标签:分数 sequence 转换 时间段 bre label 而不是 最大的 isp
A. Sequence to sequence model:机器翻译、语音识别。(1. Sutskever et. al., 2014. Sequence to sequence learning with neural networks. 2. Cho et. al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation.)
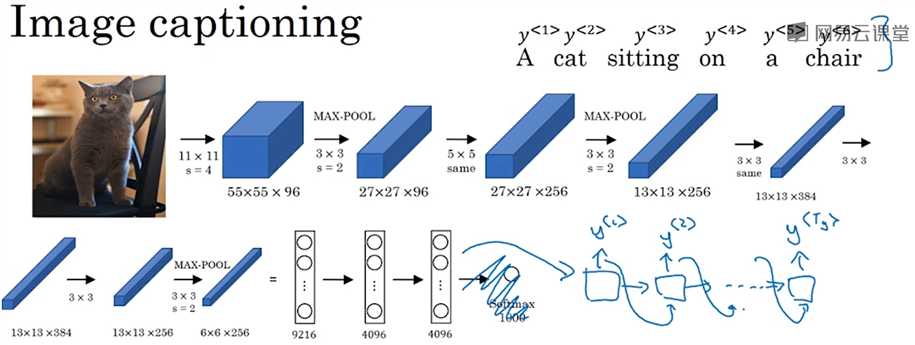
B. Image captioning:图片标注。(1. Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks. 2. Vinyals et. al., 2014. Show and tell: Neural image caption generator. 3. Karpathy and Fei Fei, 2014. Deep visual-semantic alignments for generating image descriptions.)。下图展示的是把AlexNet最后的softmax函数替换成一个RNN网络,这种情况下,CNN网络相当于是个encoder把图片编码成4096*1的向量,而RNN相当于是个decoder把4096*1的向量解码成一句描述图片的话。
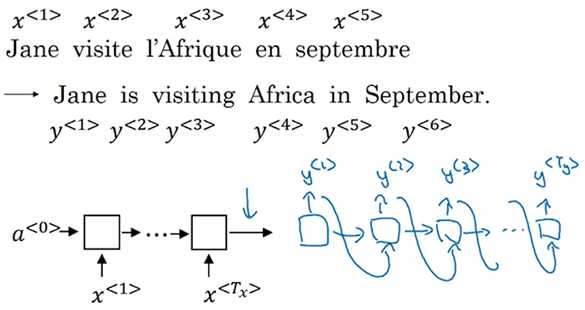
Andrew NG把机器翻译看成“条件语言模型(conditional language model)”。语言模型可以估计句子的可能性,也可以生成新的句子,Week 1 的课程中介绍了如何用RNN构建语言模型,$a^{<0>}$和$x^{<1>}$是0向量,$x^{<2>}=\hat{y^{<1>}}$,$x^{<3>}=\hat{y^{<2>}}$,以此类推。而机器翻译的decoder部分就是一个语言模型,只是这个语言模型的输入不再是0向量,而是对另一种语言的编码结果。所以机器翻译是在一种语言的句子已知的条件下求另一种语言的句子的可能性。对于同一个句子,机器翻译可能有不同的输出,我们要选择出可能性最大的哪一个。
