标签:enc 分割线 帐号 lse 方式 ram script 文件名 help



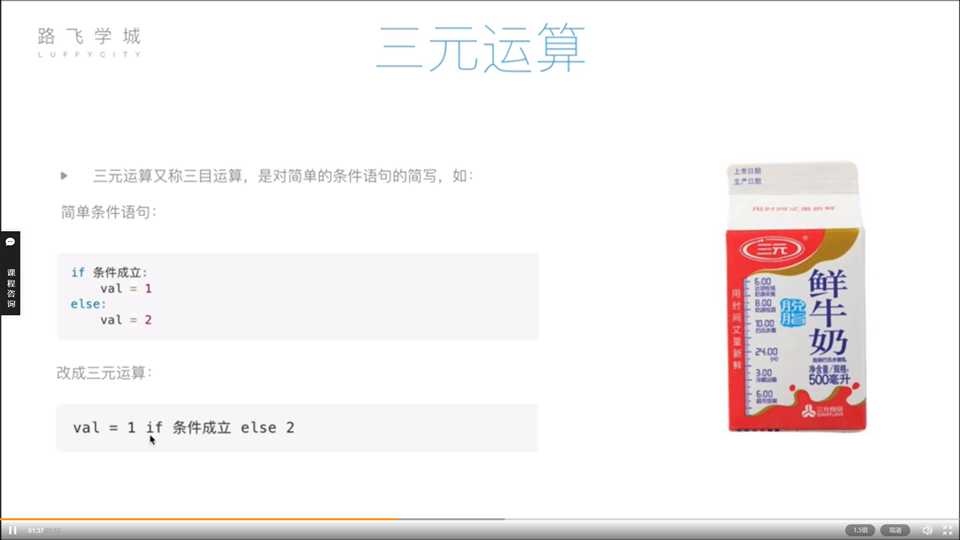
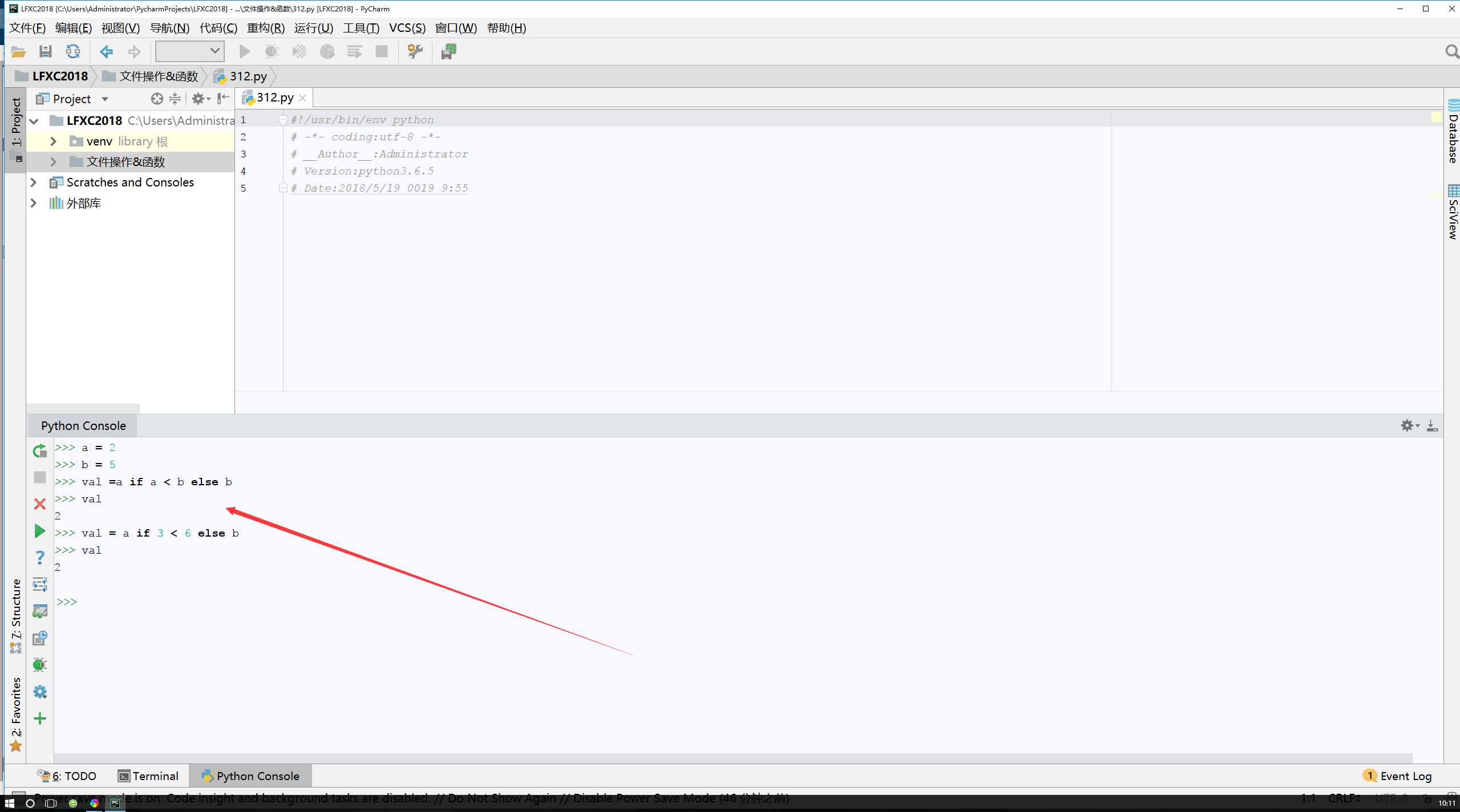
三元运算又称“三目运算”,是对简单条件语句的简写,如:

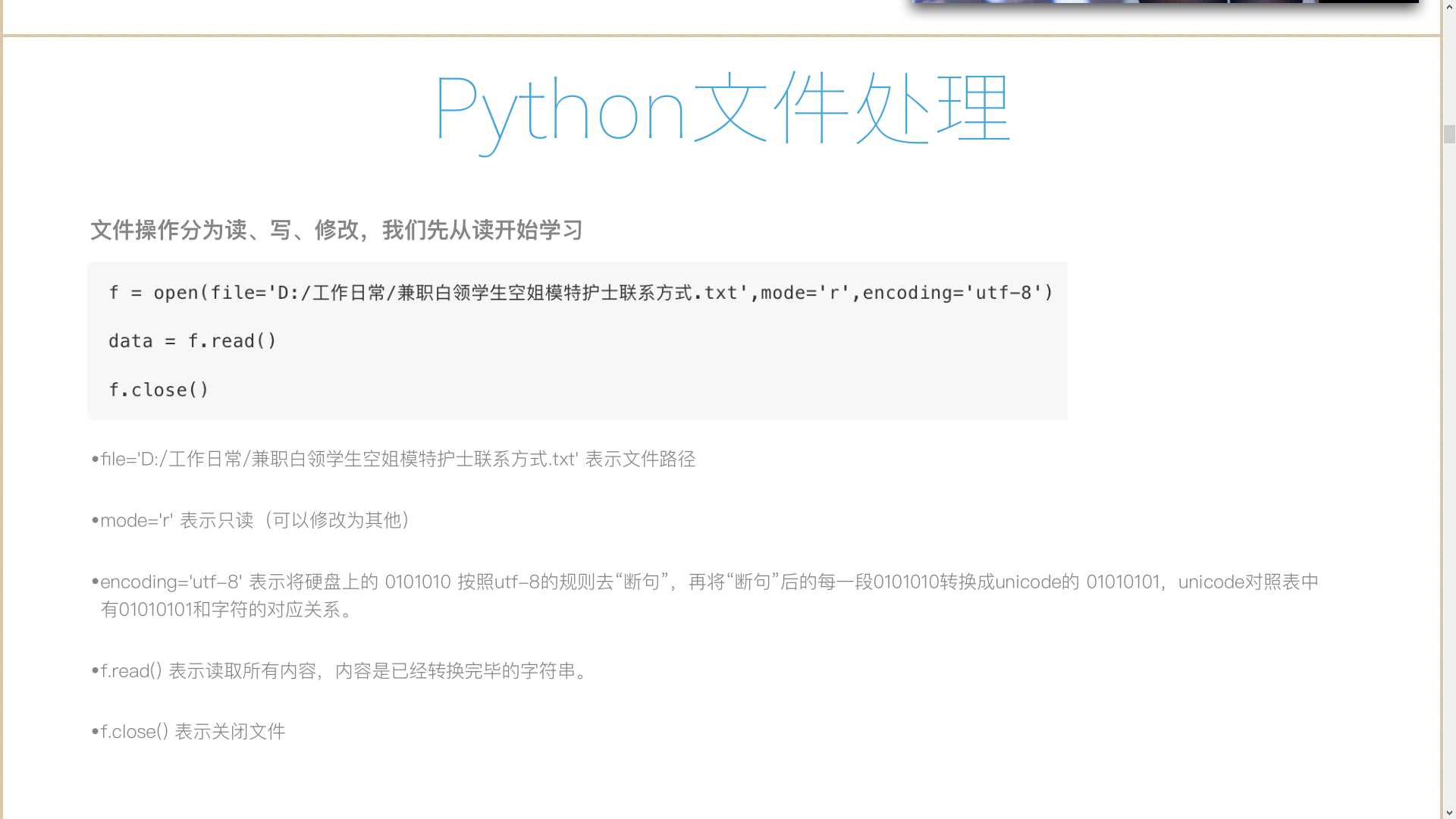
1)读;
1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/14 21:57 5 #f = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘r‘)#UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xaf in position 9: illegal multibyte sequence 6 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘r‘,encoding=‘utf-8‘)#打开文件; 7 file_data = file.read()#阅读文件内容; 8 print(file_data)#打印文件内容; 9 file.close()#一定要关闭文件;
总结:以什么编码存储文件,一定要使用相同的编码打开;
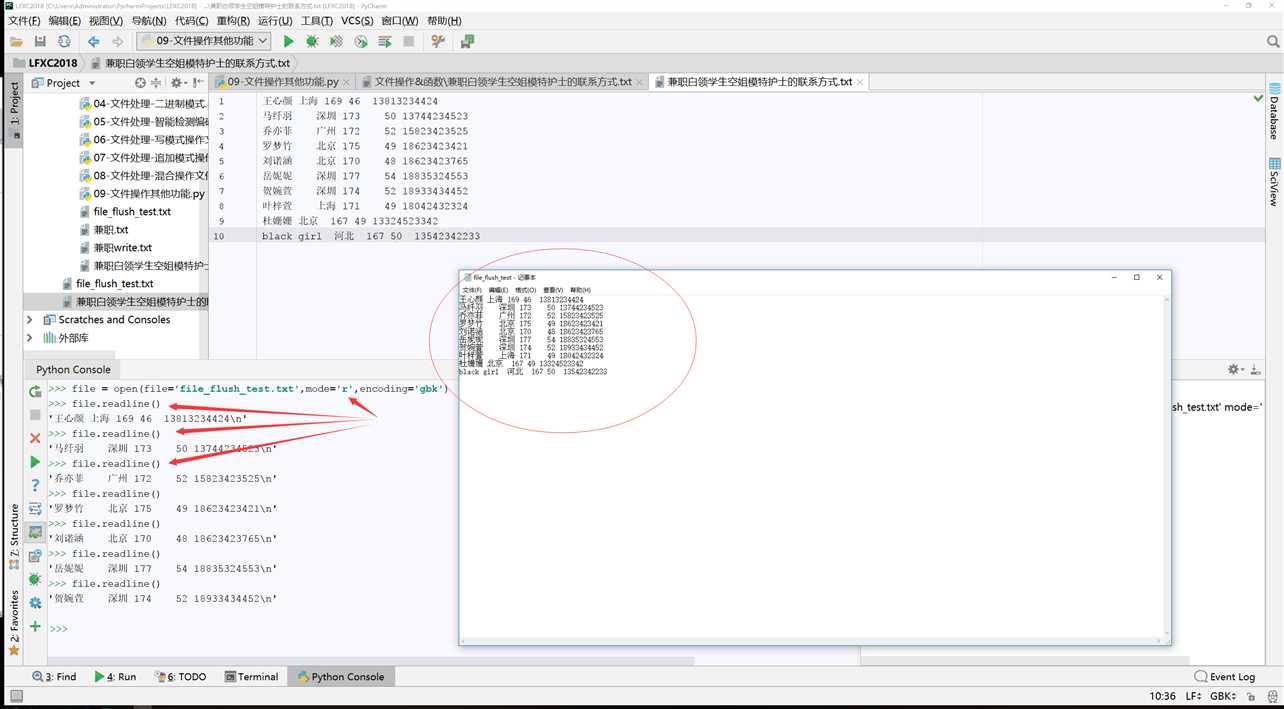
兼职白领学生空姐模特护士的联系方式.txt
王心颜 上海 169 46 13813234424
马纤羽 深圳 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
black girl 河北 167 50 13542342233
1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/14 22:22 5 # E-Mail: tqtl911@163.com 6 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘rb‘)#b是binary的缩写,以二进制的形式打开文件,用于网络传输,给机器看,适用于不知道文件编码格式的场景; 7 file_data = file.read()#阅读文件内容; 8 print(file_data)#打印文件内容; 9 file.close()#一定要关闭文件;
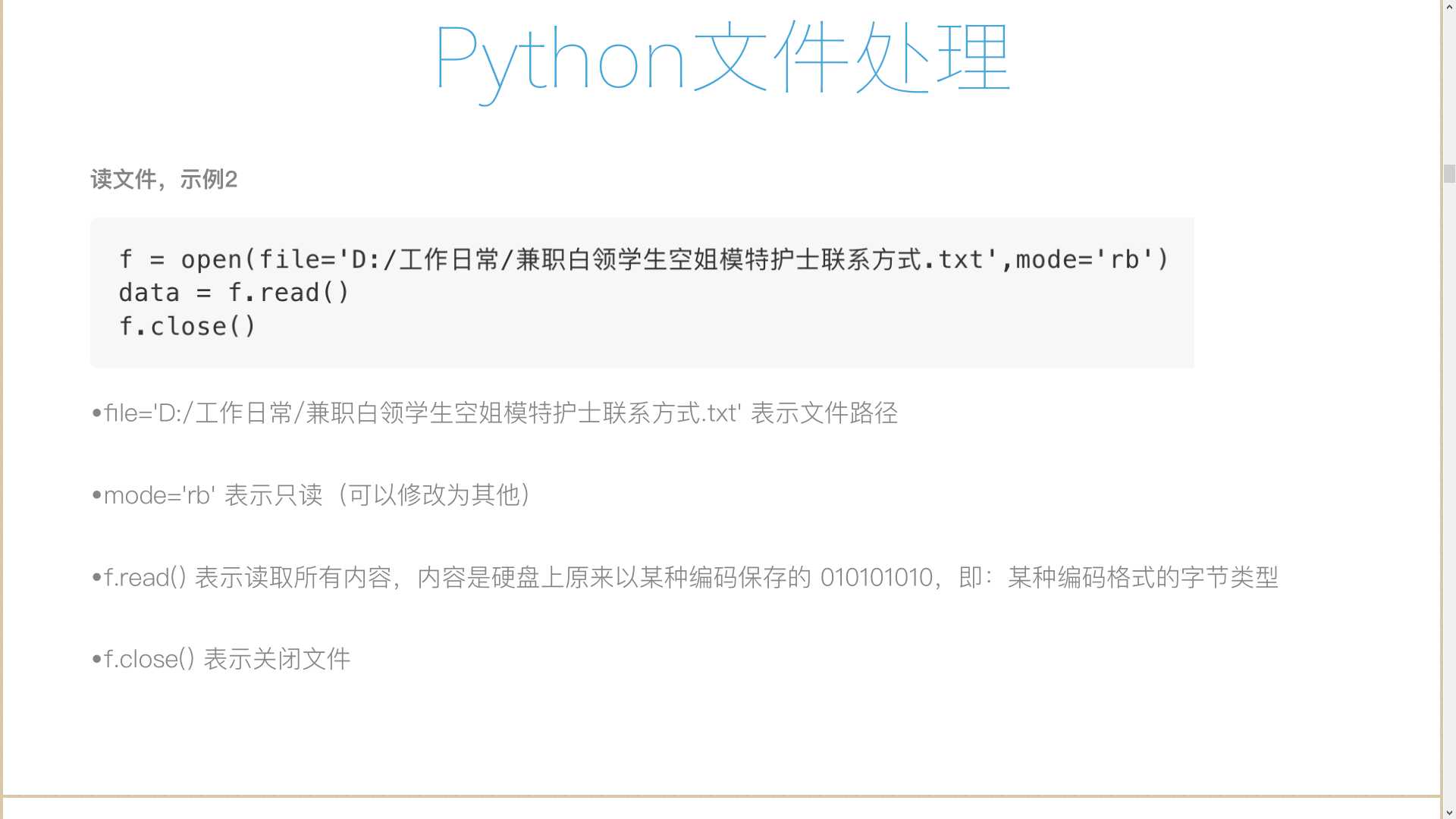
1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/14 22:36 5 # E-Mail: tqtl911@163.com 6 # Wechat:cxz19930911 7 #pip 安装第三方模块chardet,类似于yum安装第三方软件; 8 9 import chardet 10 f = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘rb‘) 11 data = f.read() 12 print(data) 13 f.close() 14 print(chardet.detect(data))#{‘encoding‘: ‘utf-8‘, ‘confidence‘: 0.99, ‘language‘: ‘‘}
