标签:plain 视角 st算法 color sci 学习方法 imp ted pap
集成学习大致可分为两大类:Bagging和Boosting。Bagging一般使用强学习器,其个体学习器之间不存在强依赖关系,容易并行。Boosting则使用弱分类器,其个体学习器之间存在强依赖关系,是一种序列化方法。Bagging主要关注降低方差,而Boosting主要关注降低偏差。Boosting是一族算法,其主要目标为将弱学习器“提升”为强学习器,大部分Boosting算法都是根据前一个学习器的训练效果对样本分布进行调整,再根据新的样本分布训练下一个学习器,如此迭代M次,最后将一系列弱学习器组合成一个强学习器。而这些Boosting算法的不同点则主要体现在每轮样本分布的调整方式上。本系列文章先讨论Boosting的两大经典算法 —— AdaBoost和Gradient Boosting,再探讨近年来在各大数据科学比赛中大放异彩的XGBoost和LightGBM。
AdaBoost是一个具有里程碑意义的算法,因为其是第一个具有适应性的算法,即能适应弱学习器各自的训练误差率,这也是其名称的由来(Ada为Adaptive的简写)。
AdaBoost的具体流程为先对每个样本赋予相同的初始权重,每一轮学习器训练过后都会根据其表现对每个样本的权重进行调整,增加分错样本的权重,这样先前做错的样本在后续就能得到更多关注,按这样的过程重复训练出M个学习器,最后进行加权组合,如下图所示。

下图显示通过将简单学习器加权组合就能生成具有复杂边界的强学习器。
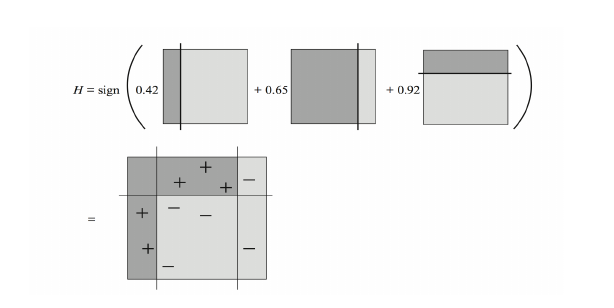
这里有两个关键问题:
这两个问题可由加法模型和指数损失函数推导出来。
由上图可以看出,AdaBoost最后得到的强学习器是由一系列的弱学习器的线性组合,此即加法模型:
? \[ f(x) = \sum_{m=1}^{M}\alpha_{m}G_{m}(x)\]
其中\(G_{m}(x)\)为基学习器,\(\alpha_{m}\)为系数。
在第m步,我们的目标是最小化一个指定的损失函数\(L(y,f(x))\),即 :
? \[\min\limits_{(\alpha_{m}\,,\,G_{m})}\sum\limits_{i=1}^{N}L(y_{i}, \,\sum\limits_{m=1}^{M}\alpha_{m}G_{m}(x_{i})) \qquad (1.1)\]
其中 \((x_{1},y_{1}),(x_{2},y_{2}),\cdots(x_{N},y_{N})\)为训练数据集。
这是个复杂的全局优化问题,通常我们使用其简化版,即假设在第m次迭代中,前m-1次的系数\(\alpha\)和基学习器\(G(x)\)都是固定的,则\(f_{m}(x) = f_{m-1}(x) + \alpha_{m}G_{m}(x)\),这样在第m步我们只需就当前的\(\alpha_{m}\)和\(G_{m}(x)\)最小化损失函数。
AdaBoost采用的损失函数为指数损失,形式如下:
? \[L(y,\,f(x)) = e^{-yf(x)} \qquad (1.2)\]
结合上文,我们现在的目标是在指数函数最小的情况下求得\(\alpha_{m}\)和\(G_{m}(x)\)。
? \[(\alpha_{m},G_{m}(x)) = \mathop{\arg\min}\limits_{(\alpha,G)}\sum\limits_{i=1}^{N}e^{-y_{i}f_{m}(x_{i})} = \mathop{\arg\min}\limits_{(\alpha,G)}\sum\limits_{i=1}^{N}e^{-y_{i}(f_{m-1}(x_{i}) + \alpha G(x_{i}))} \qquad (1.3)\]
设 \(w_{i}^{(m)} = e^{-y_{i}f_{m-1}(x_{i})}\),由于\(w_i^{(m)}\)不依赖于\(\alpha\)和\(G(x)\),所以可认为其是第m步训练之前赋予每个样本的权重。然而\(w_i^{(m)}\)依赖于\(f_{m-1}(x_i)\),所以每一轮迭代会改变。
于是式 (1.3) 变为:
? \[\sum\limits_{i=1}^{N}w_{i}^{(m)}e^{-y_i\alpha G(x_i)} = e^{-\alpha}\sum\limits_{y_{i}=G(x_{i})}w_{i}^{(m)} + e^{\alpha}\sum\limits_{y_i \neq G(x_i)}w_i^{(m)} \qquad\qquad (1.4)\]
?\[= (e^{\alpha} - e^{-\alpha})\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G(x_i)) + e^{-\alpha}\sum\limits_{i=1}^Nw_i^{(m)} \qquad\qquad\quad (1.5)\]
由上面几个式子可以得到AdaBoost算法的几个关键点:
(1) 基学习器\(G_m(x)\) :
求令式 (1.5) 最小的\(G_m(x)\)等价于令 \(\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G(x_i))\) 最小化的\(G_m(x)\),因此可认为每一轮基学习器都是通过最小化带权重误差得到。
(2) 下一轮样本权值\(w_i^{(m+1)}\) :
由 \(w_{i}^{(m+1)} = e^{-y_{i}f_{m}(x_{i})} = e^{-y_{i}(f_{m-1}(x_{i}) + \alpha G(x_{i}))} = e^{-y_if_{m-1}(x_i)}e^{-y_i\alpha_mG_m(x_i)} = w_i^{(m)}e^{-y_i\alpha_mG_m(x_i)}\)
可以看到对于\(\alpha_m>0\),若\(y_i = G_m(x_i)\),则\(w_i^{(m+1)} = w_i^{(m)}e^{-\alpha_m}\),表明前一轮被正确分类样本的权值会减小; 若\(y_i \neq G_m(x_i)\),则\(w_i^{(m+1)} = w_i^{(m)}e^{\alpha_m}\),表明前一轮误分类样本的权值会增大。
(3) 各基学习器的系数 \(\alpha_m\) :
设\(G_m(x)\)在训练集上的带权误差率为 \(\epsilon_m = \frac{\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G_m(x_i))}{\sum\limits_{i=1}^Nw_i^{(m)}}\) ,
式 (1.4) 对\(\alpha\) 求导并使导数为0: $-e^{-\alpha}\sum\limits_{y_{i}=G(x_{i})}w_{i}^{(m)} + e^{\alpha}\sum\limits_{y_i \neq G(x_i)}w_i^{(m)} = 0 $ ,
两边同乘以\(e^\alpha\),得 \(e^{2\alpha} = \frac{\sum\limits_{y_{i}=G(x_{i})}w_{i}^{(m)}}{\sum\limits_{y_{i} \neq G(x_{i})}w_{i}^{(m)}} = \frac{1-\epsilon_m}{\epsilon_m}\) \(\quad {\color{Red}{\Longrightarrow}} \quad\) \(\alpha_m = \frac{1}{2}ln\frac{1-\epsilon_m}{\epsilon_m}\)
可以看出,\(\epsilon_m?\)越小,最后得到的\(\alpha_m?\)就越大,表明在最后的线性组合中,准确率越高的基学习器会被赋予较大的系数。
在了解了\(G_m(x)\),\(w_i^{(m+1)}\)和\(\alpha_m\)的由来后,AdaBoost算法的整体流程也就呼之欲出了:
输入: 训练数据集 \(T = \left \{(x_1,y_1), (x_2,y_2), \cdots (x_N,y_N)\right \}\),\(y\in\left\{-1,+1 \right\}\),基学习器\(G_m(x)\),训练轮数M
- 初始化权值分布: \(w_i^{(1)} = \frac{1}{N}\:, \;\;\;\; i=1,2,3, \cdots N\)
