标签:jieba htm axis gen word col 需要 SQ argument
环境
Python3,
gensim,jieba,numpy ,pandas
原理:文章转成向量,然后在计算两个向量的余弦值。
Gensim
gensim是一个python的自然语言处理库,能够将文档根据TF-IDF, LDA, LSI 等模型转化成向量模式,gensim还实现了word2vec功能,以便进行进一步的处理。
具体API看官网:https://radimrehurek.com/gensim
中文分词
中文需要分词,英文就不需要了,分词用的 jieba 。
def segment(doc: str):
"""中文分词
Arguments:
doc {str} -- 输入文本
Returns:
[type] -- [description]
"""
# 停用词
stop_words = pd.read_csv("./data/stopwords_TUH.txt", index_col=False, quoting=3,
names=['stopword'],
sep="\n",
encoding='utf-8')
stop_words = list(stop_words.stopword)
# 去掉html标签数字等
reg_html = re.compile(r'<[^>]+>', re.S)
doc = reg_html.sub('', doc)
doc = re.sub('[0-9]', '', doc)
doc = re.sub('\s', '', doc)
word_list = list(jieba.cut(doc))
out_str = ''
for word in word_list:
if word not in stop_words:
out_str += word
out_str += ' '
segments = out_str.split(sep=" ")
return segments训练 Doc2Vec 模型
模型参数下面说明,先上代码
def train():
"""训练 Doc2Vec 模型
"""
# 先把所有文档的路径存进一个 array中,docLabels:
data_dir = "./data/corpus_words"
docLabels = [f for f in listdir(data_dir) if f.endswith('.txt')]
data = []
for doc in docLabels:
ws = open(data_dir + "/" + doc, 'r', encoding='UTF-8').read()
data.append(ws)
print(len(data))
# 训练 Doc2Vec,并保存模型:
sentences = LabeledLineSentence(data, docLabels)
# 实例化一个模型
model = gensim.models.Doc2Vec(vector_size=256, window=10, min_count=5,
workers=4, alpha=0.025, min_alpha=0.025, epochs=12)
model.build_vocab(sentences)
print("开始训练...")
# 训练模型
model.train(sentences, total_examples=model.corpus_count, epochs=12)
model.save("./models/doc2vec.model")
print("model saved")保存成功后会有三个文件,分别是:doc2vec.model,doc2vec.model.trainables.syn1neg.npy,doc2vec.model.wv.vectors.npy
Doc2Vec参数说明:
· vector_size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好.
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· workers参数控制训练的并行数。