为什么不用贪心搜索(greedy search)?即先选出最大概率的第一个单词,然后选出第一个单词已知的情况下最大概率的第二个单词,以此类推。这样做的效果不好,连续的局部最优没有导致全局最优。我们希望的是一次选出所有的单词,使得整体的概率最大化,而不是每次挑出一个单词让当前的概率最大化。
Beam search和贪心搜索的差别在于贪心搜索只找当前概率最大的那个单词,而Beam search则维护前B个概率最大的单词(如果B=1,则退化成贪心搜索),B被称为beam width。例如,第一步选出P(y<1>|x)最大的B个(这里假设B=3)单词是“in”、“Jane”、“September”,这里x表示需要被翻译的句子经过encoder的编码。第二步,对第一步选出的三个单词分别计算第二个单词的概率P(y<2>|x, y<1>),在当前的例子里即P(y<2>|x, "in")、P(y<2>|x, "Jane")和P(y<2>|x, "September"),然后计算P(y<1>, y<2>|x)=P(y<1>|x)P(y<2>|x, y<1>),选出这B*N中情况(N是词典的大小)下使得前两个单词概率最大的B个单词是“in September”、“Jane is”和"Jane visits",这意味着前一轮找到的“September”被舍弃了。第三步,再根据前两步计算出的B种前两个单词的情况计算第三个单词,选出前三个单词概率最大的B个单词,以此类推。事实证明,Beam search的结果比贪心搜索好很多。
Beam search优化的目标函数如下图所示,为了数值上更稳定(不容易出现四舍五入的近似误差,或者说数值下溢)会对它取log。这里有个问题是算法会倾向于选择单词更少的句子,原因是概率小于1,越乘越小。解决的方式是用句子的单词数量对句子做归一化,除以$Ty^\alpha$,如果α=0意味着完全没有做归一化,如果α=1意味着完全做归一化,一般取α=0.7。

如何选取Beam width?这是一个超参数,B越大,结果越好,计算量越大越慢;B越小,结果越差,计算量越小越快。一般产品系统会设成10,对于产品系统来说100就有点大了。但学界为了得到最好的效果,也会设成1000甚至3000。Beam search和BFS(Breadth First Search)、DFS(Depth First Search)的差别在于Beam search计算更快,但不能保证一定能得到准确的最大值,而BFS、DFS是很精确地找到最大值。
