标签:nta puppeteer href table click png black local 介绍
本文以一个示例简单的介绍一下puppeteer的用法,我们的目的是:获取我博客上的文章的前十页的所有随笔的标题和链接。由于puppeteer本身是自动化chorme,因此这里我们的步骤和手动操作浏览器差不多:
获取信息
采集过程中比较麻烦的一步就是信息的采集,和传统采集html后解析的方式不同的时,由于chrome本身有完整的js引擎,因此我们采用注入一段js,利用该js采集到我们的信息,并通过puppeteer返回给应用程序的方式。由于puppete本身是采用的chrome,因此编写采集信息函数这一过程完全可以在chrome上进行。
首先用chrome打开我的博客的首页http://www.cnblogs.com/TianFang/,打开chrome devtool,获取标题的css path。然后我们可以利用chrome的snippets简单的写一个获取所有标题信息的函数:
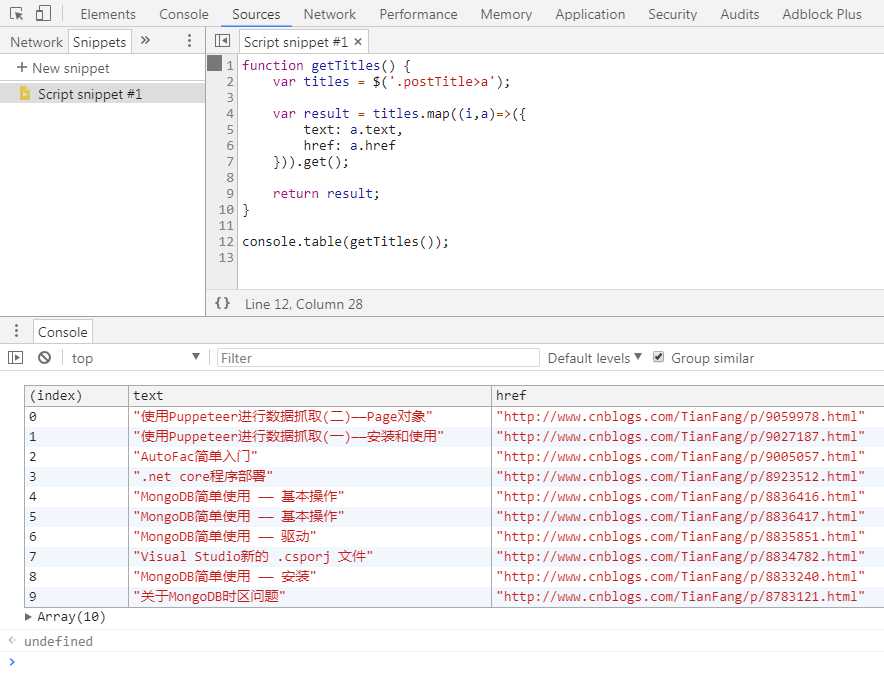
本身就蜘蛛程序而言,编写获取脚本内容的这个部分是比较繁琐的,需要不断的反复调试。但使用snippets直接编写函数大大简化了这一过程,它的主要好处有:
然后我们只需要将这个函数放到node中,利用puppeteer跳转到相应的页面,使用page.evaluate函数执行这个函数即可。
async function getTitles() {
var titles = $(‘.postTitle>a‘);
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
var titles = await page.evaluate(getTitles);
console.log(titles);
一个需要注意的地方是,这个函数实际上是在chrome中执行的,puppeteer要求在chrome中执行的函数必须是异步的,因此需要加上async关键字。
页面跳转
下一步需要解决的问题就是如何跳转到下一页了。方法也比较简单:分析一下页面,找到下一页的连接,执行js模拟点击即可:
page.evaluate(async() => $(`a:contains(‘下一页‘)`)[0].click());
完整代码如下:
const puppeteer = require(‘puppeteer‘);
const chrome_exe = String.raw`${process.env["ProgramFiles(x86)"]}\Google\Chrome\Application\chrome.exe`;
const user_data_path = String.raw`${process.env.LocalAppData}\Google\Chrome\User Data\Default`;
async function run() {
const browser = await puppeteer.launch({
headless: false,
userDataDir: user_data_path,
executablePath: chrome_exe
});
const page = await browser.newPage();
page.setViewport({ width: 1600, height: 900 });
await page.goto(‘http://www.cnblogs.com/TianFang‘);
for (var i = 0; i < 10; i++) {
console.log(i);
console.log(page.url());
var titles = await page.evaluate(getTitles);
console.log(titles);
await page.evaluate(async() => $(`a:contains(‘下一页‘)`)[0].click());
await page.waitForNavigation();
await sleep(1000);
}
};
async function getTitles() {
var titles = $(‘.postTitle>a‘);
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
run();
整个过程还是非常简单的, 执行结果如下:
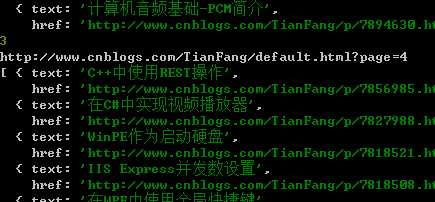
另外值得一提的是,细心的朋友可能注意到这里我们编写一个可以await的sleep函数。
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
这个函数本身不是必须的,但在编写蜘蛛程序过程中却经常需要等待的,使用await异步等待可以大大提高代码的可读性,由于node本身没有提供可以await的sleep函数。并且这个函数非常实用,这里就自己实现了一个,记录一下,以备以后使用。
标签:nta puppeteer href table click png black local 介绍
原文地址:https://www.cnblogs.com/TianFang/p/9060309.html