标签:article 字符 equal 检查 保存 偏移量 glob elements sea
上一节中介绍了 通过cell类构建RNN的函数,其中有一个参数initial_state,即cell初始状态参数,TensorFlow中封装了对其初始化的方法。
对于正向或反向,第一个cell传入时没有之前的序列输出值,所以需要对其进行初始化。一般来讲,不用刻意取指定,系统会默认初始化为0,当然也可以手动指定其初始化为0.
initial_state = lstm_cell.zero_state(batch_size, dtype=tf.float32)
在确保创建组成RNN的cell时,设置了输出为元组类型(即初始化state_is_tuple=True)的前提下,刻意使用LSTMStateTuple函数。但是有时想给lstm_cell的initial_state赋予我们想要的值,而不简单的用0来初始化。
可以把 LSTMStateTuple() 看做一个op.
from tensorflow.contrib.rnn.python.ops.core_rnn_cell_impl import LSTMStateTuple ... c_state = ... h_state = ... # c_state , h_state 都为Tensor initial_state = LSTMStateTuple(c_state, h_state)
当然,GRU就没有这么麻烦了,因为GRU没有两个state。
RNN的优化技巧有很多,对于前面讲述的神经网络技巧大部分在RNN上都适用,但是也有例外,下面就来介绍下RNN自己特有的两个优化方法的处理。
在RNN中,如果想使用dropout功能,不能使用以前的dropout。
def tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None): # pylint: disable=invalid-name
因为RNN有自己的dropout,并且实现方式与RNN不一样。
def tf.nn.rnn_cell.DropoutWrapper(self, cell, input_keep_prob=1.0,
output_keep_prob=1.0,state_keep_prob=1.0,
variational_recurrent=False,input_size=None,
dtype=None, seed=None):
使用例子:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_cell,output_keep_prob = 0.5)
从t-1时刻的状态传递到t时刻进行计算,这中间不进行memory的dropout,仅在同一个t时刻中,多层cell之间传递信息时进行dropout。所以RNN的dropout方法会有两个设置参数input_keep_prop(传入cell的保留率)和output_keep_prob(输出cell的保留率)。
例子:
lstm_cell=tf.nn.rnn_cell.BasicLSTMCell(size,forget_bias=0.0,state_is_tuple=True)
lstm_cell=tf.nn.rnn_cell.DropoutWrapper(lstm_cell,output_keep_prob=0.5)
在上面代码中,一个RNN层后面跟一个DropoutWrapper,是一种常见的用法。
RNN中dropout详情请点击这里:RNN变体之dropout
这部分内容是对应于批归一化(BN)的。由于RNN的特殊结构,它的输入不同于前面所讲的全连接、卷积网络。
由于RNN的网络都被LSTM,GRU这样的结构给封装起来,所以想实现LN并不像BN那样直接在外层加一个BN层就可以,需要需要改写LSTM或GRU的cell,对其内部的输入进行归一化处理。
TensorFlow中目前还不支持这样的cell,所以需要开发者自己来改写cell的代码,具体的方法可以在下面例子中讲到。
下面程序我们对每个样本进行归一化处理,即通过计算每个样本的均值和方差,然后归一化处理,注意这里并不是批归一化,批归一化是针对batch_size个样本计算均值方差,然后归一化处理。代码如下:
# -*- coding: utf-8 -*- """ Created on Thu May 17 14:35:38 2018 @author: zy """ ‘‘‘ 在GRUCell中实现LN ‘‘‘ import tensorflow as tf import numpy as np from tensorflow.contrib.rnn.python.ops.core_rnn_cell import _linear from tensorflow.contrib.rnn.python.ops.core_rnn_cell import array_ops from tensorflow.contrib.rnn.python.ops.core_rnn_cell import RNNCell tf.reset_default_graph() def ln(tensor,scope=None,epsilon=1e-5): ‘‘‘ 沿着第二个轴层归一化二维张量tensor(按行求平均,方差) 这里其实是对每个样本进行归一化处理 计算每个样本的方差和均值然后归一化处理 并不是批归一化 args: tensor:输入张量,二维 大小为batch_size x num_units scope:命名空间 epsilon:为了防止除数为0 ‘‘‘ assert(len(tensor.get_shape()) == 2) #沿着axis=1轴(即每个样本),计算输入张量的均值和方差 大小均为batch_size x 1 m,v = tf.nn.moments(tensor,axes = 