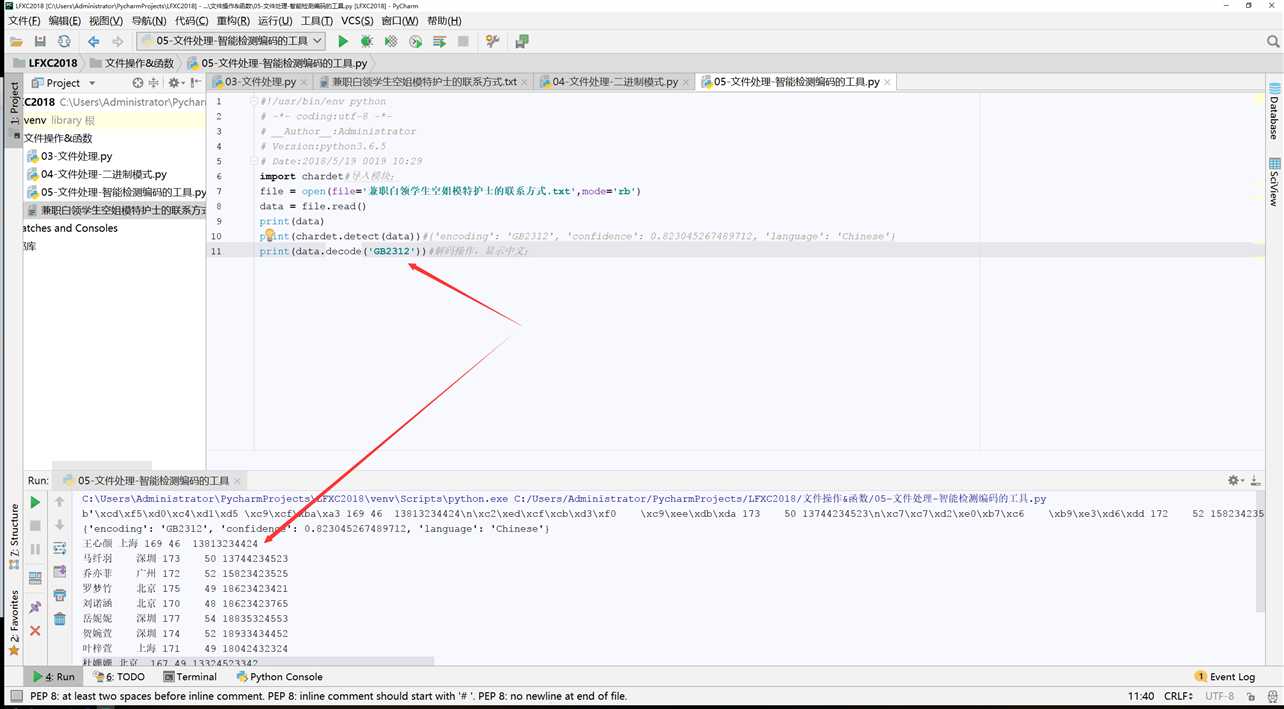
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # __Author__:Administrator 4 # Version:python3.6.5 5 # Date:2018/5/19 0019 10:29 6 import chardet#导入模块; 7 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘rb‘) 8 data = file.read() 9 print(data) 10 print(chardet.detect(data))#{‘encoding‘: ‘GB2312‘, ‘confidence‘: 0.823045267489712, ‘language‘: ‘Chinese‘} 11 print(data.decode(‘GB2312‘))#解码操作,显示中文;

1 C:\Users\Administrator\PycharmProjects\LFXC2018\venv\Scripts\python.exe C:/Users/Administrator/PycharmProjects/LFXC2018/文件操作&函数/05-文件处理-智能检测编码的工具.py 2 b‘\xcd\xf5\xd0\xc4\xd1\xd5 \xc9\xcf\xba\xa3 169 46 13813234424\n\xc2\xed\xcf\xcb\xd3\xf0 \xc9\xee\xdb\xda 173 50 13744234523\n\xc7\xc7\xd2\xe0\xb7\xc6 \xb9\xe3\xd6\xdd 172 52 15823423525\n\xc2\xde\xc3\xce\xd6\xf1 \xb1\xb1\xbe\xa9 175 49 18623423421\n\xc1\xf5\xc5\xb5\xba\xad \xb1\xb1\xbe\xa9 170 48 18623423765\n\xd4\xc0\xc4\xdd\xc4\xdd \xc9\xee\xdb\xda 177 54 18835324553\n\xba\xd8\xcd\xf1\xdd\xe6 \xc9\xee\xdb\xda 174 52 18933434452\n\xd2\xb6\xe8\xf7\xdd\xe6 \xc9\xcf\xba\xa3 171 49 18042432324\n\xb6\xc5\xe6\xa9\xe6\xa9 \xb1\xb1\xbe\xa9 167 49 13324523342\nblack girl \xba\xd3\xb1\xb1 167 50 13542342233‘ 3 {‘encoding‘: ‘GB2312‘, ‘confidence‘: 