标签:hub bubuko get 目标 新建 动态路由 策略 inf key
redis 集群方案主要有两类,一是使用类 codis 的架构,按组划分,实例之间互相独立;
另一套是基于官方的 redis cluster 的方案;下面分别聊聊这两种方案;
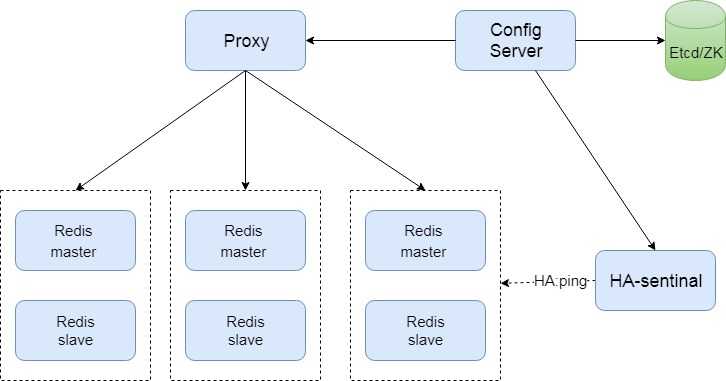
这套架构的特点:
使用这套方案的公司:
阿里云: ApsaraCache, RedisLabs、京东、百度等
slots 方案:划分了 1024个slot, slots 信息在 proxy层感知; redis 进程中维护本实例上的所有key的一个slot map;
迁移过程中的读写冲突处理:
最小迁移单位为key;
访问逻辑都是先访问 src 节点,再根据结果判断是否需要进一步访问 target 节点;
AparaCache 的单机版已开源(开源版本中不包含slot等实现),集群方案细节未知;ApsaraCache
主要组件:
proxy,基于twemproxy 改造,实现了动态路由表;
redis内核: 基于2.x 实现的slots 方案;
metaserver:基于redis实现,包含的功能:拓扑信息的存储 & 探活;
最多支持1000个节点;
slot 方案:
redis 内核中对db划分,做了16384个db; 每个请求到来,首先做db选择;
数据迁移实现:
数据迁移的时候,最小迁移单位是slot,迁移中整个slot 处于阻塞状态,只支持读请求,不支持写请求;
对比 官方 redis cluster/ codis 的按key粒度进行迁移的方案:按key迁移对用户请求更为友好,但迁移速度较慢;这个按slot进行迁移的方案速度更快;
主要组件:
proxy: 自主实现,基于 golang 开发;
redis内核:基于 redis 2.8
configServer(cfs)组件:配置信息存放;
scala组件:用于触发部署、新建、扩容等请求;
mysql:最终所有的元信息及配置的存储;
sentinal(golang实现):哨兵,用于监控proxy和redis实例,redis实例失败后触发切换;
slot 方案实现:
在内存中维护了slots的map映射表;
数据迁移:
基于 slots 粒度进行迁移;
scala组件向dst实例发送命令告知会接受某个slot;
dst 向 src 发送命令请求迁移,src开启一个线程来做数据的dump,将这个slot的数据整块dump发送到dst(未加锁,只读操作)
写请求会开辟一块缓冲区,所有的写请求除了写原有数据区域,同时双写到缓冲区中。
当一个slot迁移完成后,把这个缓冲区的数据都传到dst,当缓冲区为空时,更改本分片slot规则,不再拥有该slot,后续再请求这个slot的key返回moved;
上层proxy会保存两份路由表,当该slot 请求目标实例得到 move 结果后,更新拓扑;
跨机房:跨机房使用主从部署结构;没有多活,异地机房作为slave;
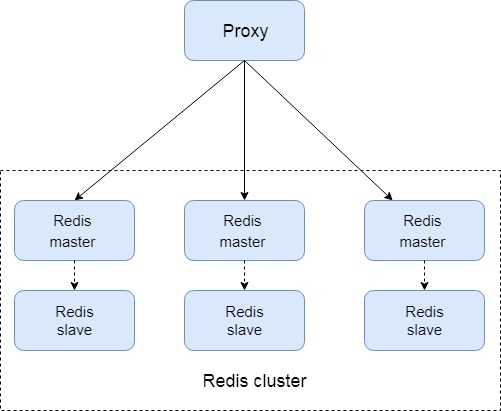
和上一套方案比,所有功能都集成在 redis cluster 中,路由分片、拓扑信息的存储、探活都在redis cluster中实现;各实例间通过 gossip 通信;这样的好处是简单,依赖的组件少,应对400个节点以内的场景没有问题(按单实例8w read qps来计算,能够支持 200 * 8 = 1600w 的读多写少的场景);但当需要支持更大的规模时,由于使用 gossip协议导致协议之间的通信消耗太大,redis cluster 不再合适;
使用这套方案的有:AWS, 百度贴吧
数据迁移过程:
基于 key粒度的数据迁移;
迁移过程的读写冲突处理:
从A 迁移到 B;
ElasticCache 支持主从和集群版、支持读写分离;
集群版用的是开源的Redis Cluster,未做深度定制;
基于redis cluster + twemproxy 实现;后被 BDRP 吞并;
twemproxy 实现了 smart client 功能;使用 redis cluster后还加一层 proxy的好处:
即将发布的 redis 5.0 中有个 feature,作者计划给 redis cluster加一个proxy。
ksarch-saas 对 twemproxy的改造已开源:
https://github.com/ksarch-saas/r3proxy
标签:hub bubuko get 目标 新建 动态路由 策略 inf key
原文地址:https://www.cnblogs.com/me115/p/9043420.html