标签:read 工作站 就是 并行执行 uda 依赖 img 时钟频率 pipeline
今天在使用阿里云的时候,无意间看到了有GPU服务器,于是对它做了一个大概的了解。

GPU是Graphics Processing Unit的缩写,翻译成中文就是图形处理器。是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器。GPU是专为执行复杂的数学和几何计算而设计的,这些计算是图形渲染所必需的。
从定义看GPU最初是做图像处理工作的,但是从阿里云的介绍看,由于在浮点运算、并行计算方面出色能力,现在GPU的应用场景已经涵盖了深度学习,视频处理,科学计算,图形可视化等。
传统的中央处理器(CPU,Central Processing Unit) 内部结构异常复杂,主要是因为其需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。
GPU可以在无需中断的纯净环境下,处理类型高度统一的、相互无依赖的大规模数据。注意啊,这里是类型高度统一,相互无依赖,这样就保证了,GPU的结构可以非常简单,逻辑判断很少,并且由于无依赖可以有几千个核并行计算。
CPU和GPU就呈现出非常不同的架构(如图):
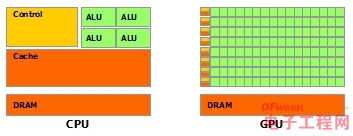
绿色的是计算单元,橙红色的是存储单元,橙黄色的是控制单元。可以看到,GPU几乎全是计算单元,而控制单元和存储单元很少,几乎没有cache。
再来对比看看CPU和GPU的设计理念:
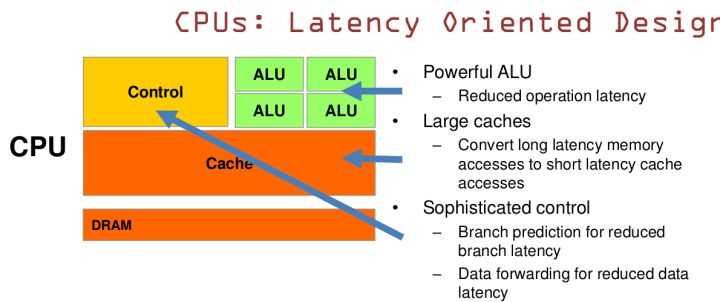
CPU基于低延时设计。
它有非常强大ALU,能够在很短时钟频率内完成计算。
大容量的缓存,可以保存数据,如果用到该数据直接读取缓存即可。
复杂的逻辑控制单元,分支预测可以减少延迟。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。
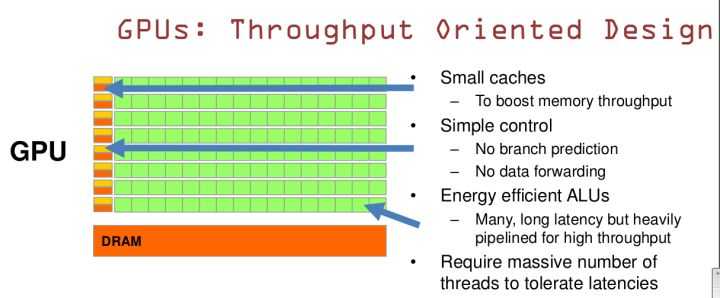
GPU基于大吞吐量设计。
非常小的缓存。非常简单的控制器。
缓存的设计不是为了使得后面访问前面的数据,而是为thread提高服务的。如果有很多线程需要访问同一个数据的话,缓存会合并这些访问,然后去访问DRAM(数据会保存在DRAM里,而不是在缓存里),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread。所以编程的时候需要充分利用多线程,并行计算的优点。
1)计算密集型;
2)易于并行执行的程序。
为了降低GPU程序的开发难度,NVIDIA推出了 CUDA(Compute Unified Device Architecture,统一计算设备架构)这一编程模型。
参考文档:
https://www.zhihu.com/question/19903344
https://baike.baidu.com/item/%E5%9B%BE%E5%BD%A2%E5%A4%84%E7%90%86%E5%99%A8/8694767?fr=aladdin&fromid=105524&fromtitle=gpu
https://blog.csdn.net/shuzfan/article/details/76602565
标签:read 工作站 就是 并行执行 uda 依赖 img 时钟频率 pipeline
原文地址:https://www.cnblogs.com/Andres/p/9064806.html