文章转自:http://www.cnblogs.com/CoderTian/p/8477021.html
1.MPEG-4标准概述
- 与MPEG1和MPEG2标准相比,MPEG-4 更加注重多媒体系统的交互性和灵活性,主要应用于可视电话、视频会议等。
- MPEG-4 标准主要包含音视频对象编码工具集和编码对象句法语言两个部分。
- MPEG-4 标准的编码基于对象,便于操作和控制对象,MPEG-4 的对象操作使用户可在终端直接将不同对象进行拼接,得到用户合成图像。
- MPEG-4 具有很好的扩展性,可进行时域和空域的扩展,MPEG-4 可根据带宽和误码率的客观条件,在时域或空域进行扩展。前者指在带宽允许时增加帧率带宽窄时,减少帧率,以达到充分利用带宽;后者指对图像进行采样插值,增加或减少空间分辨率。
- MPEG-4 有多种算法,可根据需要选择,例如区域编码有 DCT、 SADCT、 OWT 等等。
- MPEG-4 为了支持高效压缩、基于内容交互和基于内容分级扩展,以基于内容的方式表示视频数据,引入 AVO(Audio/Video Object)的概念实现基于内容的表示。
2.AVO及数据结构
AVO 基本单位是原始 AV 对象,可能是一个没有背景的说话的人,也可能是这个人的语音或背景音乐等等。它具有高效编码、高效存储传播及可交互操作的特性。MPEG-4 就是围绕 AV 对象的编码、存储、传输和组合而制定的。 MPEG-4 对 AV 对象的主要操作如下:
(1)采用 AV 对象表示音视频或其组合内容;
(2)组合已有 AV 对象,通过自然混合编码 SNHC 组织;
(3)可对 AV 对象数据多路合成和同步,以便选择合适网络传输数据;
(4)允许用户对 AV 对象进行交互操作;
(5)支持 AV 对象知识产权和保护
MPEG-4 是第一个使用户可在接收端对画面进行操作和交互访问的编码标准。在 MPEG-4 校验模型中, VO(Video Object) 主要定义为画面中分割出来的不同物体, 并由三类信息描述:运动信息、形状信息、纹理信息。MPEG-4 视频数据流的逻辑结构如下图所示:
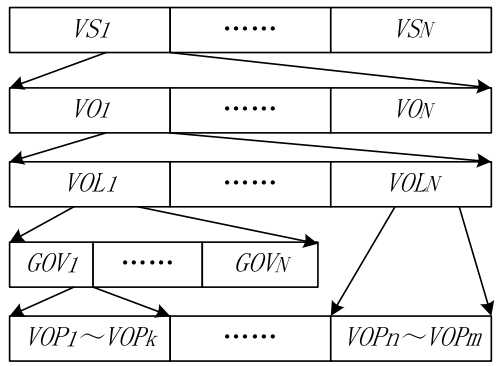
- VOP(Video Object Plane,视频对象平面)可看作 VO 在某一时刻的表示,即某一帧; GOV(Group of VOPs,视频对象平面组)提供视频流的标记点,标记 VOP 单独解码的时域位置,也即对视频流任意访问的标记;
- VOL(Video Object Layer,视频对象层),用于扩展 VO 的时域和空域分辨率,包含 VO 的三种属性信息;
- VO(Video Object,视频对象)如前所述,为场景中的某个物体,有生命期,由时间上连续的许多帧构成;
- VS(Video Session,视频镜头),一个完整的视频序列由几个 VS 组成。
每个 VS 由一个或多个 VO 构成,每个 VO 可能有一个或多个 VOL 层,如基本层、增强层等,每个层是 VO 的某一分辨率表示。每个层中都有时间连续的 GOV,每个 GOV 又由一系列的VOP 构成。
3.MPEG-4标准构成
MPEG-4 提供自然和合成的音频、视频以及图形的基于对象的编码工具。类似于以前标准,MPEG-4 由若干部分组成, 主要部分为系统、视频和音频。 MPEG-4 码流主要包括基本码流和系统流, 基本码流包括音视频和场景描述的编码流表示,每个基本码流只包含一种数据类型,并通过各自的解码器解码;系统流则指定根据编码视听信息和相关场景描述信息产生交互方式的方法,并描述其交互通信系统。