· epochs: 迭代次数,默认为5
文本转换成向量
利用之前保存的模型,把分词后的分本转成向量,代码如下
def sent2vec(model, words):
"""文本转换成向量
Arguments:
model {[type]} -- Doc2Vec 模型
words {[type]} -- 分词后的文本
Returns:
[type] -- 向量数组
"""
vect_list = []
for w in words:
try:
vect_list.append(model.wv[w])
except:
continue
vect_list = np.array(vect_list)
vect = vect_list.sum(axis=0)
return vect / np.sqrt((vect ** 2).sum())计算两个向量余弦值
余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近;越趋近于-1,他们的方向越相反;接近于0,表示两个向量近乎于正交。
最常见的应用就是计算文本相似度。将两个文本根据他们词,建立两个向量,计算这两个向量的余弦值,就可以知道两个文本在统计学方法中他们的相似度情况。实践证明,这是一个非常有效的方法。
公式:
def similarity(a_vect, b_vect):
"""计算两个向量余弦值
Arguments:
a_vect {[type]} -- a 向量
b_vect {[type]} -- b 向量
Returns:
[type] -- [description]
"""
dot_val = 0.0
a_norm = 0.0
b_norm = 0.0
cos = None
for a, b in zip(a_vect, b_vect):
dot_val += a*b
a_norm += a**2
b_norm += b**2
if a_norm == 0.0 or b_norm == 0.0:
cos = -1
else:
cos = dot_val / ((a_norm*b_norm)**0.5)
return cos预测
def test_model():
print("load model")
model = gensim.models.Doc2Vec.load(‘./models/doc2vec.model‘)
st1 = open('./data/courpus_test/t1.txt', 'r', encoding='UTF-8').read()
st2 = open('./data/courpus_test/t2.txt', 'r', encoding='UTF-8').read()
# 分词
print("segment")
st1 = segment(st1)
st2 = segment(st2)
# 转成句子向量
vect1 = sent2vec(model, st1)
vect2 = sent2vec(model, st2)
# 查看变量占用空间大小
import sys
print(sys.getsizeof(vect1))
print(sys.getsizeof(vect2))
cos = similarity(vect1, vect2)
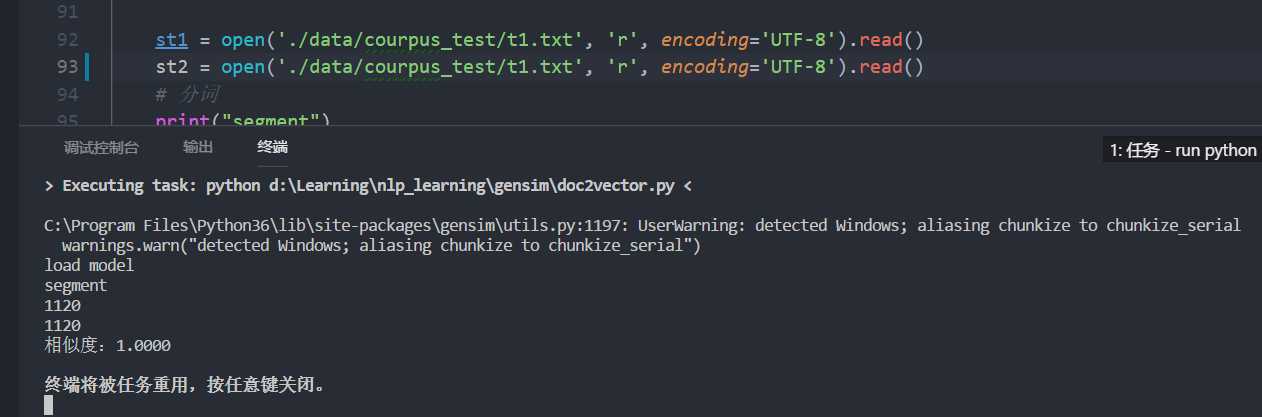
print("相似度:{:.4f}".format(cos))看下效果:
完全相同的文章
不相同的文章
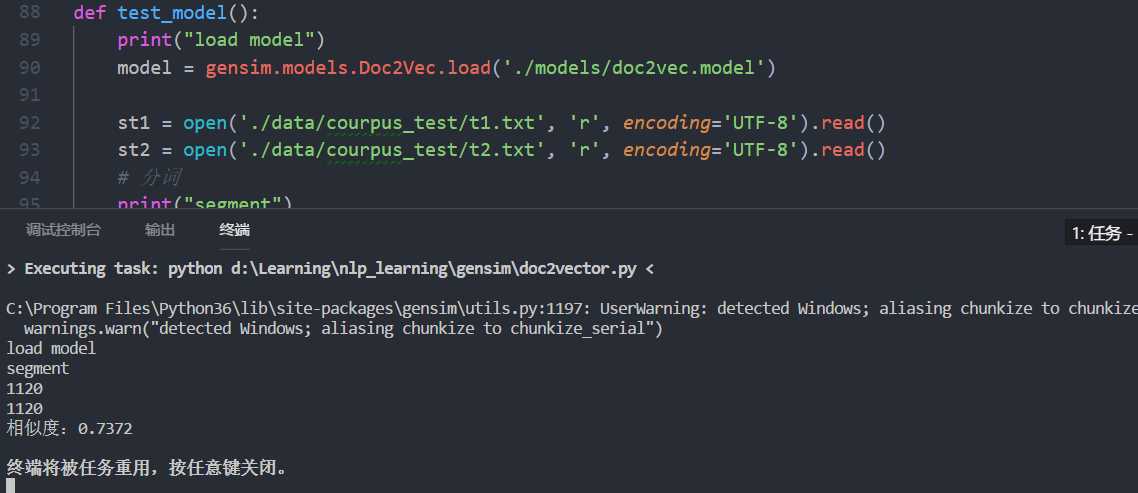
数据太大,没有上传,自己网上找找应该有很多。
完整代码:https://github.com/jarvisqi/nlp_learning/blob/master/gensim/doc2vector.py
参考:
【机器学习】使用gensim 的 doc2vec 实现文本相似度检测
标签:jieba htm axis gen word col 需要 SQ argument
原文地址:https://www.cnblogs.com/JreeyQi/p/9042397.html