0.823045267489712, ‘language‘: ‘Chinese‘} 4 王心颜 上海 169 46 13813234424 5 马纤羽 深圳 173 50 13744234523 6 乔亦菲 广州 172 52 15823423525 7 罗梦竹 北京 175 49 18623423421 8 刘诺涵 北京 170 48 18623423765 9 岳妮妮 深圳 177 54 18835324553 10 贺婉萱 深圳 174 52 18933434452 11 叶梓萱 上海 171 49 18042432324 12 杜姗姗 北京 167 49 13324523342 13 black girl 河北 167 50 13542342233
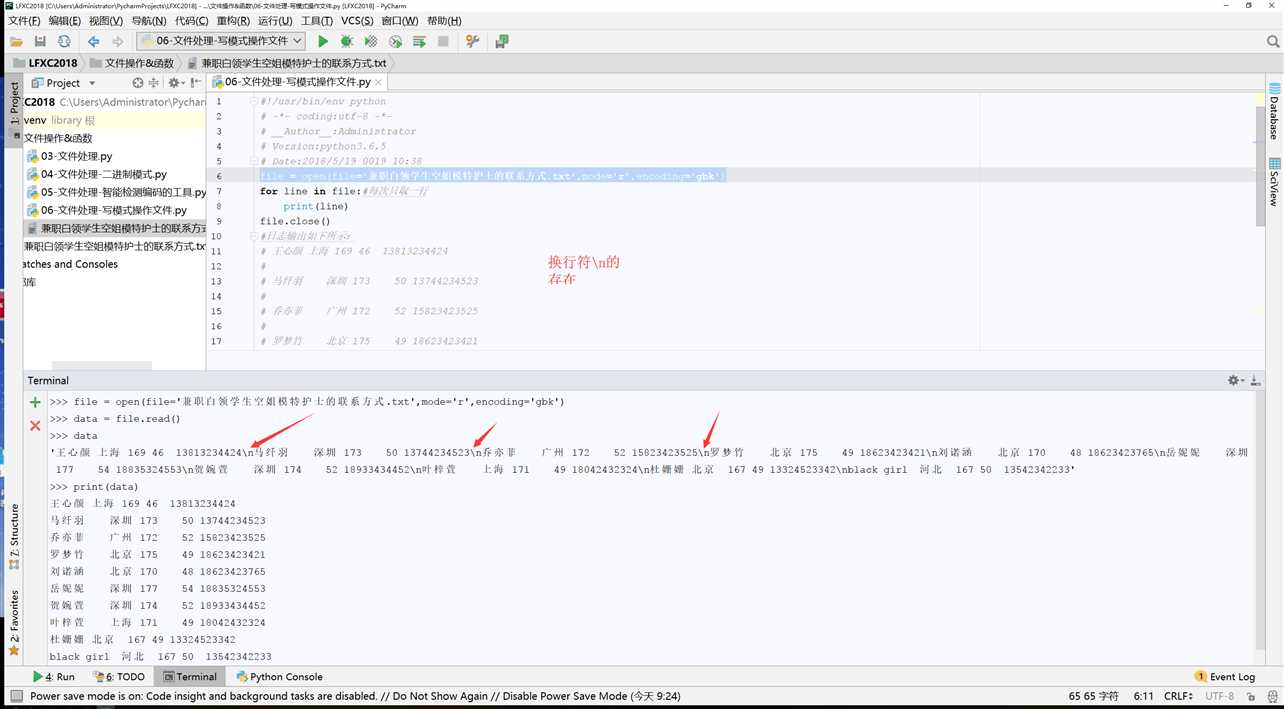
1 #! /usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #__author__ = "tqtl" 4 # Date:2018/5/14 23:04 5 # E-Mail: tqtl911@163.com 6 # Wechat:cxz19930911 7 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘r‘,encoding=‘utf-8‘) 8 for lines in file: 9 print(lines) 10 file.close() 11 # 王心颜 上海 169 46 13813234424 12 # 13 # 马纤羽 深圳 173 50 13744234523 14 # 15 # 乔亦菲 广州 172 52 15823423525 16 # 17 # 罗梦竹 北京 175 49 18623423421 18 # 19 # 刘诺涵 北京 170 48 18623423765 20 # 21 # 岳妮妮 深圳 177 54 18835324553 22 # 23 # 贺婉萱 深圳 174 52 18933434452 24 # 25 # 叶梓萱 上海 171 49 18042432324 26 # 27 # 杜姗姗 北京 167 49 13324523342 28 # 29 # black girl 河北 167 50 13542342233 30 #为什么会有空行,如何消除文件之间的空行?! 31 #No.1文件中本身隐藏着\n换行符; 32 #No.2 print语句本身会换行,所以呈现的效果是换了两行;
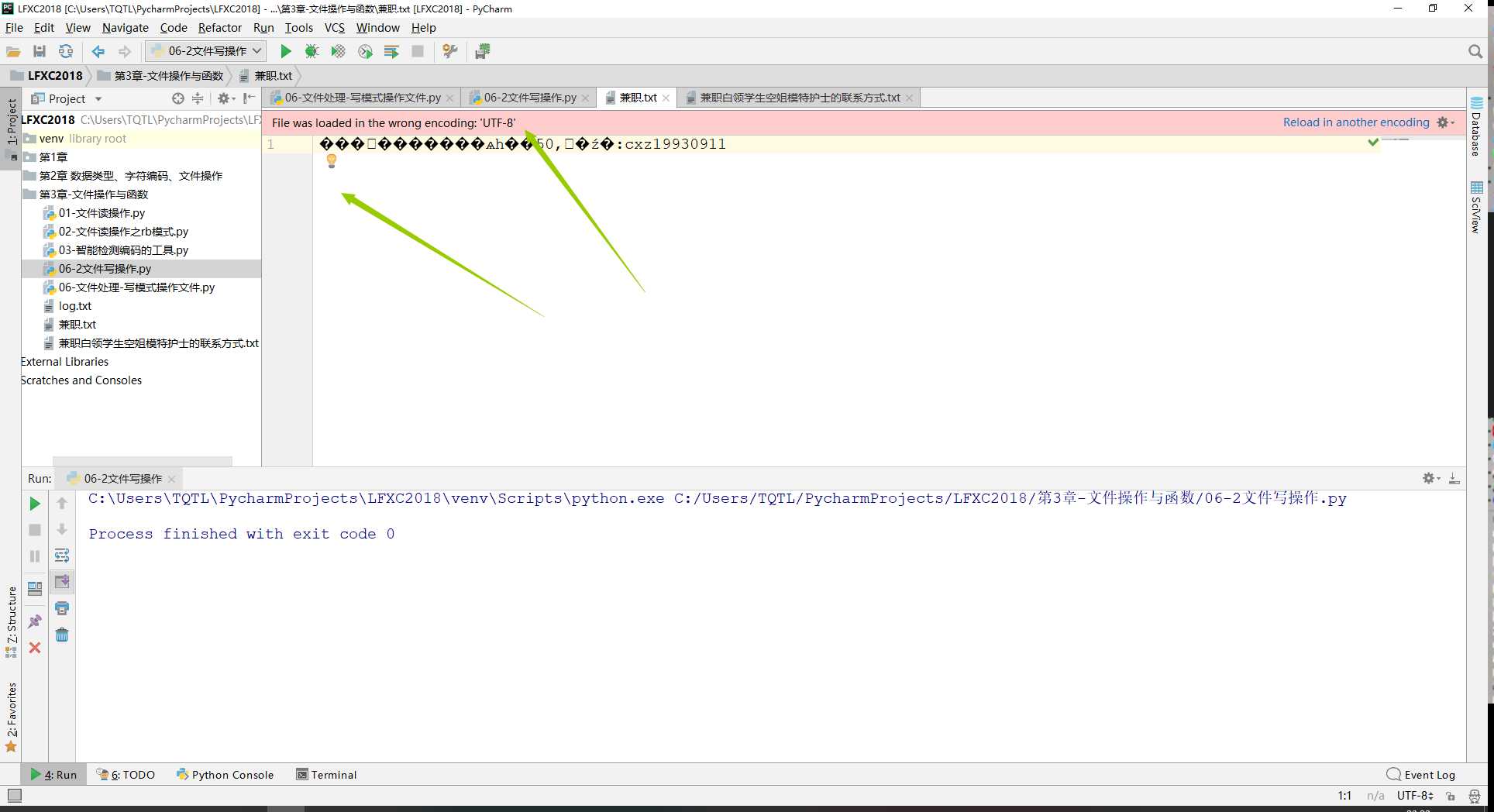
1 #写文件操作 2 file = open(file=‘兼职.txt‘,mode=‘w‘,encoding=‘utf-8‘) 3 file.write(‘北大本科美国留学一次50,微信号:cxz19930911‘) 4 file.close()
1 file = open(file=‘兼职write.txt‘,mode=‘wb‘) 2 file.write("路飞学城!".encode(‘gbk‘)) 3 file.close()#输出:路飞学城!
