标签:check AC 二次 消息 执行 prope textfile ima ado

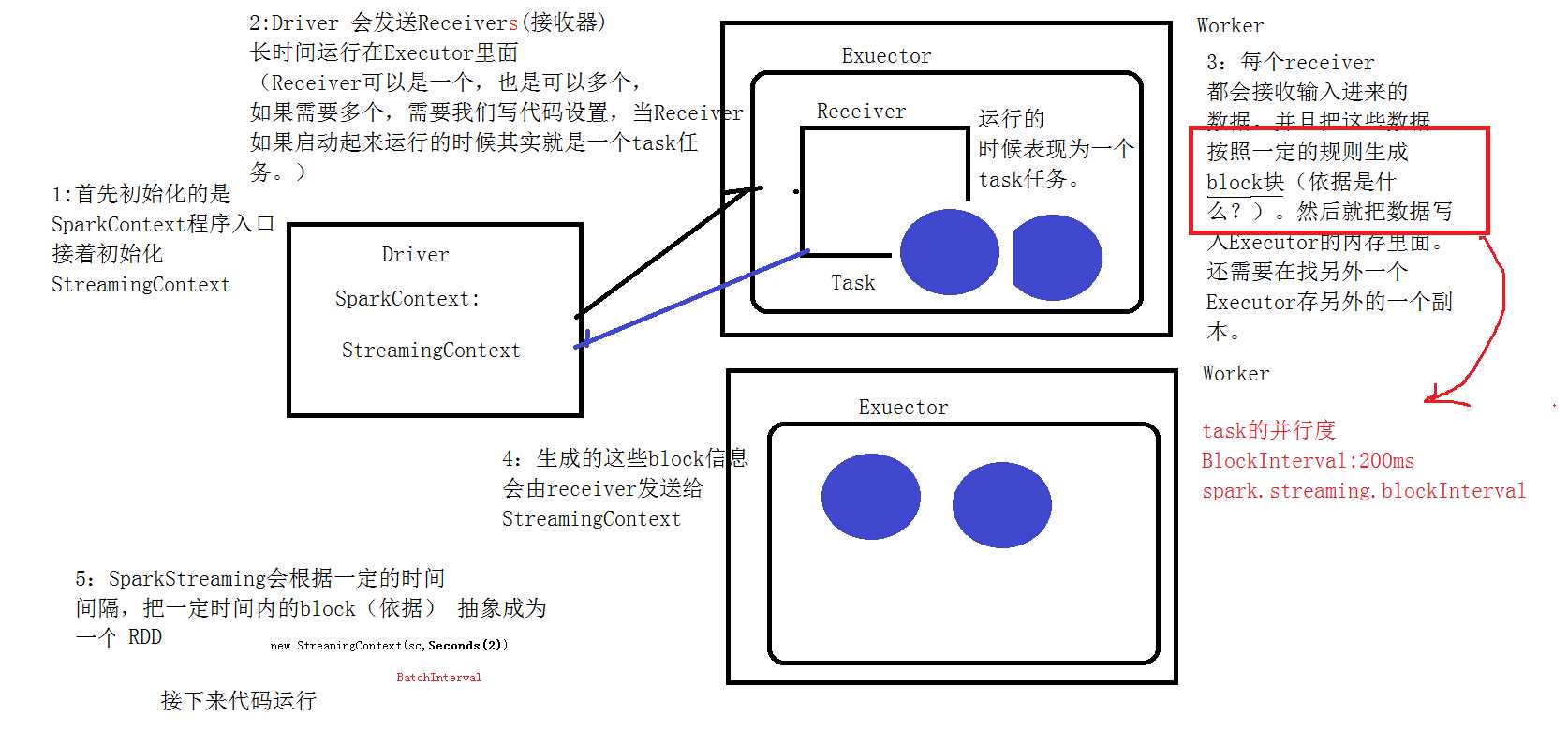
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Excuter,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的excuter,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
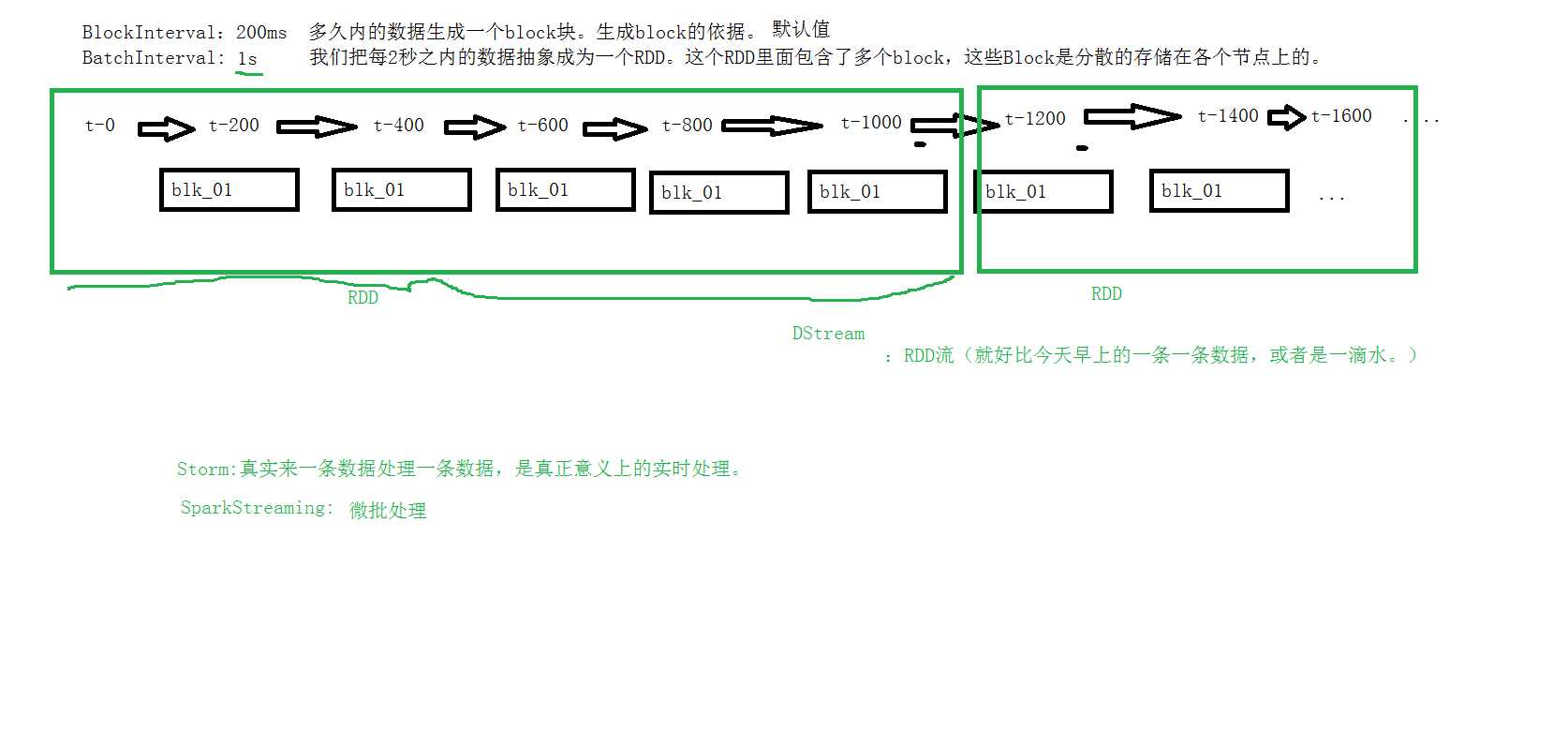
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
Scala代码
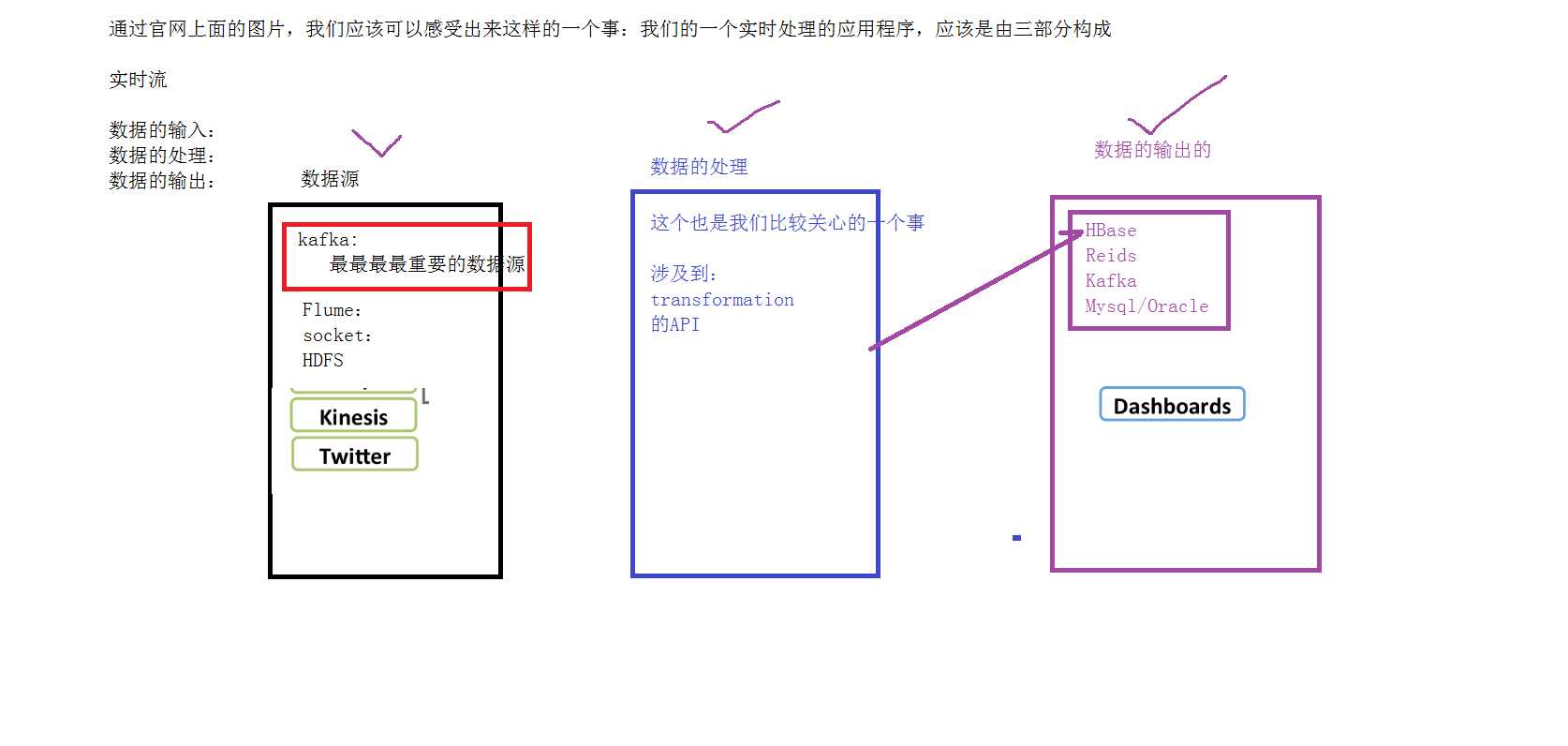
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} object NetWordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]") val sparkContext = new SparkContext(conf) val sc = new StreamingContext(sparkContext,Seconds(2)) /** * 数据的输入 * */ val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("bigdata",9999) inDStream.print() /** * 数据的处理 * */ val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_) /** * 数据的输出 * */ resultDStream.print() /** *启动应用程序 * */ sc.start() sc.awaitTermination() sc.stop() } }
在Linux上执行以下命令

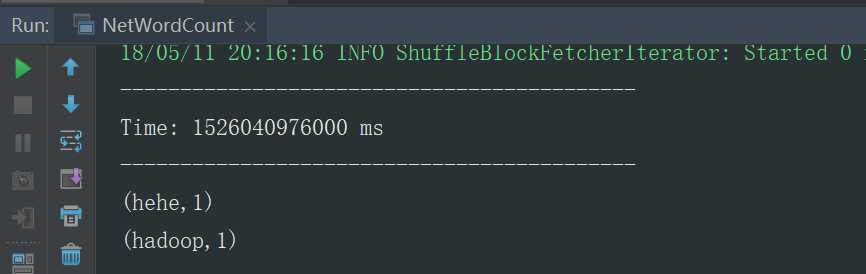
运行结果
HDFS上的目录需要先创建
Scala代码
import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.{Seconds, StreamingContext} object HDFSWordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName) val sc = new StreamingContext(conf,Seconds(2)) val inDStream: DStream[String] = sc.textFileStream("hdfs://hadoop1:9000/streaming") val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_) resultDStream.print() sc.start() sc.awaitTermination() sc.stop() } }
Linux上的命令
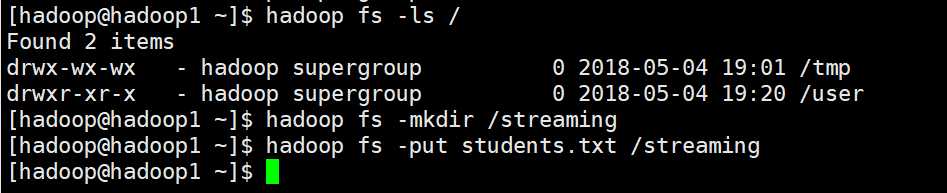
student.txt
95002,刘晨,女,19,IS 95017,王风娟,女,18,IS 95018,王一,女,19,IS 95013,冯伟,男,21,CS 95014,王小丽,女,19,CS 95019,邢小丽,女,19,IS
运行结果,默认展示的10条
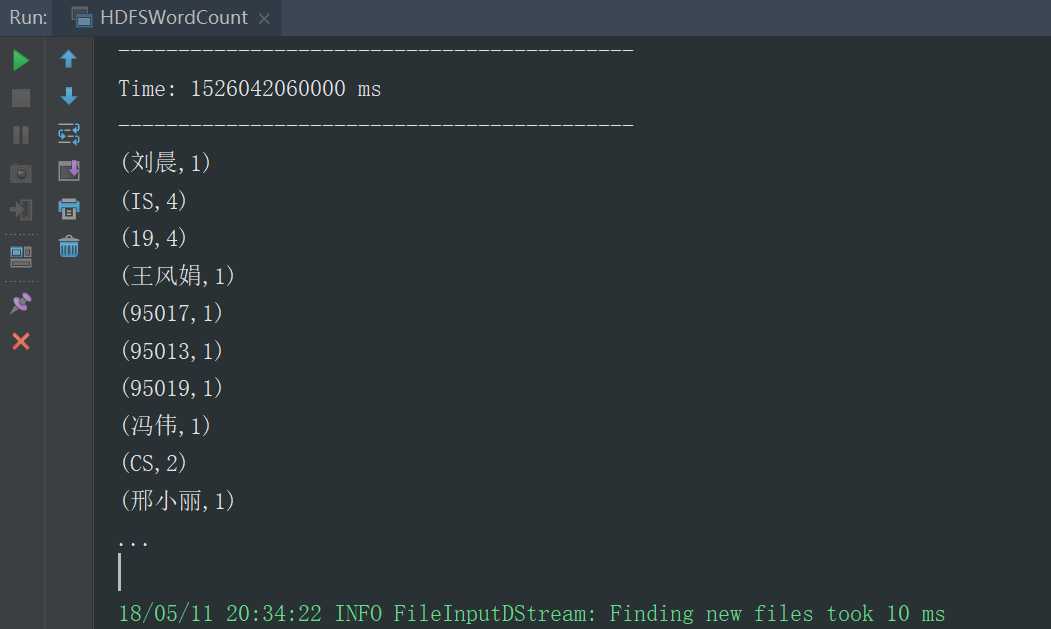
Scala代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} object UpdateWordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]") System.setProperty("HADOOP_USER_NAME","hadoop") val sparkContext = new SparkContext(conf) val sc = new StreamingContext(sparkContext,Seconds(2)) sc.checkpoint("hdfs://hadoop1:9000/streaming") val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("hadoop1",9999) val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")) .map((_, 1)) .updateStateByKey((values: Seq[Int], state: Option[Int]) => { val currentCount: Int = values.sum val lastCount: Int = state.getOrElse(0) Some(currentCount + lastCount) }) resultDStream.print() sc.start() sc.awaitTermination() sc.stop() } }
Linux运行命令
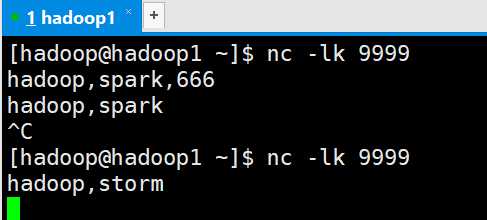
运行结果
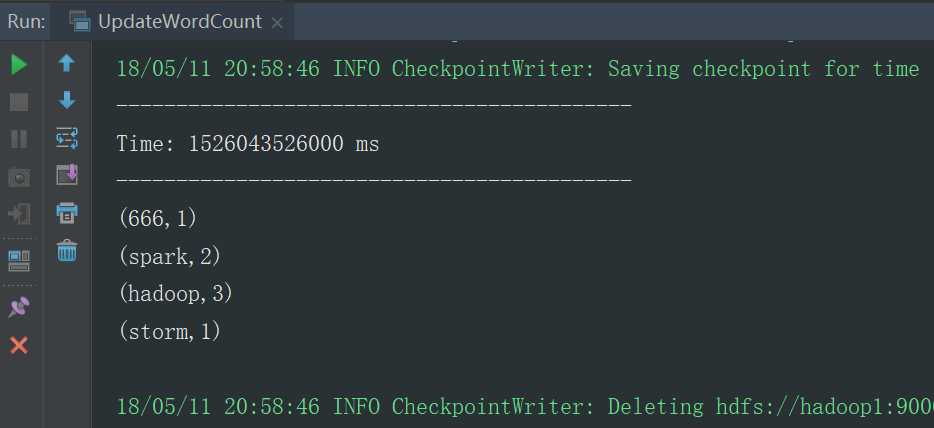
5.3的代码一直运行,结果可以一直累加,但是代码一旦停止运行,再次运行时,结果会不会接着上一次进行计算,上一次的计算结果丢失了,主要原因上每次程序运行都会初始化一个程序入口,而2次运行的程序入口不是同一个入口,所以会导致第一次计算的结果丢失,第一次的运算结果状态保存在Driver里面,所以我们如果想用上一次的计算结果,我们需要将上一次的Driver里面的运行结果状态取出来,而5.3里面的代码有一个checkpoint方法,它会把上一次Driver里面的运算结果状态保存在checkpoint的目录里面,我们在第二次启动程序时,从checkpoint里面取出上一次的运行结果状态,把这次的Driver状态恢复成和上一次Driver一样的状态
Spark学习之路 (二十三)SparkStreaming的官方文档
标签:check AC 二次 消息 执行 prope textfile ima ado
原文地址:https://www.cnblogs.com/qingyunzong/p/9026429.html