标签:doc min 方差 with orm removing port data mat
Sklearn的feature_selection模块中给出了其特征选择的方法,实际工作中选择特征的方式肯定不止这几种的,IV,GBDT等等都ok;
一、移除低方差特征(Removing features with low variance)
API函数:sklearn.feature_selection.VarianceThreshold(threshold=0.0)
VarianceThreshold是特征选择的一个简单基本方法,它会移除所有那些方差不满足一些阈值的特征。 在默认情况下,其会移除所有方差为0的特征,也就是所有取值相同的特征。
官网说:[
例如,假设我们有一个特征是布尔值的数据集,我们想要移除那些在整个数据集中特征值为0或者为1的比例超过80%的特征。布尔特征是伯努利( Bernoulli )随机变量,变量的方差为

因此,我们可以使用阈值 ``.8 * (1 - .8)``进行选择:
]
其用法可见,移除低于阈值的特征。但是对不不同的特征,其特征分布我们需要自己探索,即使对于离散特征数值化后或者连续特征,可以直接计算其方差。但是我认为这个选择特征的方法实际意义有待商榷;对于一个特征取值唯一的情况,这种方法是肯定可以发现的。但是如果一个特征是布尔值,即使整个数据集合中有特征值为0或者为1的比例超过80%的特征,并不能说明这个特征不好哇,其对目标变量的相关性如果还不错,你会忍心把这个变量剔除吗。对吧,所以我实际工作中,没用过这个方法。各抒己见!
二、单变量特征选择,Univariate feature selection
这个有用,比上一个API有用多了。慢慢来看。
官网说【单变量的特征选择是通过基于单变量的统计测试来选择最好的特征。它可以当做是评估器的预处理步骤】。是的哇,单变量的特征选择,出发点是想针对每一个特征单独检测其和目标变量Y的相关性,顾名思义单变量嘛。选择方法很多,具体区分又区分,你所做的模型是回归还是分类。
Scikit-learn 将特征选择的内容作为实现了 transform 方法的对象
(1)、SelectKBest移除那些除了评分最高的 K 个特征之外的所有特征
(2)、SelectPercentile移除除了用户指定的最高得分百分比之外的所有特征
这些对象将得分函数作为输入,返回单变量的得分和 p 值:
f_regression , mutual_info_regressionchi2 , f_classif , mutual_info_classif 可自行查看官网API文档。用例1,SelectPercentile的用法:
from sklearn.datasets import load_iris from sklearn.feature_selection import SelectKBest, SelectPercentile from sklearn.feature_selection import f_classif iris = load_iris() X, y = iris.data, iris.target sp = SelectPercentile(f_classif, percentile= 90) #得到返回至少含有90%特征信息的特征 X_result = sp.fit_transform(X, y) #可以看到哪些特征被保留 sp.get_support() #输出结果 array([ True, False, True, True], dtype=bool)
用例2,依然使用iris数据集,看一下mutual_info_classif 和pandas中的corr()函数的信息相关性计算结果对比;
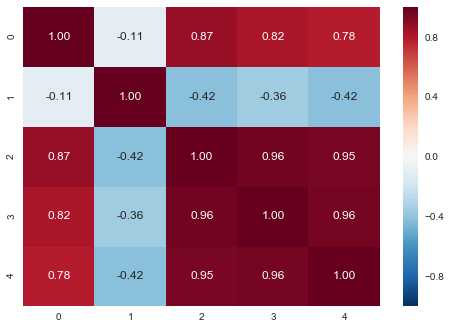
import pandas as pd from sklearn import datasets import numpy as np import seaborn as sns from sklearn.feature_selection import mutual_info_classif iris = datasets.load_iris() X = iris.data y = iris.target new_y = [y[i:i+1] for i in range(0, len(y), 1)] data = np.hstack((X, new_y)) data_df = pd.DataFrame(data) #0到3表示特征,4表示目标变量,画图查看相关性,如下图所示 sns.heatmap(data_df.corr(), annot= True, fmt= ‘.2f‘)
0,1,2,3特征和4(目标变量)的相关性分别为【0.18,-0.42, 0.95,0.96】
互信息相关性:
mutual_info = mutual_info_classif(X, y, discrete_features= False) #输出结果如下,和上面的结果对比看一下 array([ 0.48502046, 0.30654537, 0.99750059, 0.9849968 ])
三、递归特征消除(Recursive Feature Elimination)
官网解释:给定一个外部的估计器,可以对特征赋予一定的权重(比如,线性模型的相关系数),recursive feature elimination ( RFE ) 通过考虑越来越小的特征集合来递归的选择特征。 首先,评估器在初始的特征集合上面训练并且每一个特征的重要程度是通过一个 coef_ 属性 或者 feature_importances_ 属性来获得。 然后,从当前的特征集合中移除最不重要的特征。在特征集合上不断的重复递归这个步骤,直到最终达到所需要的特征数量为止。