1 file = open(file=‘兼职write.txt‘,mode=‘wb‘) 2 file.write("原子二号!".encode(‘gbk‘)) 3 file.close()#输出:原子二号!
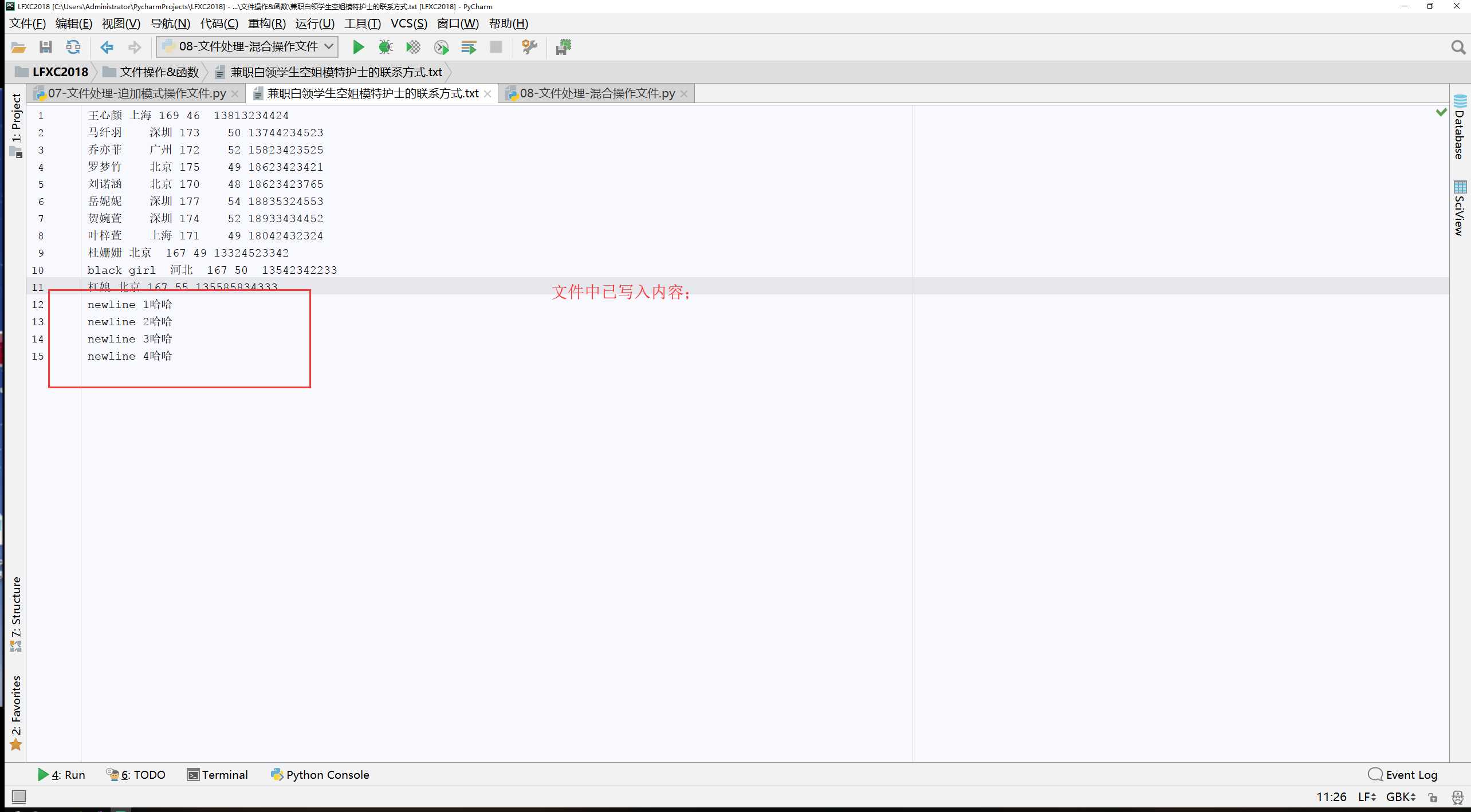
#!/usr/bin/env python # -*- coding:utf-8 -*- # __Author__:Administrator # Version:python3.6.5 # Date:2018/5/19 0019 18:20 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘ab‘) file.write(‘\n杠娘 北京 167 55 135585834333‘.encode(‘gbk‘)) file.close()
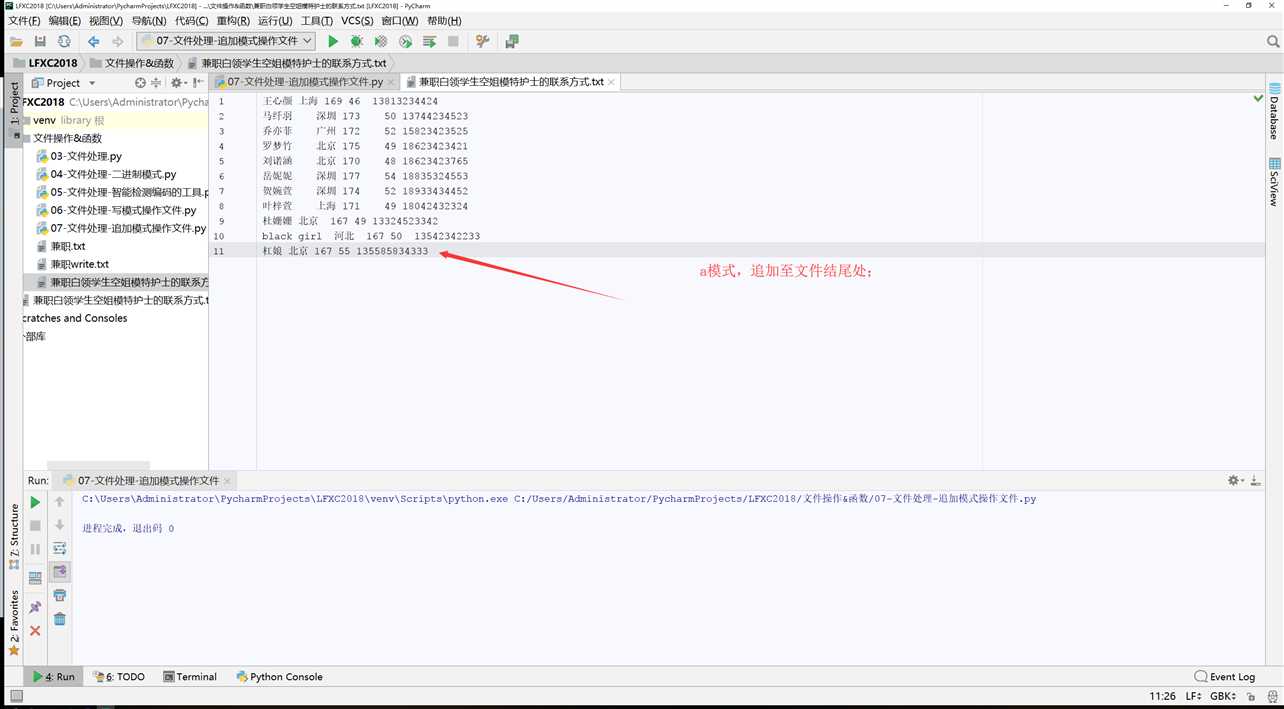
#!/usr/bin/env python # -*- coding:utf-8 -*- # __Author__:Administrator # Version:python3.6.5 # Date:2018/5/19 0019 18:28 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘r+‘,encoding=‘gbk‘) data = file.read() print("content",data) file.write("\nnewline 1哈哈") file.write("\nnewline 2哈哈") file.write("\nnewline 3哈哈") file.write("\nnewline 4哈哈") print("\nnew content",file.read()) file.close()
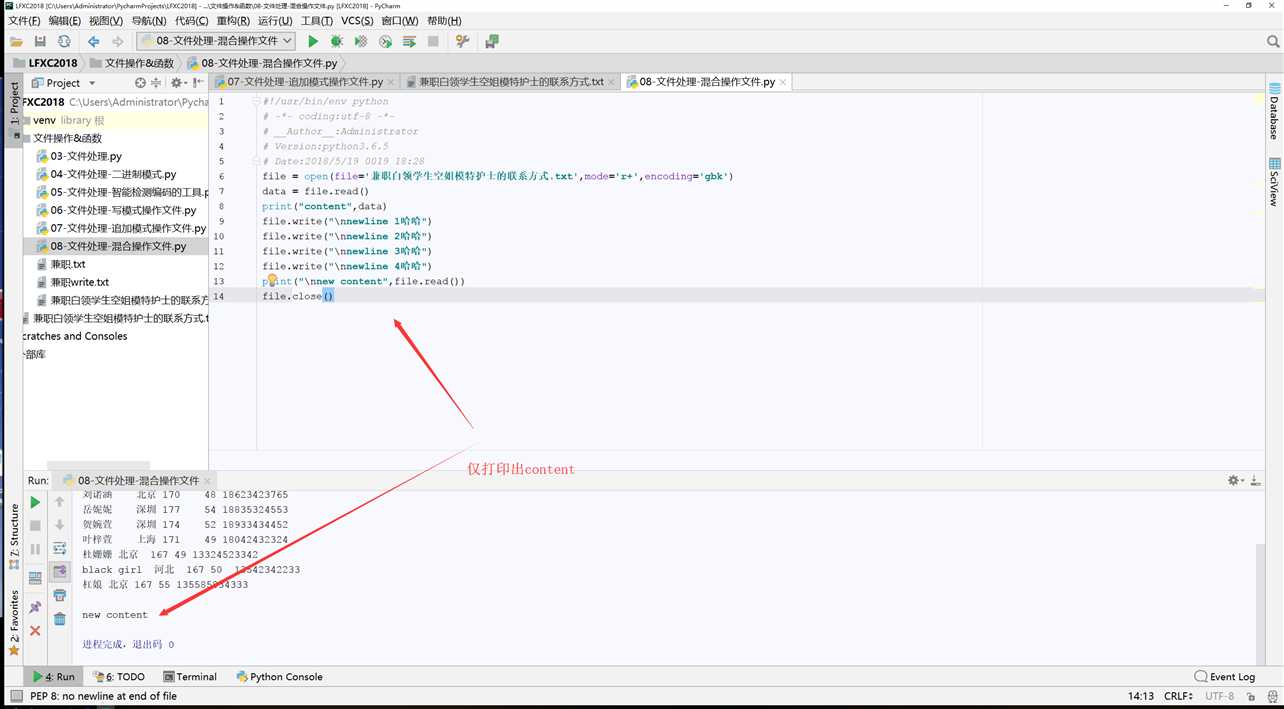
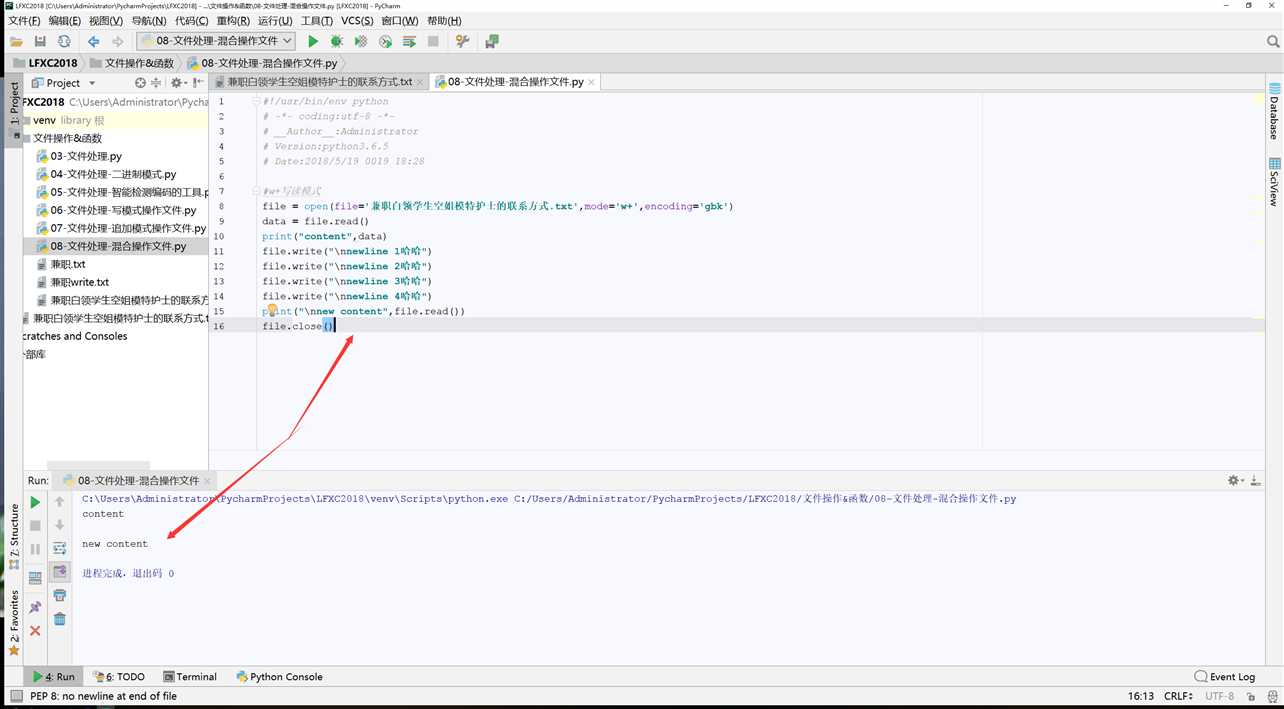
#!/usr/bin/env python # -*- coding:utf-8 -*- # __Author__:Administrator # Version:python3.6.5 # Date:2018/5/19 0019 18:28 #w+写读模式 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘w+‘,encoding=‘gbk‘) data = file.read() print("content",data) file.write("\nnewline 1哈哈") file.write("\nnewline 2哈哈") file.write("\nnewline 3哈哈") file.write("\nnewline 4哈哈") print("\nnew content",file.read()) file.close()