本小节讲误差分析,误差分析的目的是帮助开发者集中精力做项目中最有用的工作,在这里就是搞清楚到底是beam search出了问题(由于beam search是启发式搜索算法,并不总是输出可能性最大的句子,可能因为B设置的不够大而导致结果不理想)还是RNN模型出了问题。具体做法是,列出每一条算法出错的结果$\hat{y}$和对应的标准答案$y^*$,对每一条用RNN计算$P(y^*|x)$和$P(\hat{y}|x)$。如果$P(y^*|x)>P(\hat{y}|x)$,这符合我们的预期,标准答案的概率当然更大,这说明RNN没问题,beam search出错了;如果$P(y^*|x)\le P(\hat{y}|x)$,说明是RNN出错了。统计所有的错误原因,只有大部分错误源于beam search的情况才值得花费努力增大beam width B;如果错误源于RNN,则可以对RNN进行更深层次的分析,看是需要增加正则项还是获得更多的训练数据,或者尝试新的网络架构。
机器翻译的一大难题是对于同一句话可以有好多种挺不错的翻译方式(或者说,不是只有一个解,而是有多解),这种情况下如何评估一个机器系统呢?Bleu (Bilingual evaluation understudy,双语评估替补,这里替补的意思是正常评估一个机器翻译系统会请专门的人类评估员,而Bleu可以自动评估机器翻译系统,是这些人类评估员的替补) 是一种自动判定机器翻译好坏的方法(Papineni et. al., 2002. Bleu: a method for automatic evaluation of machine translation.),机器翻译的结果只要接近任意一个标准答案,Bleu分数就会很高。
Bleu的基本想法是查看机器翻译结果的每个单词是否出现在标准答案中,比如一个翻译结果有7个单词,每个单词都出现在了标准答案1或者标准答案2中,则precision就是7/7,但这样做的问题是如果7个单词全部是“the”,这样完全没有意义的话也能得到很高的分数。所以modified precision只考虑几个标准答案中“the”出现的最多的次数,比如在标准答案1中“the”出现2次,在标准答案2中出现1次,则modified precision是2/7。