用例:
from sklearn.feature_selection import RFE from sklearn.ensemble import GradientBoostingClassifier from sklearn import datasets iris = datasets.load_iris() gbdt_RFE = RFE(estimator=GradientBoostingClassifier(random_state= 123),n_features_to_select=2) gbdt_RFE.fit(iris.data, iris.target) gbdt_RFE.support_ #特征选择输出结果 gbdt_RFE.support_ #输出结果为: array([False, False, True, True], dtype=bool)
四、使用SelectFromModel 选取特征(Feature selection using SelectFromModel)
官网解释:SelectFromModel是一个 meta-transformer(元转换器) ,它可以用来处理任何带有 coef_ 或者 feature_importances_ 属性的训练之后的评估器。 如果相关的``coef_`` 或者 featureimportances 属性值低于预先设置的阈值,这些特征将会被认为不重要并且移除掉。除了指定数值上的阈值之外,还可以通过给定字符串参数来使用内置的启发式方法找到一个合适的阈值。可以使用的启发式方法有 mean 、 median 以及使用浮点数乘以这些(例如,0.1*mean )
4.1、基于 L1 的特征选取
用例:
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_selection import SelectFromModel iris = load_iris() X, y = iris.data, iris.target lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y) model = SelectFromModel(lsvc, prefit=True) X_new = model.transform(X) X_new.shape
4.2、基于 Tree(树)的特征选取
基于树的 estimators (查阅 sklearn.tree 模块和树的森林 在 sklearn.ensemble 模块) 可以用来计算特征的重要性。
用例:
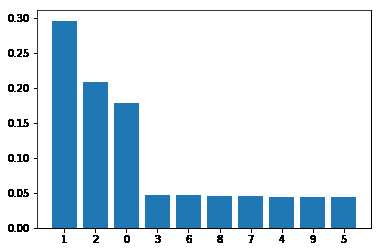
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_classification from sklearn.ensemble import ExtraTreesClassifier # Build a classification task using 3 informative features X, y = make_classification(n_samples=1000, n_features=10, n_informative=3, n_redundant=0, n_repeated=0, n_classes=2, random_state=0, shuffle=False) # Build a forest and compute the feature importances forest = ExtraTreesClassifier(n_estimators=250, random_state=0) forest.fit(X,y) importances = forest.feature_importances_ indices = np.argsort(importances)[::-1] #作图观察特征重要性 plt.bar(range(10), importances[indices]) plt.xticks(range(X.shape[1]), indices) plt.show()
五、特征选取作为 pipeline(管道)的一部分(Feature selection as part of a pipeline)
官网解释:
特征选择通常在实际的学习之前用来做预处理。在 scikit-learn 中推荐的方式是使用 :sklearn.pipeline.Pipeline:
clf = Pipeline([ (‘feature_selection‘, SelectFromModel(LinearSVC(penalty="l1"))), (‘classification‘, RandomForestClassifier()) ]) clf.fit(X, y)
在这段代码中,我们利用 sklearn.svm.LinearSVC 和 sklearn.feature_selection.SelectFromModel 来评估特征的重要性并且选择出相关的特征。 然后,在转化后的输出中使用一个 sklearn.ensemble.RandomForestClassifier 分类器,比如只使用相关的特征。你也可以使用其他特征选择的方法和可以提供评估特征重要性的分类器来执行相似的操作。 请查阅 sklearn.pipeline.Pipeline 来了解更多的实例。
特征选择- Sklearn.feature_selection的理解
标签:doc min 方差 with orm removing port data mat
原文地址:https://www.cnblogs.com/nobbyoucanyouup/p/9026146.html