1,keep_dims=True) if not isinstance(scope,str): scope = ‘‘ #获取共享变量 不存在则创建 with tf.variable_scope(scope+‘layer_norm‘): #获取缩放比例 scale = tf.get_variable(name=‘scale‘,shape=[tensor.get_shape()[1]],initializer=tf.constant_initializer(1)) #获取偏移量 shift = tf.get_variable(name=‘shift‘,shape=[tensor.get_shape()[1]],initializer=tf.constant_initializer(0)) #归一化处理 xi_bar = (xi - μ)/sqrt(ε + σ^2) ln_initial = (tensor - m)/tf.sqrt(v+epsilon) #yi = γ*xi_bar + β return ln_initial*scale + shift class LNGRUCell(RNNCell): ‘‘‘ 创建GRU单元的类 使用了层归一化 ‘‘‘ def __init__(self,num_units,input_size=None,activation=tf.nn.tanh): ‘‘‘ args: num_units:隐藏层节点个数 ‘‘‘ if input_size is not None: print(‘%s:The input_size parameter is deprecates.‘%self) self.__num_units = num_units self.__activation = activation @property def state_size(self): return self.__num_units @property def output_size(self): return self.__num_units def __call__(self,inputs,state): ‘‘‘ args: inputs:这个时序的输入xt batch_size x n_inputs state:上一个时序的输出ht_1 num_units x num_units ‘‘‘ with tf.variable_scope(‘Gates‘): ‘‘‘ args: a 2D Tensor or a list of 2D, batch x n, Tensors. output_size: int, second dimension of W[i]. bias: boolean, whether to add a bias term or not. bias_initializer: starting value to initialize the bias (default is all zeros). Returns: A 2D Tensor with shape [batch x output_size] equal to sum_i(args[i] * W[i]), where W[i]s are newly created matrices. ‘‘‘ #计算加权值[Wz.[xt,ht_1]+bias,Wr.[xt,ht_1]+bias] 在计算的时候输入x在前权重w在后 #即[batch_size x (n_inputs+num_units)] x [(n_inputs+num_units) x output_size] #print(‘inputs:‘,inputs.shape) #inputs: (?, 28) #print(‘state:‘,state.shape) #state: (?, 128) # batch_size x (2*__num_units) value = _linear([inputs,state],output_size=2*self.__num_units,bias=True,bias_initializer=tf.constant_initializer(1.0)) #分割成两份 每份大小batch_size x __num_units r,u = array_ops.split(value=value,num_or_size_splits=2,axis=1) #层归一化 r = ln(r,scope=‘r/‘) #层归一化 u = ln(u,scope=‘u/‘) #计算rt,zt 大小均为大小batch_size x __num_units r,u = tf.nn.sigmoid(r),tf.nn.sigmoid(u) with tf.variable_scope(‘Candidate‘): #计算加权值W.[xt,rt*ht_1] 大小batch_size x __num_units Cand = _linear([inputs,r*state],self.__num_units,True) #层归一化 c_pre = ln(Cand,scope=‘new_h/‘) #计算ht_hat 大小batch_size x __num_units c = self.