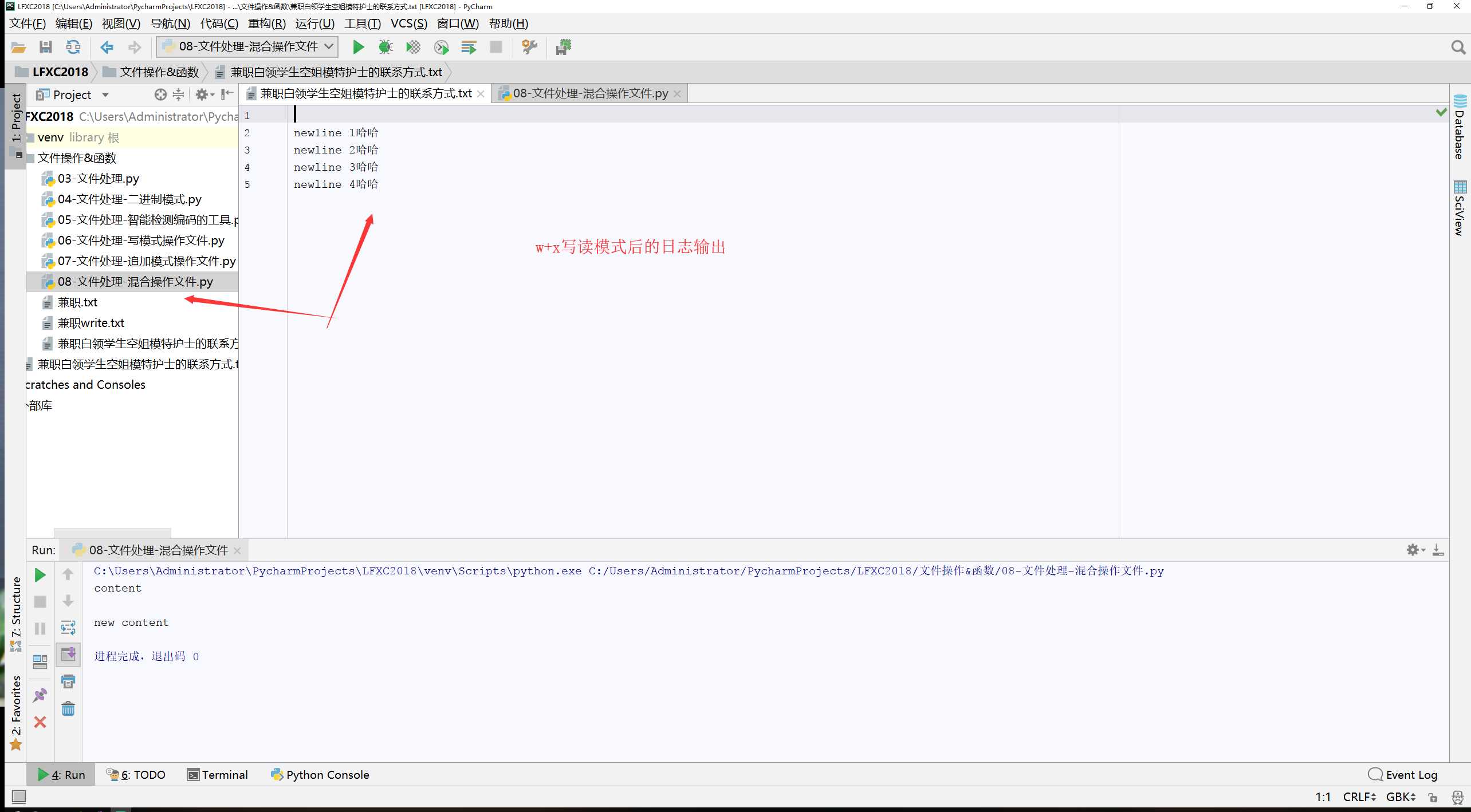
1、r+读写模式,即先读后写,相当于以“读”的模式打开,支持向后面追加内容至文件中;
2、w+写读模式,以写的模式打开,支持读取,我们知道,写模式是以创建的模式打开文件,会把之前的内容先覆盖掉,然后再写入,但可以读取到后续写入的内容,使用场景:几乎用不到;
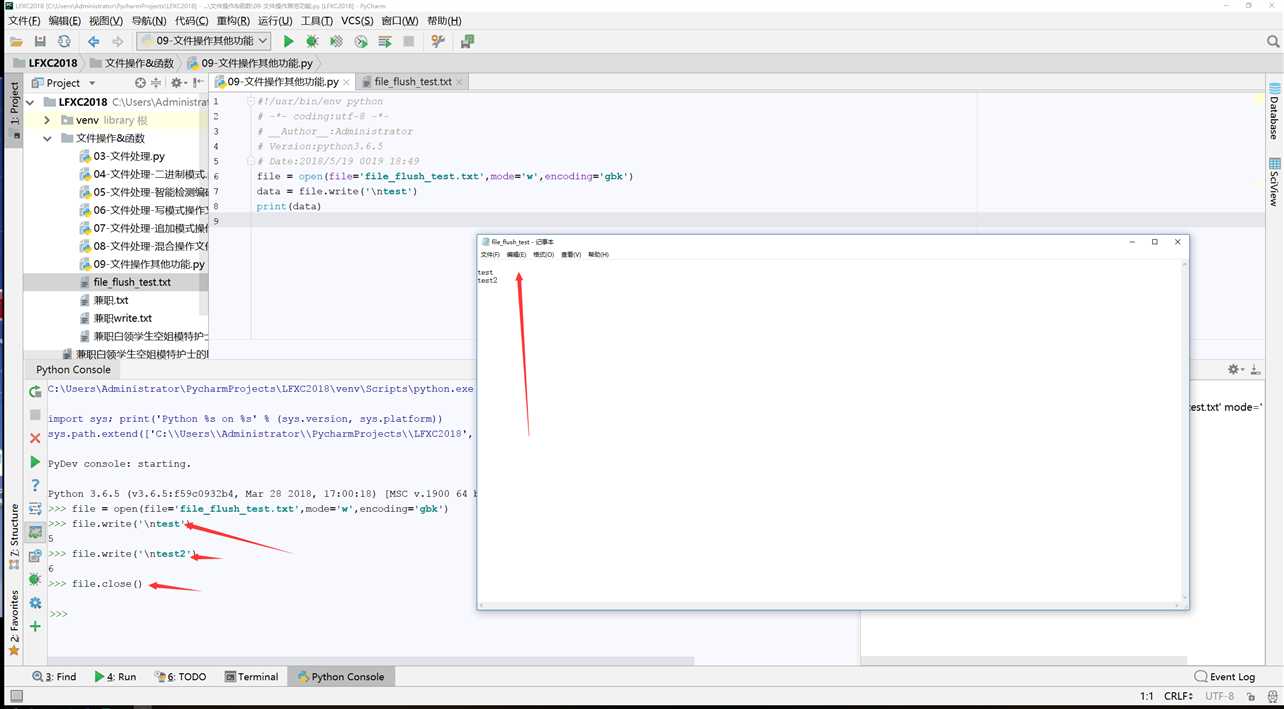
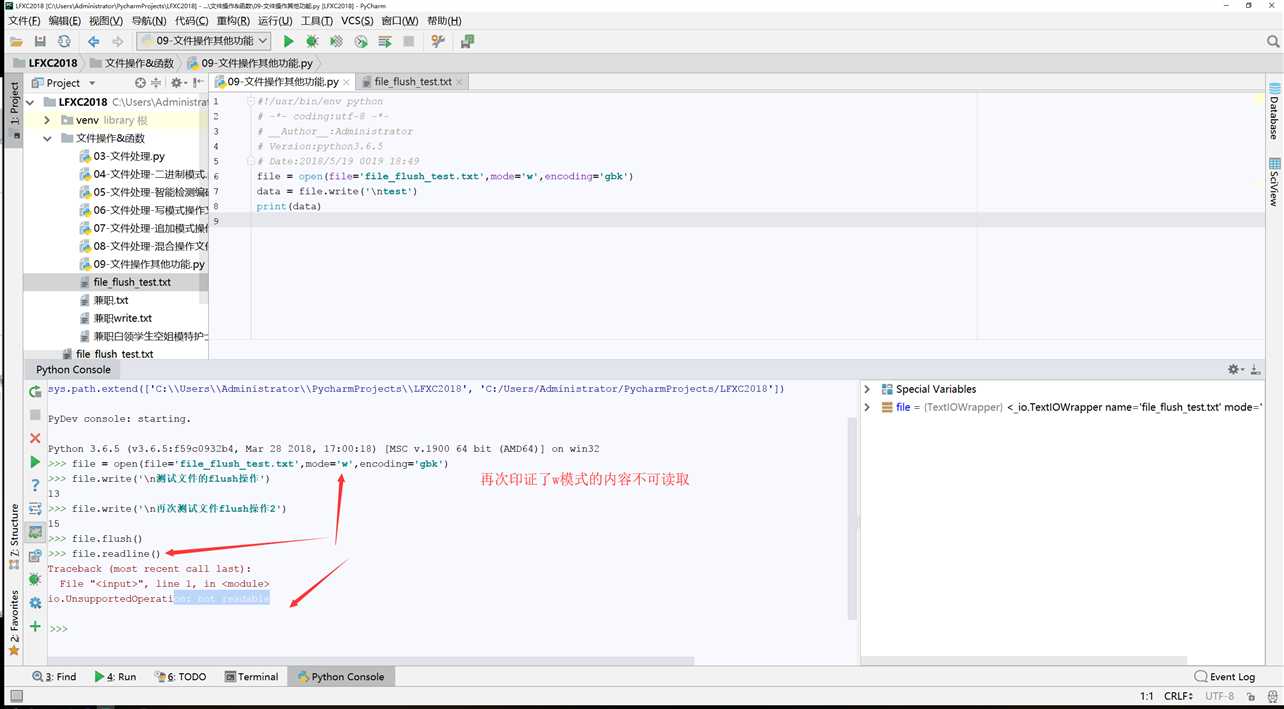
1 C:\Users\Administrator\PycharmProjects\LFXC2018\venv\Scripts\python.exe "C:\Program Files\JetBrains\PyCharm 2018.1.3\helpers\pydev\pydevconsole.py" 50524 50525 2 import sys; print(‘Python %s on %s‘ % (sys.version, sys.platform)) 3 sys.path.extend([‘C:\\Users\\Administrator\\PycharmProjects\\LFXC2018‘, ‘C:/Users/Administrator/PycharmProjects/LFXC2018‘]) 4 PyDev console: starting. 5 Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32 6 file = open(file=‘file_flush_test.txt‘,mode=‘w‘,encoding=‘gbk‘) 7 file.write(‘\n测试文件的flush操作‘) 8 13 9 file.write(‘\n再次测试文件flush操作2‘) 10 15 11 file.flush()
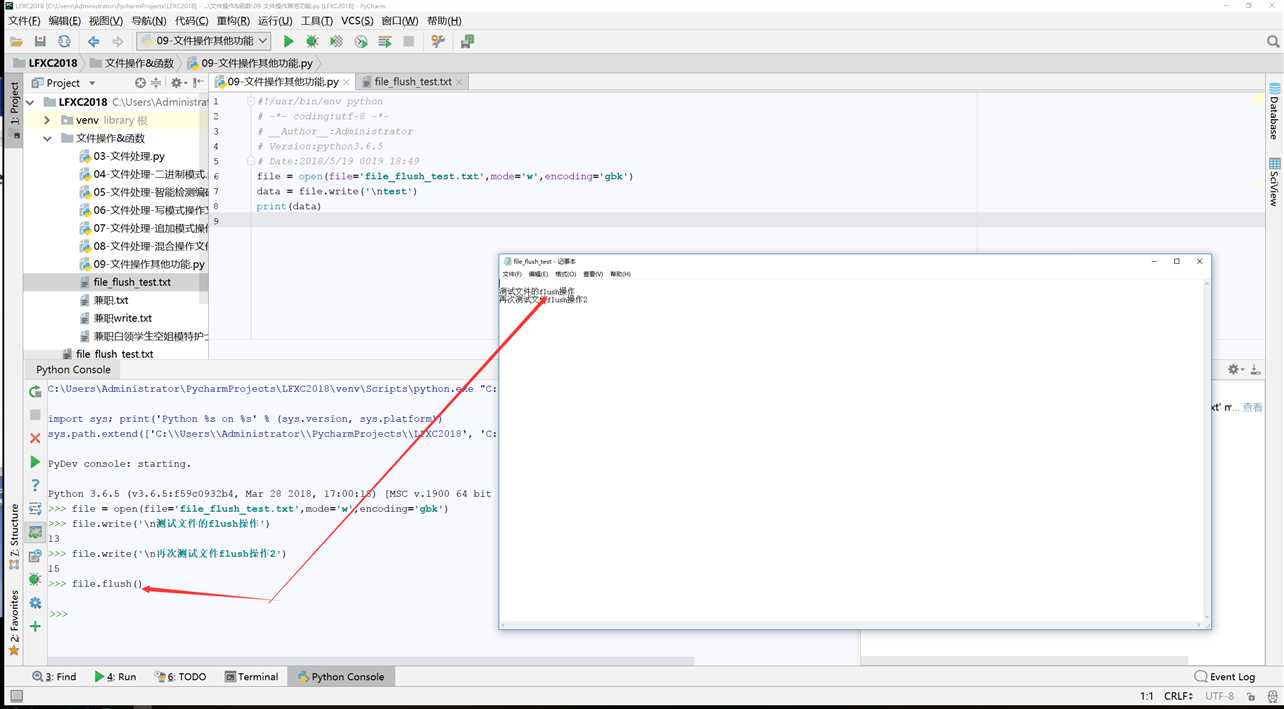
C:\Users\Administrator\PycharmProjects\LFXC2018\venv\Scripts\python.exe "C:\Program Files\JetBrains\PyCharm 2018.1.3\helpers\pydev\pydevconsole.py" 50583 50584 import sys; print(‘Python %s on %s‘ % (sys.version, sys.platform)) sys.path.extend([‘C:\\Users\\Administrator\\PycharmProjects\\LFXC2018‘, ‘C:/Users/Administrator/PycharmProjects/LFXC2018‘]) PyDev console: starting. Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32 file = open(file=‘file_flush_test.txt‘,mode=‘w‘,encoding=‘gbk‘) file.write(‘\n测试文件的flush操作‘) 13 file.write(‘\n再次测试文件flush操作2‘) 15 file.flush() file.readable() False
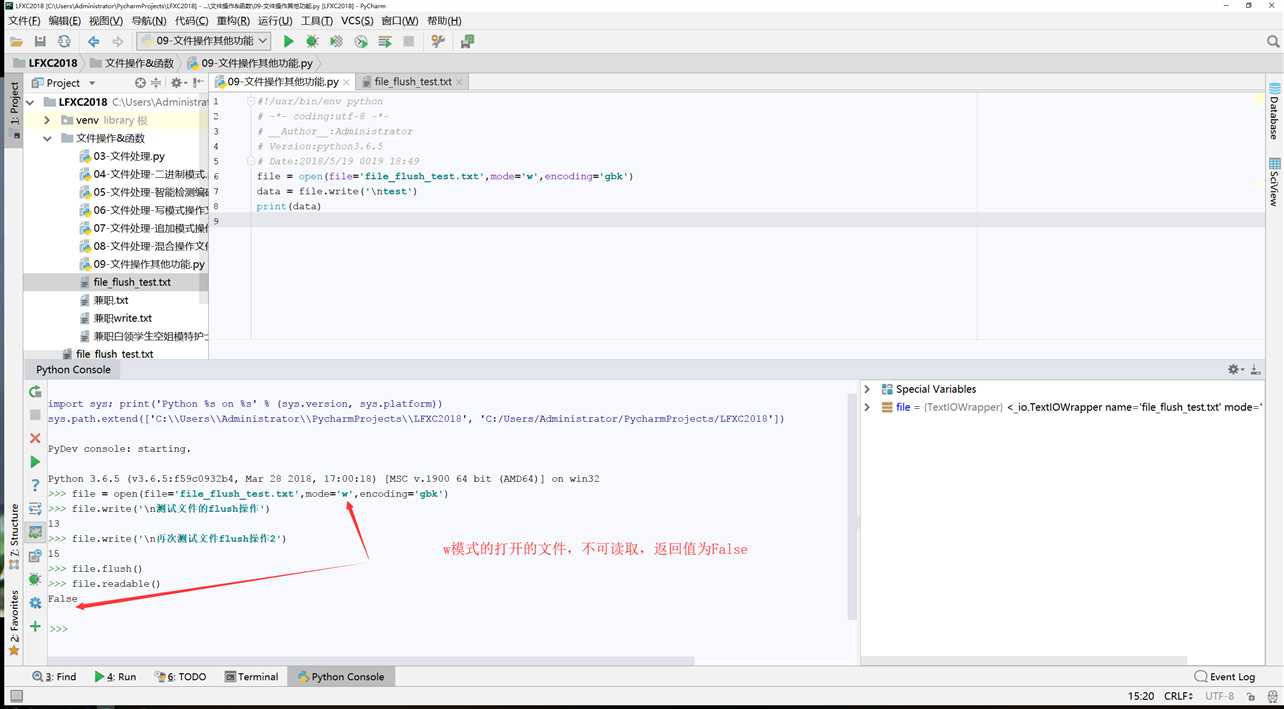
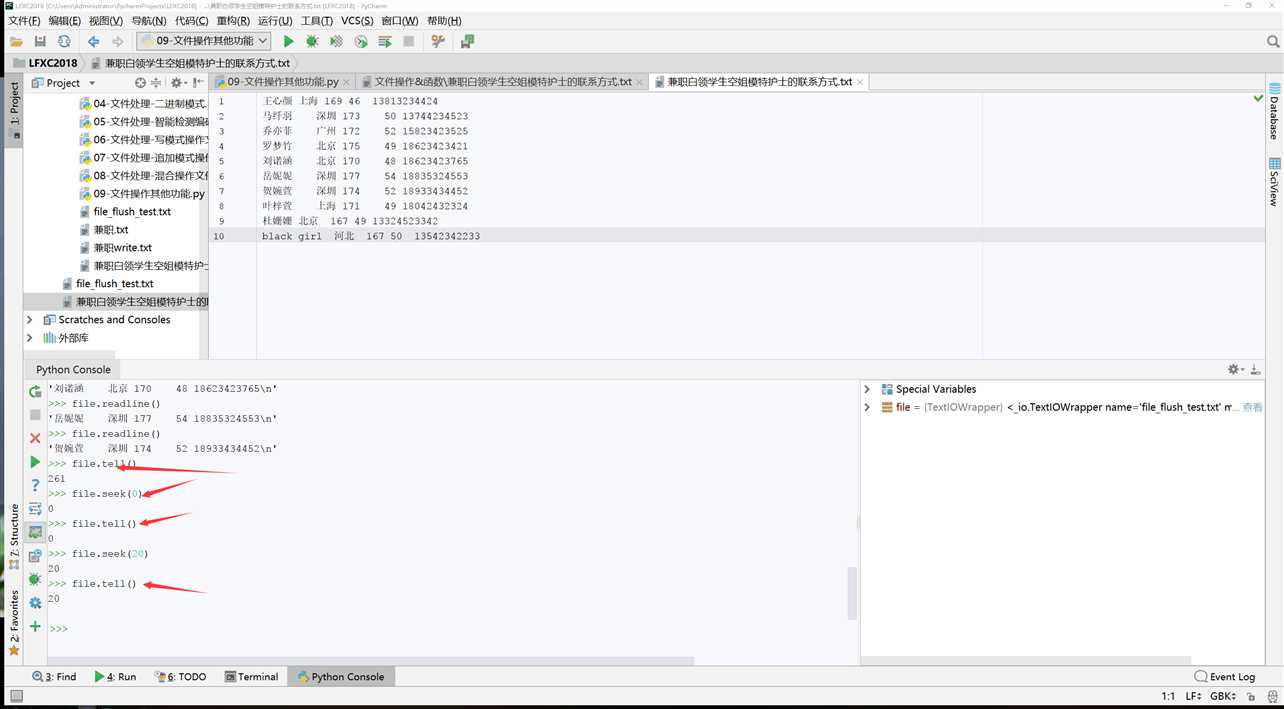
seek方法找到的是字符吗?
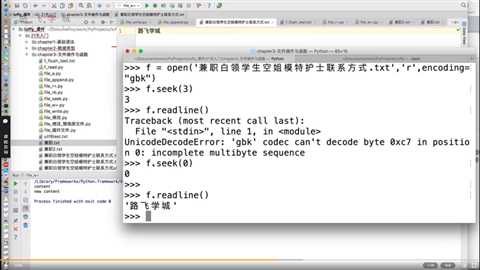
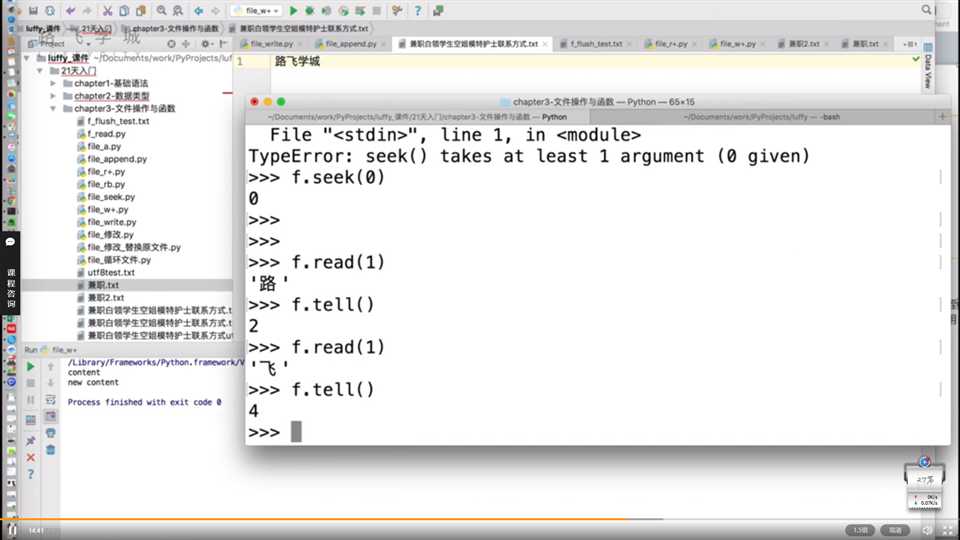
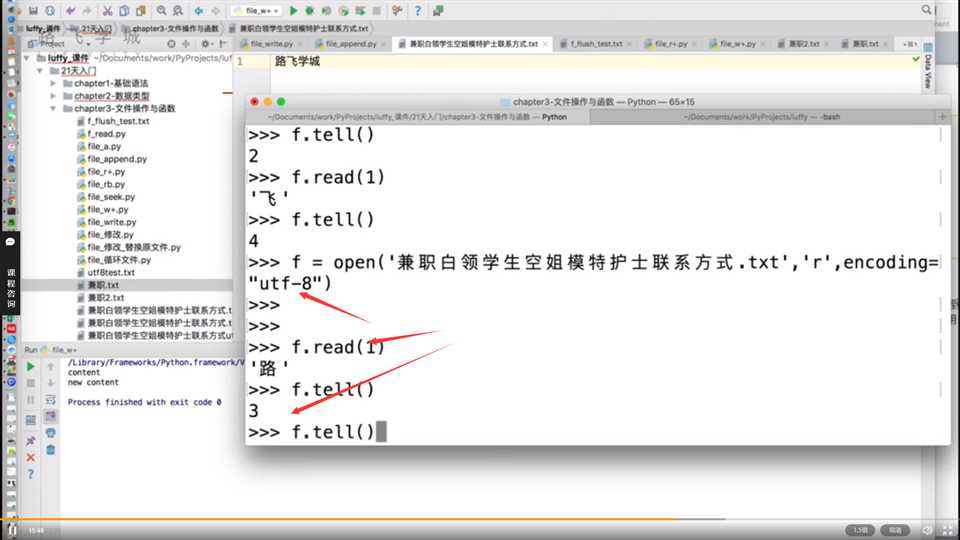
1、tell与seek方法是按照字节来读取内容的,而read是按照字符;
2、具体内容的展示,与编码格式有关,比如gbk2个字节,utf-83个字节(中文情况下);
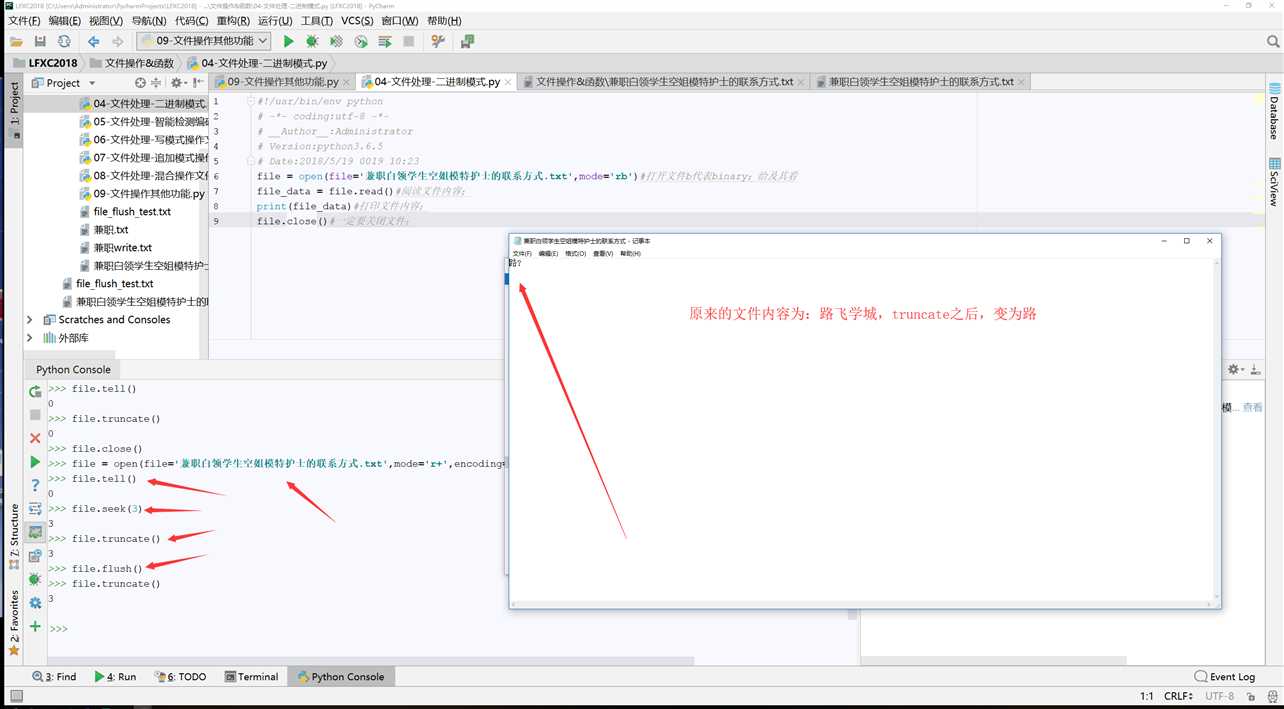
#!/usr/bin/env python # -*- coding:utf-8 -*- # __Author__:Administrator # Version:python3.6.5 # Date:2018/5/19 0019 19:32 file = open(file=‘兼职白领学生空姐模特护士的联系方式.txt‘,mode=‘r+‘,encoding=‘utf-8‘) file.seek(10) file.write("[路飞学城]luffycity") file.close()
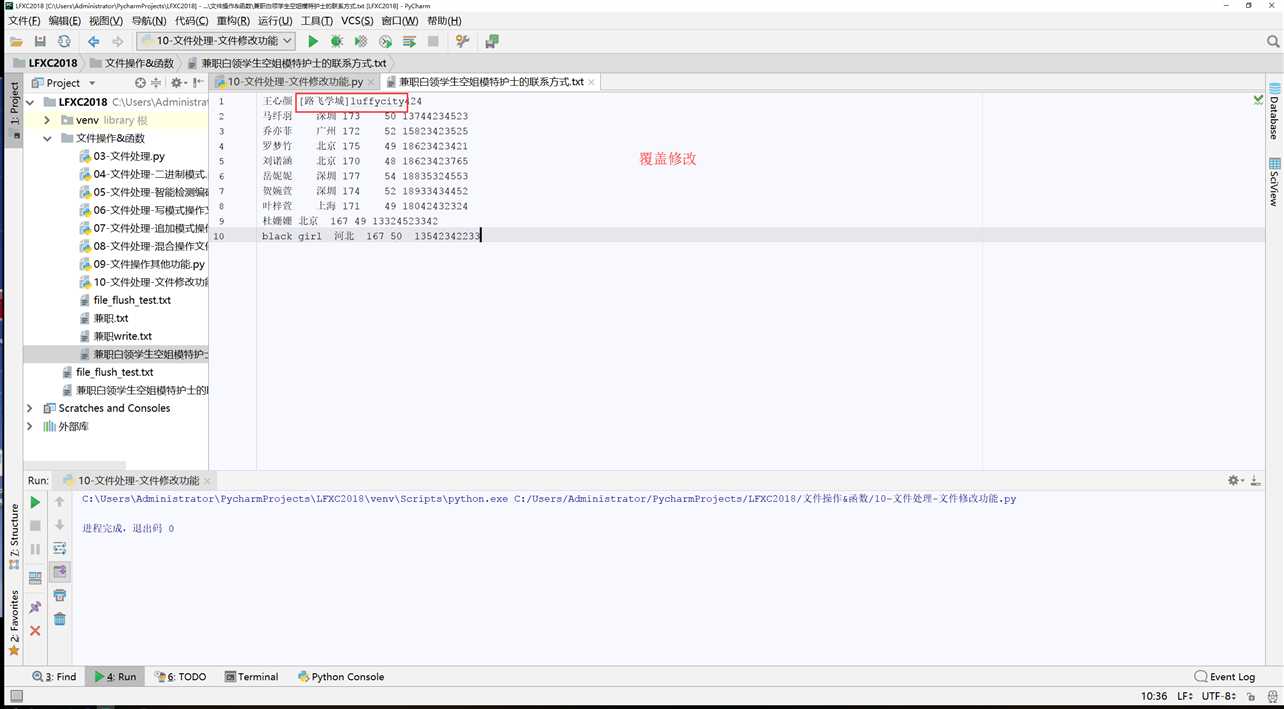