更进一步,上一段的描述只统计了每一个单词(unigram),也可以统计每连续两个单词(bigrams),也可以每连续三个的单词(trigrams),甚至每连续n个单词(n-grams)。下图展示了bigrams的Bleu score的求法,P2=4/6。如果机器翻译的结果和任意一个标准答案一模一样,则对于所有n,Pn=1。实际使用的时候,会对不同的n取平均值并做些许调整,称为combined Bleu score:$BPexp(\frac{1}{4}\sum_{n=1}^{4}P_n)$,其中$BP$是对太短的句子的惩罚因子(因为短的句子更倾向于得到较高的Bleu分数),如果标准答案的长度是r,机器翻译的长度是c,则c>r时,$BP=1$;c≤r时,$BP=exp(1-r/c)$。

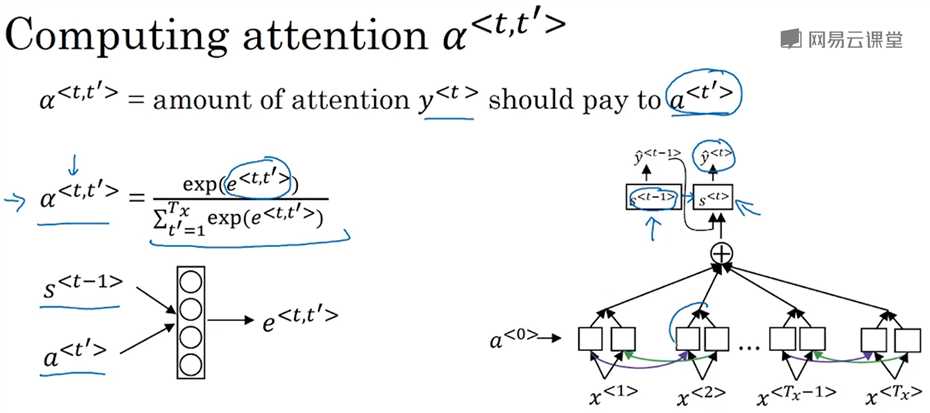
注意力模型(Bahdanau et.al., 2014. Neural machine translation by jointly learning to align and translate.)已经是深度学习中最重要的思想之一,源于机器翻译,但已也广泛应用于其他领域。之前的课程中都是利用encoder-decoder架构的网络来做机器翻译,一个RNN把原句编码,另一个RNN解码成翻译的结果。这样的做法对于不长的句子表现还不错,对于很长的句子(例如超过30或者40个单词)表现就会变差(可以看成是神经网络对句子的记忆能力是有限的)。注意力模型更像人类翻译,一次只翻译句子的一部分,不用先读完全部句子,所以对于长句也有很好的表现。下图是一个双向RNN网络,这里不是直接根据a和x得到y,而是设置了注意力权重α<t,t‘>,表示在生成第t个翻译结果的单词时应该花多少注意力在第t‘个原句的单词上,这可以使得翻译时只关注局部窗口内的单词,根据若干个注意力权重可以计算出上下文c,然后根据c再计算出机器翻译的结果。
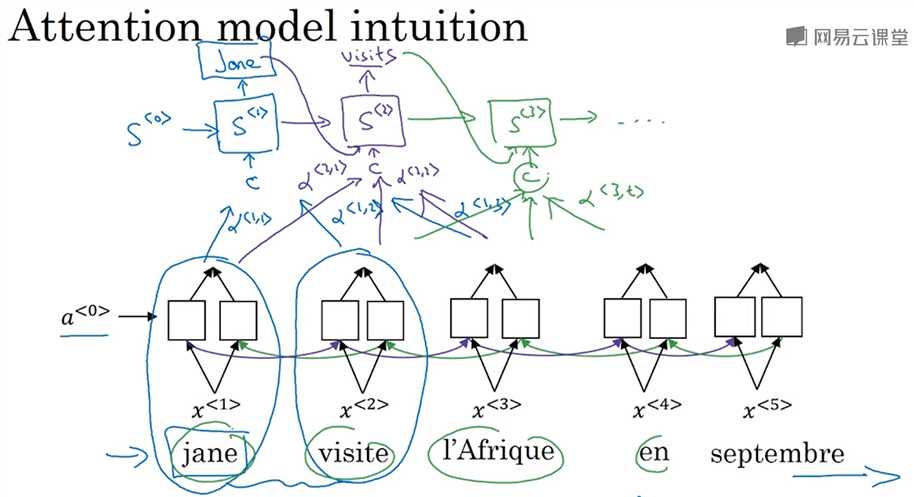
跟上一节类似,下图展示了一个attention model,底下是双向RNN模型,根据权重α<t,t‘>和a<t>得到c<t>,从c<t>得到y<t>是一个典型的RNN模型。
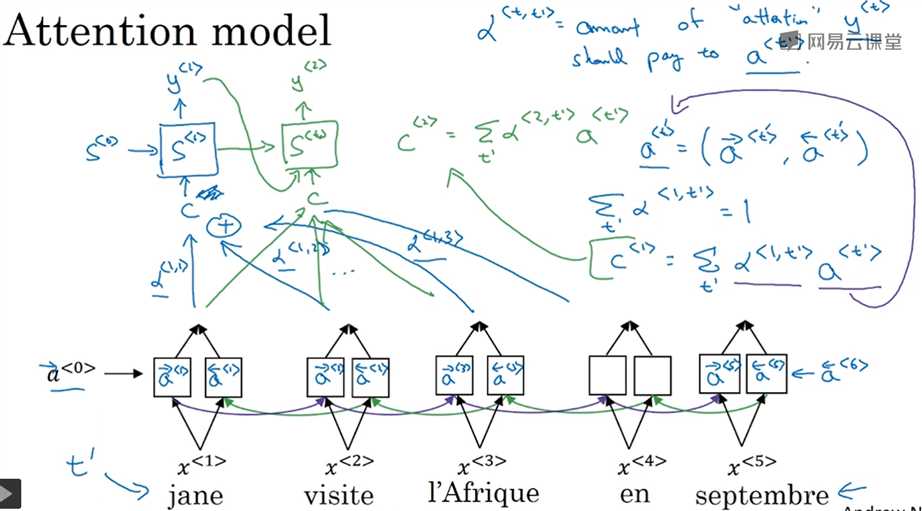
如何计算α<t,t‘>呢?是对另一个量e<t,t‘>的softmax函数,而e<t,t‘>是用一个输入为s<t-1>和a<t‘>的非常小型的神经网络得到的。
Attention model也被用于image captioning(Xu et. al., 2015. Show, attend and tell: Neural image caption generation with visual attention)。