3.1.系统
MPEG-4 系统把音视频对象及其组合复用成一个场景,提供与场景互相作用的工具,使用户具有交互能力。 MPEG-4 的系统终端模型如下图所示
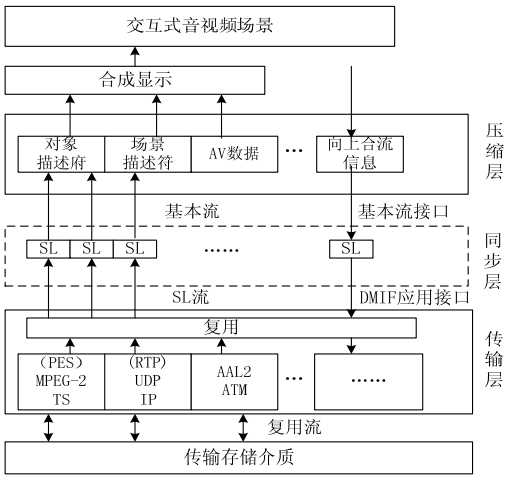
(1)压缩层,执行媒体解码的系统组件。媒体是通过基本码流接口从同步层提取的。
(2)同步层,负责各个压缩媒体的同步和缓冲。它接收来自传输层的同步层包(SL),根据基本码流的时间标志进行拆包,并转发到压缩层。
(3)传输层,对已经存在的各种传输协议描述。这些协议能够用来传输和存储符合 MPEG-4标准的视听内容。
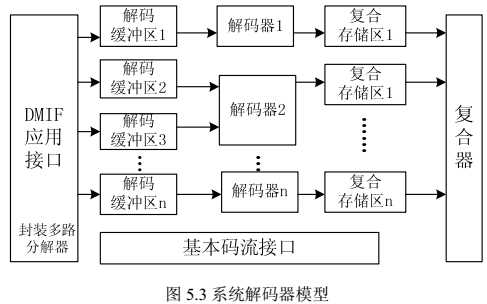
系统解码器模型包括定时模型和缓冲模型两种。如下图所示,每个基本码流都有一个单独的解码缓冲区,单个解码器可以解码多个基本码流(如扩展的视听对象解码)。
3.2.音频
与 MPEG-1、 MPEG-2 相比, MPEG-4 不仅支持自然声音(如语音和音乐), 还支持合成声音(如MIDI)。 MPEG-4 音频部分将音频的合成编码和自然声音的编码相结合,并支持音频的对象特征。
1.自然声音编码
MPEG-4 支持 2Kbps~64 Kbps 的自然声音编码。如 8KHz采样频率的 2Kbps~4 Kbps 的语音编码,以及 8KHz 或 16KHz 采样频率 4Kbps~16 Kbps 的语音编码,一般采用参数编码;而 6Kbps~24 Kbps 的语音编码,一般采用码激励线性预测 CELP(CodeExcited Linear Predictive)编码技术;而从 16Kbps 以上码率的编码,则采用视频变换编码技术。
2.合成语音编码
MPEG-4 引入两个有力的编码技术:文本到语音编码(TTS, Text-to-Speech)和乐谱驱动合成编码。事实上,合成语音编码技术是一种基于知识库的参数编码。
3.3.视频
MPEG-4 支持对自然和合成视觉对象的编码。合成的视觉对象包括 2D、 3D 动画和人面部表情动画等。对于静止图像, MPEG-4 采用零树小波算法(Zerotree Wavelet Algorithm),以提高压缩比,同时还提供多达 11 级的空间分辨率和质量的可伸缩性。对于运动视频对象的编码, MPEG-4 采用了如下图 所示编码框图,以支持对象的编码。
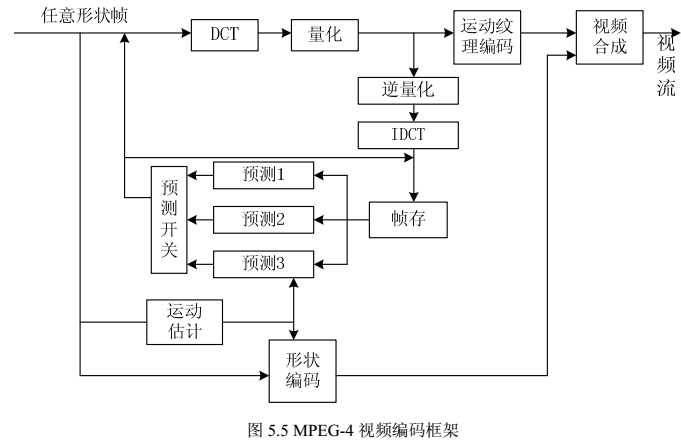
MPEG-4 相对 MPEG-1、 MPEG-2 而言,编码效率显著提高除了因为基于内容的性质外,还因为引入了以下的编码工具。
- DC 预测,可选择当前块的前一块或者后一块作为当前 DC 值
- AC 预测, DCT 系数的 AC 预测在 MPEG-4 中是新的。选择用来预测 DC 系数的块也用于预测一行 AC 系数。AC 预测对于具有粗糙纹理、对角边缘或水平以及垂直边缘的块效果不佳。在块级切换 AC 预测的通断是所希望的,但这代价太大,一般在宏块级作出
- 交替水平扫描,这种扫描被添加到 MPEG-2 的两种扫描中。 MPEG-2 的交替扫描在 MPEG-4中被称为交替垂直扫描
- 三维 VLC, DCT 系数编码与 H.263 类似