__activation(c_pre) #zt*ht_1 + (1-zt)*ht_hat 大小batch_size x __num_units new_h = u * state + (1 - u) * c return new_h,new_h def single_layer_static_gru(input_x,n_steps,n_hidden): ‘‘‘ 返回静态单层GRU单元的输出,以及cell状态 args: input_x:输入张量 形状为[batch_size,n_steps,n_input] n_steps:时序总数 n_hidden:gru单元输出的节点个数 即隐藏层节点数 ‘‘‘ #把输入input_x按列拆分,并返回一个有n_steps个张量组成的list 如batch_sizex28x28的输入拆成[(batch_size,28),((batch_size,28))....] #如果是调用的是静态rnn函数,需要这一步处理 即相当于把序列作为第一维度 input_x1 = tf.unstack(input_x,num=n_steps,axis=1) #可以看做隐藏层 gru_cell = LNGRUCell(num_units=n_hidden) #静态rnn函数传入的是一个张量list 每一个元素都是一个(batch_size,n_input)大小的张量 hiddens,states = tf.contrib.rnn.static_rnn(cell=gru_cell,inputs=input_x1,dtype=tf.float32) return hiddens,states def mnist_rnn_classfication(): ‘‘‘ 1. 导入数据集 ‘‘‘ tf.reset_default_graph() from tensorflow.examples.tutorials.mnist import input_data #mnist是一个轻量级的类,它以numpy数组的形式存储着训练,校验,测试数据集 one_hot表示输出二值化后的10维 mnist = input_data.read_data_sets(‘MNIST-data‘,one_hot=True) print(type(mnist)) #<class ‘tensorflow.contrib.learn.python.learn.datasets.base.Datasets‘> print(‘Training data shape:‘,mnist.train.images.shape) #Training data shape: (55000, 784) print(‘Test data shape:‘,mnist.test.images.shape) #Test data shape: (10000, 784) print(‘Validation data shape:‘,mnist.validation.images.shape) #Validation data shape: (5000, 784) print(‘Training label shape:‘,mnist.train.labels.shape) #Training label shape: (55000, 10) ‘‘‘ 2 定义参数,以及网络结构 ‘‘‘ n_input = 28 #LSTM单元输入节点的个数 n_steps = 28 #序列长度 n_hidden = 128 #LSTM单元输出节点个数(即隐藏层个数) n_classes = 10 #类别 batch_size = 128 #小批量大小 training_step = 5000 #迭代次数 display_step = 200 #显示步数 learning_rate = 1e-4 #学习率 #定义占位符 #batch_size:表示一次的批次样本数量batch_size n_steps:表示时间序列总数 n_input:表示一个时序具体的数据长度 即一共28个时序,一个时序送入28个数据进入LSTM网络 input_x = tf.placeholder(dtype=tf.float32,shape=[None,n_steps,n_input]) input_y = tf.placeholder(dtype=tf.float32,shape=[None,n_classes]) #可以看做隐藏层 hiddens,states = single_layer_static_gru(input_x,n_steps,n_hidden) print(‘hidden:‘,hiddens[-1].shape) #(128,128) #取LSTM最后一个时序的输出,然后经过全连接网络得到输出值 output = tf.contrib.layers.fully_connected(inputs=hiddens[-1],num_outputs=n_classes,activation_fn = tf.nn.softmax) ‘‘‘ 3 设置对数似然损失函数 ‘‘‘ #代价函数 J =-(Σy.logaL)/n .表示逐元素乘 cost = tf.reduce_mean(-tf.reduce_sum(input_y*tf.log(output),axis=1)) ‘‘‘ 4 求解 ‘‘‘ train = tf.train.AdamOptimizer(learning_rate).minimize(cost) #预测结果评估 #tf.argmax(output,1) 按行统计最大值得索引 correct = tf.equal(tf.argmax(output,1),tf.argmax(input_y,1)) #返回一个数组 表示统计预测正确或者错误 accuracy = tf.reduce_mean(tf.cast(correct,tf.float32)) #求准确率 #创建list 保存每一迭代的结果 test_accuracy_list = [] test_cost_list=[] with tf.Session() as sess: #使用会话执行图 sess.run(tf.global_variables_initializer()) #初始化变量 #开始迭代 使用Adam优化的随机梯度下降法 for i in range(training_step): x_batch,y_batch = mnist.train.next_batch(batch_size = batch_size) #Reshape data to get 28 seq of 28 elements x_batch = x_batch.reshape([-1,n_steps,n_input]) #开始训练 train.run(feed_dict={input_x:x_batch,input_y:y_batch}) if (i+1) % display_step == 0: #输出训练集准确率 training_accuracy,training_cost = sess.run([accuracy,cost],feed_dict={input_x:x_batch,input_y:y_batch}) print(‘Step {0}:Training set accuracy {1},cost {2}.