for m=1 to M:
(a) 使用带有权值分布的训练集学习得到基学习器\(G_m(x)\):
? \[G_m(x) = \mathop{\arg\min}\limits_{G(x)}\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G(x_i))\] (b) 计算\(G_m(x)\)在训练集上的误差率:
? \[\epsilon_m = \frac{\sum\limits_{i=1}^Nw_i^{(m)}\mathbb{I}(y_i \neq G_m(x_i))}{\sum\limits_{i=1}^Nw_i^{(m)}}\] (c) 计算\(G_m(x)\)的系数: \(\alpha_m = \frac{1}{2}ln\frac{1-\epsilon_m}{\epsilon_m}\) (d) 更新样本权重分布: \(w_{i}^{(m+1)} = \frac{w_i^{(m)}e^{-y_i\alpha_mG_m(x_i)}}{Z^{(m)}}\; ,\qquad i=1,2,3\cdots N\)
其中\(Z^{(m)}\)是规范化因子,\(Z^{(m)} = \sum\limits_{i=1}^Nw^{(m)}_ie^{-y_i\alpha_mG_m(x_i)}\),以确保所有的\(w_i^{(m+1)}\)构成一个分布。输出最终模型: \(G(x) = sign\left[\sum\limits_{m=1}^M\alpha_mG_m(x) \right]\)
若将指数损失表示为期望值的形式:
? \[E(e^{-yf(x)}|x) = P(y=1|x)e^{-f(x)} + P(y=-1|x)e^{f(x)}\]
由于是最小化指数损失,则将上式求导并令其为0:
? \[\frac{\partial E(e^{-yf(x)}|x)}{\partial f(x)} = -P(y=1|x) e^{-f(x)} + P(y=-1|x)e^{f(x)} = 0\quad ,\]
\[f(x) = \frac12 log\frac{P(y=1|x)}{P(y=-1|x)},或写为 P(y=1|x) = \frac{1}{1+e^{-2f(x)}}\]
仔细看,这不就是logistic regression吗?二者只差系数\(\frac12\),因此每一轮最小化指数损失其实就是在训练一个logistic regression模型,以逼近对数几率 (log odds)。
于是,
\[\begin{equation} \begin{aligned} sign(f(x)) &= sign(\frac12 log\frac{P(y=1|x)}{P(y=-1|x)}) \\ & =\left\{\begin{matrix} 1 & \;\; P(y=1|x) > p(y=-1|x)\\ -1 & \;\; P(y=1|x) < P(y=-1|x) \end{matrix}\right. \\&=\mathop{\arg\max} \limits_{y \in\{-1,1\}}P(y|x) \end{aligned} \end{equation}\]
这意味着\(sign(f(x))\)达到了贝叶斯最优错误率,即对于每个样本\(x\)都选择后验概率最大的类别。若指数损失最小化,则分类错误率也将最小化。这说明指数损失函数是分类任务原本0-1损失函数的一致性替代函数。由于这个替代函数是单调连续可微函数,因此用它代替0-1损失函数作为优化目标。
上文推导出的AdaBoost算法被称为"Discrete AdaBoost",因为其各个基学习器\(G_m(x)\)的输出为{-1,1} 。如果将基学习器的输出改为一个类别概率,则产生了Real AdaBoost。Real AdaBoost通常在更少的轮数达到更高的精度,像scikit-learn中的AdaBoostClassifier就是默认优先使用Real AdaBoost (SAMME.R),不过Real AdaBoost中的基学习器必须支持概率估计。
推导与Discrete AdaBoost类似,仍最小化指数损失:
\[\begin{equation} \begin{aligned} E(e^{-yf_m(x)}|x) &= E(e^{-y(f_{m-1}(x) + G(x))}|x) \\ &=E(w \cdot e^{-yG(x)}|x) \\&=e^{-G(x)}P_w(y=1|x) + e^{G(x)}P_w(y=-1|x)\end{aligned} \end{equation}\]
对\(G(x)\)求导: \(G(x) = \frac12log\frac{P_w(y=1|x)}{P_w(y=-1|x)}\)
其中\(P_w(y=1|x)\)是权重为\(w\)下y=1的概率,注意这里的\(G(x)\)不是基学习器,而是基学习器的类别概率的一个对数转换。由此Real AdaBoost的算法流程如下:
- 初始化权重分布:\(w_i^{(1)} = \frac1N, \qquad i = 1,2 \cdots N\)
- for m=1 to M:
(a) 使用带权重分布的训练集训练基学习器,得到类别概率\(P_m(x) = P_w(y=1|x) \;\in [0,1]\)
(b) \(G_m(x) = \frac12 log\frac{P_m(x)}{1-P_m(x)} \;\in R\)
(c) 更新权重分布: \(w_i^{(m+1)} = \frac{w_i^{(m)}e^{-y_iG_m(x_i)}}{Z^{(m)}}\)- 输出最终模型:\(G(x) = sign\left[\sum\limits_{m=1}^MG_m(x)\right]\)
对每个基学习器乘以一个系数\(\nu\) (0 < \(\nu\) <1),使其对最终模型的贡献减小,从而防止学的太快产生过拟合。\(\nu\)又称学习率,即scikit-learn中的 learning rate。于是上文的加法模型就从:
? \[f_m(x) = f_{m-1}(x) + \alpha_m G_m(x)\]
变为:
? \[f_m(x) = f_{m-1}(x) + \nu \cdot \alpha_m G_m(x)\]
一般\(\nu\)要和迭代次数M结合起来使用,较小的\(\nu\)意味着需要较大的M。ESL中提到的策略是先将\(\nu\)设得很小 (\(\nu\) < 0.1),再通过early stopping选择M,不过现实中也常用cross-validation进行选择。
将数据集划分为训练集和测试集,在训练过程中不断检查在测试集上的表现,如果测试集上的准确率下降到一定阈值之下,则停止训练,选用当前的迭代次数M,这同样是防止过拟合的手段。
weight trimming不是正则化的方法,其主要目的是提高训练速度。在AdaBoost的每一轮基学习器训练过程中,只有小部分样本的权重较大,因而能产生较大的影响,而其他大部分权重小的样本则对训练影响甚微。Weight trimming的思想是每一轮迭代中删除那些低权重的样本,只用高权重样本进行训练。具体是设定一个阈值 (比如90%或99%),再将所有样本按权重排序,计算权重的累积和,累积和大于阈值的权重 (样本) 被舍弃,不会用于训练。注意每一轮训练完成后所有样本的权重依然会被重新计算,这意味着之前被舍弃的样本在之后的迭代中如果权重增加,可能会重新用于训练。
根据 [Friedman et al., 2000] 中的描述,weighting trimming可以提高计算效率,且不会牺牲准确率,下一篇中将通过实现来验证。
AdaBoost的原始论文 [Freund & Schapire, 1997] 并非使用了上文中的推导方法,而是基于PAC学习框架下进行解释的。上文的将AdaBoost视为 “加法模型 + 指数损失” 的观点,由斯坦福的几位统计系大牛 [Friedman et al., 2000] 提出,因而这一派也被称为“统计视角”。沿着这个路子,若将指数损失替换为其他损失函数并依此不断训练新学习器,则诞生了Gradient Boosting算法,是为下一篇的主题。
/
标签:plain 视角 st算法 color sci 学习方法 imp ted pap
原文地址:https://www.cnblogs.com/massquantity/p/9063033.html