标签:style blog http io 使用 ar strong for 文件
数据挖掘(Data Mining)又称知识库知识发现(Knowledge-Discovery in Databases 简称KDD)。
1.什么是DM?(what?)
简单点说,DM就是从海量数据中找到有价值的知识,这些知识可以是规则、约束、模式、规律等等。 这些知识可以使用图表,决策树,关联表等进行表示说明。
说到DM,感觉就应该说到数据库技术的发展。我们知道数据库技术从1960年代的简单收集数据到DBMS、关系型数据库等,一路发展过来的,也正是由于数据库技术的不断发展才会为DM的出现打下基础。
2.为什么会有DM?(why?)
主要是因为数据爆炸问题。当前由于数据收集和数据存储技术的快速发展使得各组织机构可以获得并积累海量的数据,比如google、facebook等,它们每天产生的数据量非常海量,然而利用传统的数据分析方法从这些海量数据中提取有用信息却是很有挑战,因此就衍生出数据挖掘这个概念。因此我们也可以这么认为,数据挖掘是一门技术,它将传统的的数据分析方法和处理大规模数据的复杂算法结合起来。
有一句话说的好:“我们淹没于数据中,却渴望得到知识”
3.在哪里使用了DM?(where?)
首先简单说明一下数据挖掘的一些技术:
1)关联规律的发现:Aprior算法
2)聚类分析:无师自同,训练数据没有类别标签
3)模型分类:举一反三,训练数据有类别标签,有监督学习。
4)异常检测:识别其特征明显不同于其他数据的观测值,寻找异常点或者离群点。
5)数据立方体,可视化等等。
简单说明几个应用:
1)customer Relationship Management(CRM) ---------客户关联规则,比如用于购物的推荐这些
2)web Analysis-------web网页的内在次序问题,google的网页搜索
3)图像识别----分类问题
4)Bioinformatics—序列模式,蛋白质,基因序列的预测分类等
一般来说应用的不同,它们挖掘的数据类型也会是不同的。数据类型的不同也就导致我们采用不同的数据挖掘技术来分析数据。我们知道现在的数据类型不同与以往,现在的数据类型多种多样:
有结构化的:如存储在数据库中的数据,这些数据之间的关系明确,易于分析
半结构化的:如xml数据,数据的结构也是可以看得出来的,就是没有那么明显而已
无结构化的:如文本文件,web网页内容,视频流等,数据之间的关系没有明确的结构,难以用于分析处理。
数据的收集技术的发展的导致了大量的以序列,图,数等形式出现的高维复杂数据,因此对大规模的高维复杂的数据进行分析是很重要的一个任务。
4.数据挖掘流程:
知识发现过程: 数据清理--数据仓库--数据选择--数据挖掘--知识(数据预处理、数据挖掘、结果分析)
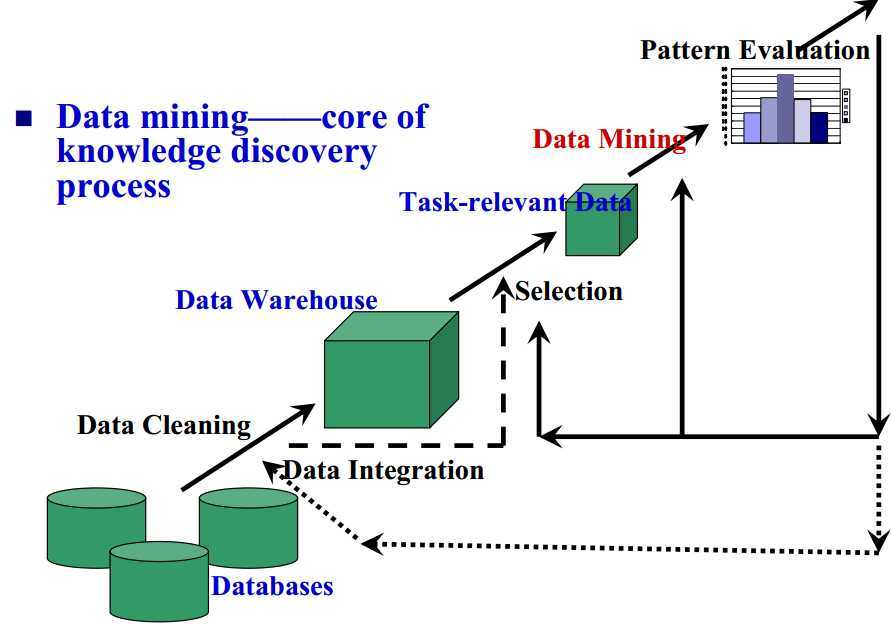
5.数据挖掘理论:
数据挖掘是一门交叉学科,包括信息检索、统计学、机器学习、数据压缩,信息论等等。。
标签:style blog http io 使用 ar strong for 文件
原文地址:http://www.cnblogs.com/GuoJiaSheng/p/3995555.html