件中的这个选项设置的速率是永久性的,但可使用下列命令临时地改变rate的值:
drbdsetup /dev/drbdnum syncer -r 100M
把上述命令中红色的num替换成你的drbd设备的从设备号。只能在所有节点的其中一个节点上运行此命令。
如果想重新恢复成drbd.conf配置文件中设定的速率,执行如下命令:
drbdadm adjust resource
官方提示:速率的设定,最好设为有效可用带宽的30%。所谓有效可用带宽,是指网络带宽和磁盘读写速度中的最小者。有两个示例:
如果I/O子系统所能维持的读写速度为180MB/s,而千兆网络所能维持的网络吞吐速度为110MB/s,那么有效可用带宽为110MB/s,该选项的推荐值为110 x 0.3 = 33MB/s。
如果I/O速度为80MB/s,而网络连接速度可达千兆,那么有效可用带宽为80MB/s,推荐的rate速率应该为80 x 0.3 = 24MB/s
al-extents:该选项用来设定hot area(即active set)的块数,取值范围是7~3843,默认为127,每个块标志4M大小的底层存储(即底层设备)。DRBD会自动检测host area,如果主节点意外地从集群中断开,当该节点重新加入集群时,hot area所覆盖的区域必须被重新同步。hot area的每次变化,实际上都是对metadata区域的写操作,因此,该选项的值越大,重新同步的时间越长,但需要更新的meta-data也越少。
而用户手册的另外一部分提到,al-extents调整的是Activity Log的大小。如果使用DRBD设备的应用程序的写操作比较密集,那么,一般建议使用较大的Activity Log(active set),否则metadata频繁的更新操作会影响到写操作的性能。建议值:3389。
verify-alg:该选项指定一个用于在线校验的算法,内核一般都会支持md5、sha1和crc32c校验算法。在线校验默认关闭,必须在此选项设定参数,以明确启用在线设备校验。DRBD支持在线设备校验,它以一种高效的方式对不同节点的数据进行一致性校验。在线校验会影响CPU负载和使用,但影响比较轻微。drbd 8.2.5及以后版本支持此功能。
一旦启用了该功能,你就可以使用下列命令进行一个在线校验:
drbdadm verify resource
该命令对指定的resource进行检验,如果检测到有数据块没有同步,它会标记这些块,并往内核日志中写入一条信息。这个过程不会影响正在使用该设备的程序。
如果检测到未同步的块,当检验结束后,你就可以如下命令重新同步它们:
drbdadm disconnect resource
drbdadm connetc resource
可以安排一个cron任务来自动执行在线校验,如:
42 0 * * 0 root /sbin/drbdadm verify resource
如果开启了所有资源的在线检验,可以使用如下命令:
42 0 * * 0 root /sbin/drbdadm verify all
csums-alg:该选项指定一个校验算法,用来标志数据块。如果不启用该选项,rsync会从source发送所有的数据块到destination;而如果启用了此选项,那么rsync将只交换那些校验值不同的数据块,当网络带宽有限时,此选项非常有用。而且,在重启一个崩溃的primary节点时,该选项会降低CPU带宽的占用。
handlers:
该配置段用来定义一系列处理器,用来回应特定事件。
|
标签:des style blog http io os 使用 ar strong
原文地址:http://www.cnblogs.com/Elliot-wang/p/3994362.html
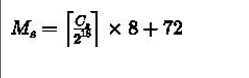 注:图片来自drbd官网。
注:图片来自drbd官网。