- 四个运动矢量,允许宏块的四个运动矢量,与 H.263 类似
- 无约束运动矢量,与 H.263 相比,可以使用宽得多的±048 像素的运动矢量范围
- 子图形,子图形基本上是一个传输到解码器的大背景图像,为了显示,编码器传送该图像的一部分并映射到屏幕上仿射映射参数。通过改变映射,解码器可以放大和缩小子图形,以及向左或向右。
- 全局运动补偿,为了补偿由于摄像机运动、摄像机变焦或者大运动物体引起的全局运动,按照下列公式的八参数运动模型进行补偿:
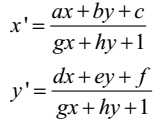
全局运动补偿有助于改善最挑剔的场景中的图像质量
- 四分之一像素运动补偿,主要目的是以小的语法和计算上代价来提高运动补偿的分辨率,得到更精确的运动描述和较小的预测误差。四分之一像素运动补偿只用于亮度像素,色度像素则是用半像素精度运动补偿。
1.基于VOP的编码
某一时刻 VO 以 VOP 的形式出现,编码也主要针对这个时刻 VO 的形状、运动、纹理这三类信息进行。
- 形状编码:相对以前标准而言, MPEG-4 第一次引入形状编码的压缩算法。编码的形状信息有两种:二值形状信息(Binary Shape Information)和灰度级形状信息(Grey Scale Shape Information)。二值形状信息为用 0、 1 的方式表示编码 VOP 形状, 0 表示非 VOP 区域, 1 表示 VOP 区域;灰度级形状信息可取值 0~255, 0 表示非 VOP 区域(即透明区域), 1~255 表示透明度不同的区域, 255 表示完全不透明。 灰度级形状信息的引入主要为了使前景物体叠加到背景上时,边界不至于太明显、生硬,进行“模糊”处理。MPEG-4 采用位图法表示这两种形状信息。 VOP 被一个“边框”框住,如下图所示
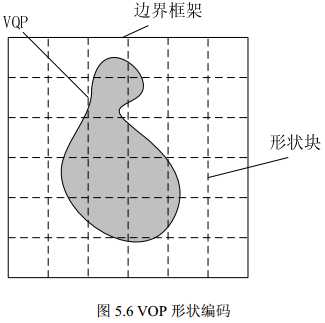
位图表示法实际就是一个边框矩阵,取值为 0~255(或 0、1),编码变为对该矩阵的编码。矩阵倍分为 16×16
的形状块,允许进行有损编码,这要通过对边界信息子采样实现,同时允许使用宏块运动矢量作形状块的运动补偿。为了得到语义上更方便的描述,以支持基于内容的操作,
MPEG-4 还引入基于上下文的算术编码。
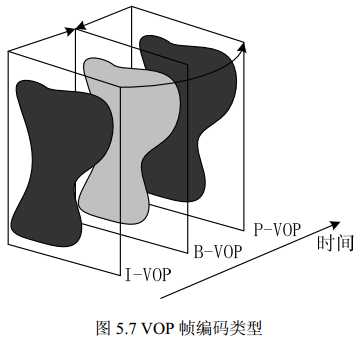
- 运动估计和运动补偿:类似于以前的压缩标准(MPEG-1、 H.263 等)的三种帧格式: I、 P、 B, MPEG-4 的 VOP 也有三种相应的帧格式: I-VOP、 P-VOP、 B-VOP,表示运动补偿类型的不同。运动估计和补偿可以基于宏块,也可基于块。
- 纹理编码:纹理信息可能有两种:内部编码的 I-VOP 像素值和帧间编码的 P-VOP、 B-VOP 的运动估计残差值。 MPEG-4 采用基于分块的纹理编码, VOP 边框仍分为 16×16 的宏块。
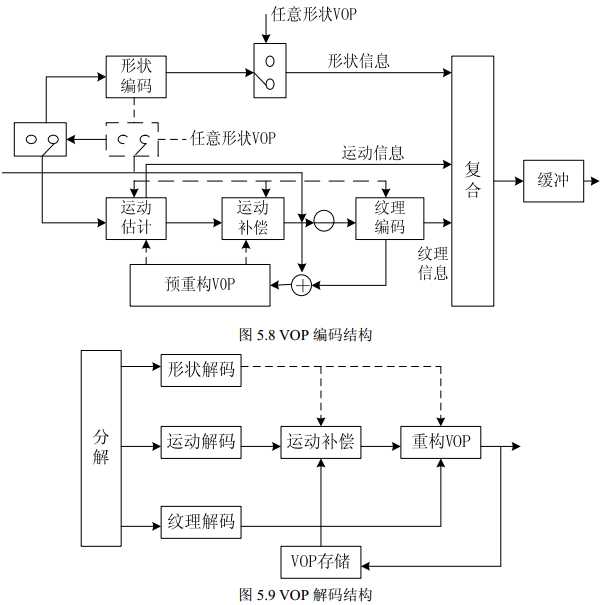
2.VOP编解码结构框图
VOP 编解码器主要由两部分组成:形状编解码和传统运动纹理编解码。重构的 VOP 由形状、纹理和运动信息正确组合而成
标签:线性 音乐 format 组织 red 存在 表示法 convert alt
原文地址:https://www.cnblogs.com/legendsun/p/9043002.html