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # __Author__:Administrator 4 # Version:python3.6.5 5 # Date:2018/5/19 0019 21:29 6 import os 7 file_name = "兼职白领学生空姐模特护士的联系方式.txt" 8 file_new_name = "%s.new"%file_name 9 old_str = "乔亦菲" 10 new_str = "杠娘" 11 file = open(file = file_name,mode=‘r‘,encoding=‘utf-8‘) 12 file_new = open(file = file_new_name,mode=‘w‘,encoding=‘utf-8‘) 13 #循环遍历整个文件; 14 for line in file:#定义临时变量line 15 if old_str in line: 16 line = line.replace(old_str,new_str) 17 file_new.write(line) 18 file.close() 19 file_new.close() 20 os.rename(file_new_name,‘123.txt‘)
王心颜 [路飞学城]luffycity424 马纤羽 深圳 173 50 13744234523 乔亦菲 广州 172 52 15823423525 罗梦竹 北京 175 49 18623423421 刘诺涵 北京 170 48 18623423765 岳妮妮 深圳 177 54 18835324553 贺婉萱 深圳 174 52 18933434452 叶梓萱 上海 171 49 18042432324 杜姗姗 北京 167 49 13324523342 black girl 河北 167 50 13542342233
写一个脚本,允许用户按以下方式执行时,即可以对指定文件内容进行全局替换;
`python your_script.py old_str new_str filename`
替换完毕后打印替换了多少处内容;
1、函数初识;




#!/usr/bin/env python # -*- coding:utf-8 -*- # __Author__:Administrator # Version:python3.6.5 # Date:2018/5/19 0019 22:45 def helloworld():#函数名sayhi print("Hello,I‘m TQTL.") print(helloworld)#直接打印是内存地址:<function sayhi at 0x0000020147E219D8> helloworld()#通过函数名进行调用; #函数可以带有参数 def sayhi(name): print("Hello",name) print("My name is black girl.") #sayhi()#TypeError: sayhi() missing 1 required positional