‘.format(i+1,training_accuracy,training_cost)) #全部训练完成做测试 分成200次,一次测试50个样本 #输出测试机准确率 如果一次性全部做测试,内容不够用会出现OOM错误。所以测试时选取比较小的mini_batch来测试 for i in range(200): x_batch,y_batch = mnist.test.next_batch(batch_size = 50) #Reshape data to get 28 seq of 28 elements x_batch = x_batch.reshape([-1,n_steps,n_input]) test_accuracy,test_cost = sess.run([accuracy,cost],feed_dict={input_x:x_batch,input_y:y_batch}) test_accuracy_list.append(test_accuracy) test_cost_list.append(test_cost) if (i+1)% 20 == 0: print(‘Step {0}:Test set accuracy {1},cost {2}.‘.format(i+1,test_accuracy,test_cost)) print(‘Test accuracy:‘,np.mean(test_accuracy_list)) if __name__ == ‘__main__‘: mnist_rnn_classfication()
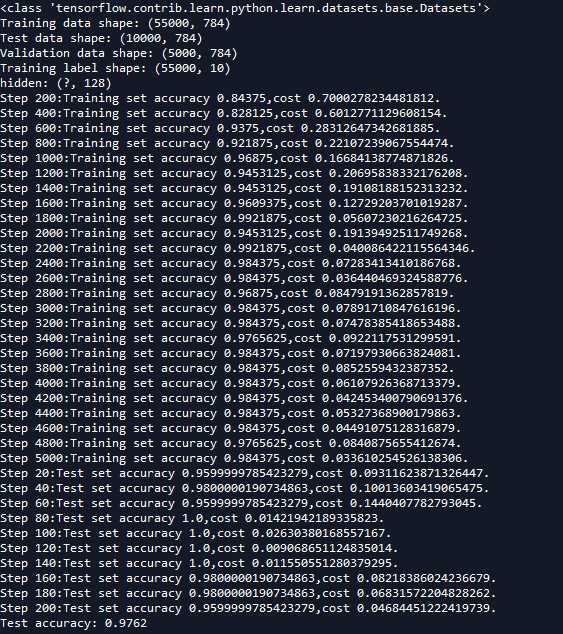
我们可以最后的测试集准确率达到了97.62%,比上一节96.46%提升了不少。本例只是使用了一个GRUCell,在多个cell中LN的效果会更明显些。
CTC(Connectionist Temporan Classification)是语音辨识中的一个关键技术,通过增减一个额外的Symbol代表NULL来解决叠字问题。
RNN的优势在于处理连续的数据,在基于连续的时间序列分类任务中,常常会使用CTC的方法。
该方法主要体现在loss值处理上,通过对序列对不上的label添加blank(空label)的方式,将预测的输出值与给定的label值在时间序列上对齐,通过交叉熵算法求出具体损失值。
比如在语音识别的例子中,对于一句语音有它的序列值与对应的文本,可以使用CTC的损失函数求出模型输出和label之间的loss,再通过优化器的迭代训练让损失值变小的方式将模型训练出来。
TensorFlow中提供了一个ctc_loss函数,其作用就是按照序列来处理输出标签和标准标签之间的损失。因为也是成型的函数封装,对于初学者内部实现不用花太多时间关注,只要会用即可。
def tf.nn.ctc_loss(labels, inputs, sequence_length, preprocess_collapse_repeated=False, ctc_merge_repeated=True, ignore_longer_outputs_than_inputs=False, time_major=True):
labels: An `int32` `SparseTensor`.`labels.indices[i, :] == [b, t]` means `labels.values[i]` stores the id for (batch b, time t).`labels.values[i]` must take on values in `[0, num_labels)`.See `core/ops/ctc_ops.cc` for more details.一个32位的系数矩阵张量(SparseTensor)
inputs: 3-D `float` `Tensor`.If time_major == False, this will be a `Tensor` shaped:`[batch_size , max_time , num_classes]`. If time_major == True (default), this will be a `Tensor` shaped: `[max_time, batch_size , num_classes]`.The logits。(常用变量logits表示),经过RNN后输出的标签预测值,三维的浮点型张量,当time_major为False时形状为[batch_size,max_time,num_classes],否则为[max_time, batch_size , num_classes](默认值)。
sequence_length: 1-D `int32` vector, size `[batch_size]`.The sequence lengths.序列长度。
preprocess_collapse_repeated: Boolean. Default: False.If True, repeated labels are collapsed prior to the CTC calculation.是否需要预处理,将重复的label合并成一个label,默认是False.