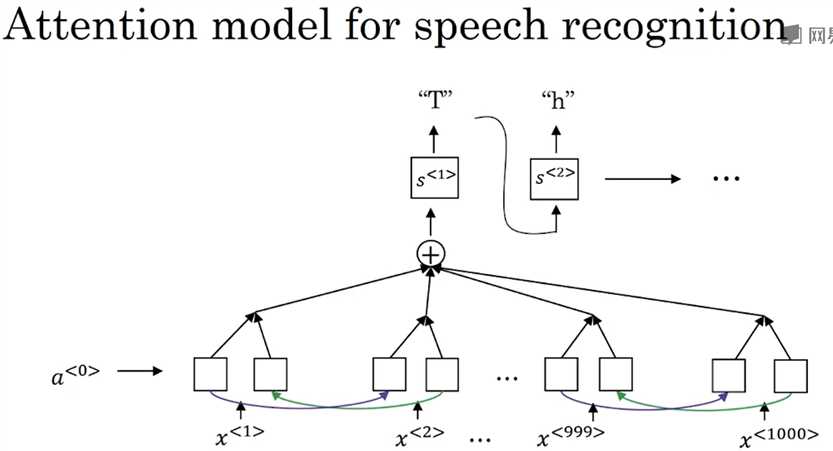
语音识别是典型的Sequence-to-sequence模型,输入是一段音频,输出是文字。传统做法是把音频转换成phoneme(音位),而使用深度学习的端到端训练之后就不需要音位的转换了。训练集一般会用长达300小时的文本音频数据,学术圈可能用长达3000小时,现在最好的系统已经训练了超过100000小时数据。
前一节讲的attention model就可以用在语音识别里。
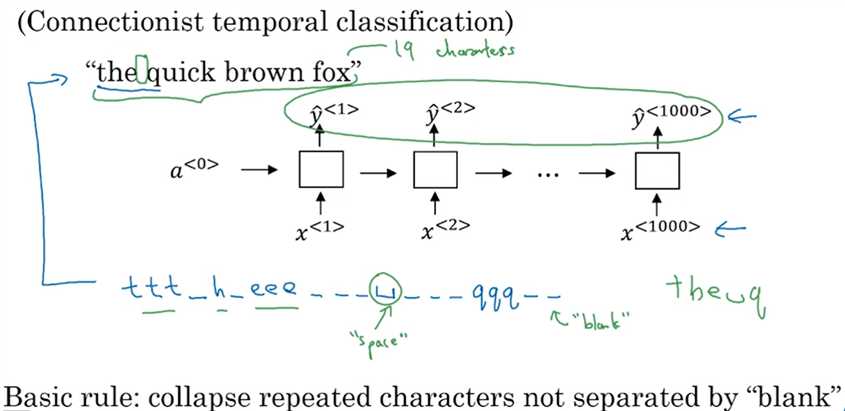
另一种效果也不错的方法是用CTC (Connectionist temporal classification)损失函数来做语音识别(Grayes et. al., 2006. Connetionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks)。这里使用的神经网络中输入x和输出y的数量是一样的,但在语音识别中输入的时间步数量要比输出的时间步的数量大得多,比如对于一段10秒的音频,音频特征100Hz采样,则输入的时间步数量为1000,但输出不会有1000个字符。怎么办呢?CTC损失函数允许“ttt_h_eee___”类似的输出。
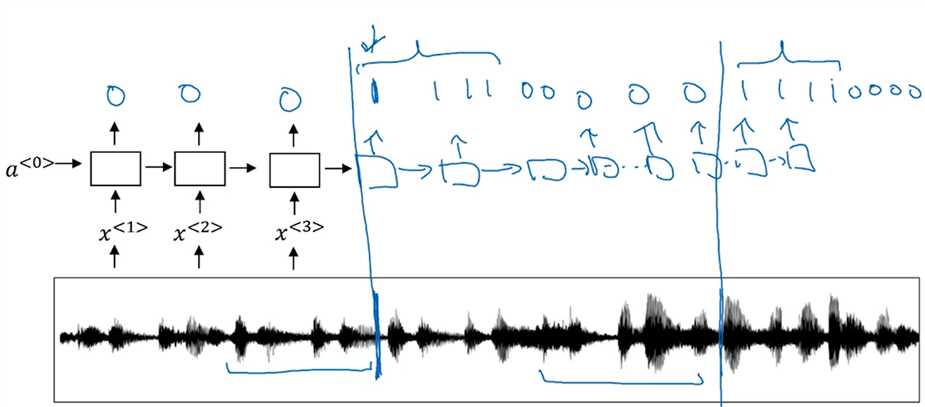
本节讨论的是如何唤醒设备,比如“Alexa”、“Hey Siri”、“Okay Google”等。学术圈对于trigger word detection最好的算法是什么还没有统一的看法,这还处于发展阶段。下面是个如何贴标签的例子,训练集中,“Alexa”这样的唤醒词之前的目标标签都设为0,"Alexa"之后的设为1,之后又变成0,等下一次“Alexa”。这样的做法效果还不错,但有个缺点是,训练集很不平衡,或者说有太多的0,很少的1。有一个改进的方法是听到"Alexa"之后多次输出1,或者说在固定的一个时间段内都输出1,这样可以让训练集平衡一点,更容易训练。
deeplearning.ai 序列模型 Week 3 Sequence models & Attention mechanism
标签:分数 sequence 转换 时间段 bre label 而不是 最大的 isp
原文地址:https://www.cnblogs.com/zonghaochen/p/8994313.html