argument: ‘name‘ 报错,缺少位置参数; sayhi(‘TQTL‘)#Hello TQTL #写一个计算两个数的乘方的程序; a,b = 5,3 c = a**b print(c)#125 #使用函数改造以上程序; def calc(x,y): res = x**y print(res) calc(2,10)#1024 calc(2,5)#32 #函数的特性: """ 较少重复代码,提升程序员的逼格儿; 使程序变得可拓展,引用函数的位置,修改一处即可完成扩展操作; 使程序变得容易维护,比如之前报警使用邮件,现在改为微信,修改一处即可; """
1、函数参数的作用;


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # __Author__:Administrator 4 # Version:python3.6.5 5 # Date:2018/5/19 0019 23:11 6 def stu_register(name,age,country,course):#形参 7 print("学生注册信息".center(30,‘-‘)) 8 print(name,age,country,course) 9 stu_register("王山炮",22,"CN","Python")#实参 10 stu_register("张叫春",21,"CN","Linux")#实参 11 stu_register("刘老根",25,"CN","Devops")#实参 12 print("两段程序的分割线".center(40,‘#‘)) 13 #def stu_register(name,age,country = "CN",course):#形参,SyntaxError: non-default argument follows default argument 14 def stu_register(name,age,course,country = "CN"):#形参 15 print("学生注册信息".center(30,‘-‘)) 16 print(name,age,course,country) 17 stu_register("王山炮",22,"Python")#不传实参 18 stu_register("张叫春",21,"Linux","JP")#传了其他的实参JP 19 stu_register("刘老根",25,"Devops","CN")#传了默认参数CN,
小结:默认参数必须放在位置参数之后;
标签:enc 分割线 帐号 lse 方式 ram script 文件名 help
原文地址:https://www.cnblogs.com/tqtl911/p/9037125.html
