标签:线程 发放 打包 logging err alt 遍历 topic host
1.建立生产者发送数据
(1)配置zookeeper属性信息props
(2)通过 new KafkaProducer[KeyType,ValueType](props) 建立producer
(3)通过 new ProducerRecord[KeyType,ValueType](topic,key,value) 封装消息message
(4)通过 producer.send(message) 发送消息
package SparkDemo
import java.util
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
object KafkaProducer {
def main(args:Array[String]): Unit ={
if(args.length<4){
//参数
//<metadataBrokerList> broker地址
//<topic> topic名称
//<messagesPerSec> 每秒产生的消息
//<wordsPerMessage> 每条消息包括的单词数
System.err.println("Usage:KafkaProducer <metadataBrokerList> <topic> <messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers,topic,messagesPerSec,wordsPerMessage) = args
//zookeeper连接属性
val props = new util.HashMap[String,Object]();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")
//通过zookeeper建立kafka的producer
val producer = new KafkaProducer[String,String](props)
//通过producer发送一些消息
while(true){
(1 to messagesPerSec.toInt).foreach{//遍历[1, messagesPerSec.toInt]
messageNum =>
val str = (1 to wordsPerMessage.toInt).map(
x => scala.util.Random.nextInt(10).toString
).mkString(" ")//连成字符串用空格隔开
println(str)
//注意,我们这里发送的消息都是以键值对的形式发送的
//需要把消息内容和topic封装到ProducerRecord中再发送
//我们这里的topic为外部的传参,消息的键值对为<null,str>
val message = new ProducerRecord[String,String](topic,null,str)
//发送消息
producer.send(message)
}
Thread.sleep(1000)//休眠一秒钟
}
}
}
我们把程序打包好,提交到spark集群中执行
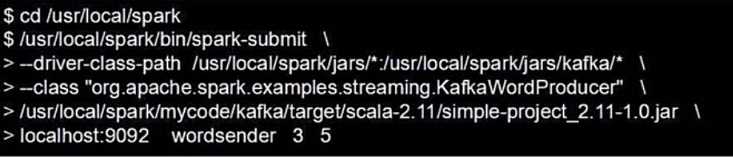
最后四个为我们要传入的程序参数
我们定义在localhost:9092的名字为wordsender的topic会以每秒3条,每条5个单词往外发送数据
2.建立消费者消费数据
(1)建立sparkStream ssc
(2)配置zookeeper地址 zkQuorum
(3)设置topic所在组名 group
(4)将topic配置成 Map<topicName,numThreads> 的 topicMap<topic名称,所需线程数> 的形式
(5)通过 KafkaUtils.createStream(ssc,zkQuorum,group,topicMap) 建立sparkStream-kafka的流通道
(6)sparkStream处理
package SparkDemo
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaConsumer {
def main(args:Array[String]): Unit ={
//设置日志等级
StreamingLoggingExample.setStreamingLogLevels()
//建立spark流
val conf = new SparkConf().setAppName("KafkaConsumerDemo").setMaster("local")
val ssc = new StreamingContext(conf,Seconds(10))
//设置检查点
ssc.checkpoint("file:/// or hdfs:///")
//zookeeper
val zkQuorum = "localhost:2181" //zookeeper服务器地址
//topic所发放的组名
val group = "1" //topic 所在的组名,可以设置为任意名字
//topic配置
val topics = "wordsender" //topic 名称,可以为多个topic,多个之间用逗号隔开 “topic1,topic2”
//建立topicMap<topicName,numThreads.toInt> key为topic名称,value为所需要的线程数
val topicMap = topics.split(",").map((_,1)).toMap //numThreads.toInt为所需线程数
//建立spark流
val lineMap = KafkaUtils.createStream(ssc,zkQuorum,group,topicMap)
//处理spark流
val lines = lineMap.map(_._2)//上面传过来的数据为<null,string>,我们去后边的value
val pair = lines.flatMap(_.split(" ")).map((_,1))
val wordCount = pair.reduceByKey(_+_)
wordCount.print
//启动spark流
ssc.start()
ssc.awaitTermination()
}
}
然后我们将程序打包提交到集群上运行,就可以对上面我们建立的kafka生产的消息进行消费了。
【sparkStreaming】kafka作为数据源的生产和消费
标签:线程 发放 打包 logging err alt 遍历 topic host
原文地址:https://www.cnblogs.com/zzhangyuhang/p/9071161.html