ctc_merge_repeated: Boolean. Default: True.在计算时是否将每个non_blank(非空)重复的label当成单独label来解释,默认是True。
ignore_longer_outputs_than_inputs: Boolean. Default: False.If True, sequences with longer outputs than inputs will be ignored.
time_major: The shape format of the `inputs` Tensors.If True, these `Tensors` must be shaped `[max_time, batch_size, num_classes]`.If False, these `Tensors` must be shaped `[batch_size, max_time, num_classes]`.Using `time_major = True` (default) is a bit more efficient because it avoids transposes at the beginning of the ctc_loss calculation. However, most TensorFlow data is batch-major, so by this function also accepts inputs in batch-major form.决定inputs的数据格式。
对于preprocess_collapse_repeated与ctc_merge_repeated参数,都是对于ctc_loss中重复标签处理的控制,各种情况组合如下表所示:
| 参数情况 | 说明 |
|
preprocess_collapse_repeated=True ctc_merge_repeated=True |
忽略全部重复标签,只计算不重复的标签 |
|
preprocess_collapse_repeated=False ctc_merge_repeated=True |
标准的CTC模式,也是默认模式,不做预处理,只运算时重复标签不再当成独立的标签来计算 |
|
preprocess_collapse_repeated=True ctc_merge_repeated=False |
忽略全部重复标签,只计算不重复的标签,因为预处理时已经把重复的标签去掉了 |
|
preprocess_collapse_repeated=False ctc_merge_repeated=False |
所有重复标签都会参加计算 |
对于ctc_loss的返回值,仍然属于loss的计算模式,当取批次样本进行训练时,同样也需要对最终的ctc_loss求均值。
return A 1-D `float` `Tensor`, size `[batch]`, containing the negative log probabilities.
注意:对于重复标签方面的ctc_loss计算,一般情况下默认即可。另外这里有个隐含的规则,Inputs中的classes是指需要输出多少类,在使用ctc_loss时,需要将clsses+1,即再多生成一个类,用于存放blank。因为输入的序列与label并不是一一对应的,所以需要通过添加blank类,当对应不上时,最后的softmax就会将其生成到blank。具体做法就是在最后的输出层多构建一个节点即可。
这个规则是ctc_loss内置的,否则当标准标签label中的类索引等于Inputs中size-1时会报错。
前面提到了SparseTensor类型,这里主要介绍一下。
首先介绍下稀疏矩阵,它是相对于密集矩阵而言的。
密集矩阵就是我们常见的矩阵。当密度矩阵中大部分的数都为0时,就可以使用一种更好的存储方式(只是将矩阵中不为0的索引和值记录下来)存储。这种方式就可以大大节省内存控件,它就是"稀疏矩阵"。
稀疏矩阵在TensorFlow中的结构类型如下:
def tf.SparseTensor(indices, values, dense_shape):
了解了SpareTensor类型之后,就可以按照参数来拼接出一个SpareTensor了。在实际应用中,常会用到需要将密集矩阵dense转换成稀疏矩阵SparseTensor。代码如下:
def dense_to_sparse(dense,dtype=np.int32): ‘‘‘ 把密集矩阵转换为稀疏矩阵 args: dense:密集矩阵 dtype:稀疏矩阵值得类型 ‘‘‘ indices = [] values = [] #遍历每一行 for n,seq in enumerate(dense): #在已存在的列表中添加新的列表内容 添加密集矩阵每个索引位置 indices.extend(zip([n]*len(seq),range(len(seq)))) #添加密集矩阵每个元素的值 values.extend(seq) #print(‘n {0} ,seq {1} ,indices {2},values {3}‘.format(n,seq,indices,values)) indices = np.asarray(indices,dtype = np.int64) values = np.asarray(values,dtype = dtype) shape = np.asarray([len(dense),indices.max(0)[1]+1],dtype = np.int64) return tf.SparseTensor(indices = indices,values = values,dense_shape = shape)
TensorFlow中提供了一个这样的函数:
def tf.sparse_tensor_to_dense(sp_input, default_value=0, validate_indices=True, name=None):
sp_input:一个SparseTensor。
default_value:没有指定索引的对应的默认值,默认是0。
前面介绍了ctc_loss是用来训练时间序列分类模型的。评估模型时,一般常使用计算得到的levenshtein距离值作为模型的评分(正确率或错误率)。
levenshtein距离又叫编辑距离(Edit Distance),是指两个字符串之间,由一个转成另一个所需的最小编辑操作次数。许可的编辑操作包括:将一个字符串替换成另一个字符、插入一个字符、删除一个字符。一般来说,编辑距离越小,两个字符串的相似度越大。
这种方法应用非常广泛,在全序列对比,局部序列对比中都会用到,例如语音识别,拼音纠错,DNA对比等。
在TensorFlow中,levenshtein距离的处理被封装成对两个稀疏矩阵进行操作,定义如下:
def tf.edit_distance(hypothesis, truth, normalize=True, name="edit_distance"):
返回一个R-1维的密度矩阵,包含每个序列的levenshtein距离。R是输入序列hypothesis的秩。
CTC结构中海油一个重要的环节就是CTCdecoder。
虽然在输入ctc_loss中的logits(inputs)是我们的预测结果,但却是带有空标签的,而且是一个与时间序列强对应的输出。在实际情况下,我们需要转换好的类似于原始标准标签的疏忽从。这时可以使用CTCdecoder,经过它对预测结果加工后,就可以与标准标签进行损失值得运算了。
在TensorFLow中,提供了两个函数。
def tf.nn.ctc_greedy_decoder(inputs, sequence_length, merge_repeated=True):
返回值:tuple(decoded,neg_sum_logits):
decoded: A single-element list. `decoded[0]` is an `SparseTensor` containing the decoded outputs s.t.:
`decoded.indices`: Indices matrix `(total_decoded_outputs x 2)`. The rows store: `[batch, time]`.
`decoded.values`: Values vector, size `(total_decoded_outputs)`. The vector stores the decoded classes.
`decoded.shape`: Shape vector, size `(2)`. The shape values are: `[batch_size, max_decoded_length]`
neg_sum_logits: A `float` matrix `(batch_size x 1)` containing, for the sequence found, the negative of the sum of the greatest logit at each timeframe.
def tf.nn.ctc_beam_search_decoder(inputs, sequence_length, beam_width=100, top_paths=1, merge_repeated=True):
另外一种寻路策略,参数和上面那个函数大致一样。
注意:在实际情况下,解码完后的decoded是一个list,不能直接用,通常取decoded[0],然后转换成密集矩阵,得到的是一个批次的结果,然后再一条一条地取到没一个样本的结果。
第二十二节,TensorFlow中RNN实现一些其它知识补充
标签:article 字符 equal 检查 保存 偏移量 glob elements sea
原文地址:https://www.cnblogs.com/zyly/p/9050400.html